




Elmojo
Members
-
Joined
-
Last visited
-
Update/resolution: Samsung replaced my faulty SSD under warranty. After replacing the drive, and moving my VMs and dockers back onto the cache, the machine is now fully back up and running. Thanks to everyone for the help! Issue resolved.
-
I feel like in the event of a total server meltdown, VM backups are the least of your issues, but fair enough. To be clear, I agree that backups are a good thing to have. I'm using URBackup, and I just used it 2 days ago to recover a failed VM that didn't survive a cache migration. I just wanted you to flesh out your claim a bit. I think a combination of snapshots and backups are even better, but for most people, snapshots alone are enough.
-
Give me an example of how they are different, in practical terms.
-
It is. Snapshots have been a thing for the past couple releases. You do read the changelogs, don't you?
-
I was able to fix the VM issue myself by restoring the image from a backup. I guess now I just need to pull the old (failing) cache drive and send it in for repair or replacement, then reverse the process once I receive the new one. I'll try to remember to update once that's done, in case any else runs into a similar issue in the future.
-
root@Tower:~# ls -lah /mnt/cache total 16K drwxrwxrwx 1 nobody users 0 Jun 9 14:55 ./ drwxr-xr-x 17 root root 340 Jun 9 16:00 ../ Gotcha. I figured there would be updates once 7.x was released. So this just leaves the issue of why I have (at least) one VM that didn't migrate. As best I can tell, it didn't pick up the new location of the disk image. I pointed it to the existing image in the new location (array), but now it says no boot device found, or similar. Is there any way to recover it? I sure hope so... EDIT: I recovered the VM using a URBackup image.
-
That link looks to be out of date, since as far as I can tell, there is no "prefer cache" option any longer. At least I haven't seen it. I've looked through all my docker settings, and as best as I can tell, they're all looking at /mnt/user/ not /mnt/cache, with the exception of one (Rustdesk, which I fixed). So why are all the container appdata folders getting recreated when the docker service restarts? It's baffling. Ok, I think I have it cleaned up. It appears that overnight the server sorted it self out and only the Rustdesk files were left on the cache this morning. I deleted those manually, so now there's nothing showing on the cache drive, although it does report that 537MB are in use. I assume that's just overhead, or are there hidden files I should be hunting down?
-
Well that sucks. Also, my VMs (some of them) are broken now. The disk image can't be read in the new location (array) so the machine won't boot. I have no idea what to do about this. One of these VMs runs my security cameras, so it's fairly urgent to get it running again...
-
Oh lordy, individually for each container?! And I guess I'll have to map them all back once I've replaced the cache drive? This really feels like something that should be done automatically when the share settings are changed... Attached... tower-diagnostics-20260609-0937.zip
-
So it appears that the mover was working, it just took a while. It has now moved everything off of cache, except for ONE of my VM folders. The VM manager is disabled, so obviously no VMs are running. Why will this one not move, or how can I find out why it's not? Can I move it manually? If so, how? I finally got it to move manually. Now, the lingering issue is that when I restart the docker and VM services, it recreates the appdata folder on the cache. I've confirmed that the appdata share is set to "array" only. How can I get all the docker containers to stop writing to the cache?
-
Thank you JorgeB! It seems that the first steps of manually stopping the docker and VM services is key. After doing that, mover is at least reporting as active. However, it's running very slooowwly. I mean like the transfer rates are in the KBs. O.o Should I just leave it and see what happens? I hate to have my server offline for so long, especially not knowing if this might be a multi-day process at these speeds.... EDIT: I have 725GB of data to move. At the currently reported speeds, this will be a process of weeks. Something has to change.
-
Yeah, that's why I'm so confused. I have it set as shown, but when I invoke the mover manually, nothing happens. No errors. I get the little unraid 'wave' icon for a moment, then it goes back to the previous screen, like it's done. It's always done this, so I just assumed that was normal behavior until the cache reached the threshold of fill for when it was supposed to 'spill over' onto the array. If not, then it's never worked correctly since day-one. How do I troubleshoot this, to figure out why the mover...isn't? lol
-
I'm super confused then. I've had it set that way since the beginning, and it's never moved anything from the cache to the array. I assumed it was because the cache hadn't reached the selected fill level. That also means that the advice given above by Vvei_61: "Set the Use Cache option to "No" or "Prefer Array" on your shares, then run the mover. Everything will transfer to the array automatically." is incorrect, since I don't even have those options. So what is the proper process for getting the data off this cache so I can replace it? Someone please walk me through the steps. I'm getting concerned I may lose data. The errors are over 1500 now.
-
So...I don't have those options. I can change the Primary Storage from 'cache' to 'array', and leave the secondary storage to 'none'. However, running mover does nothing. No disk activity is observed, and no files are moved off the cache drive.
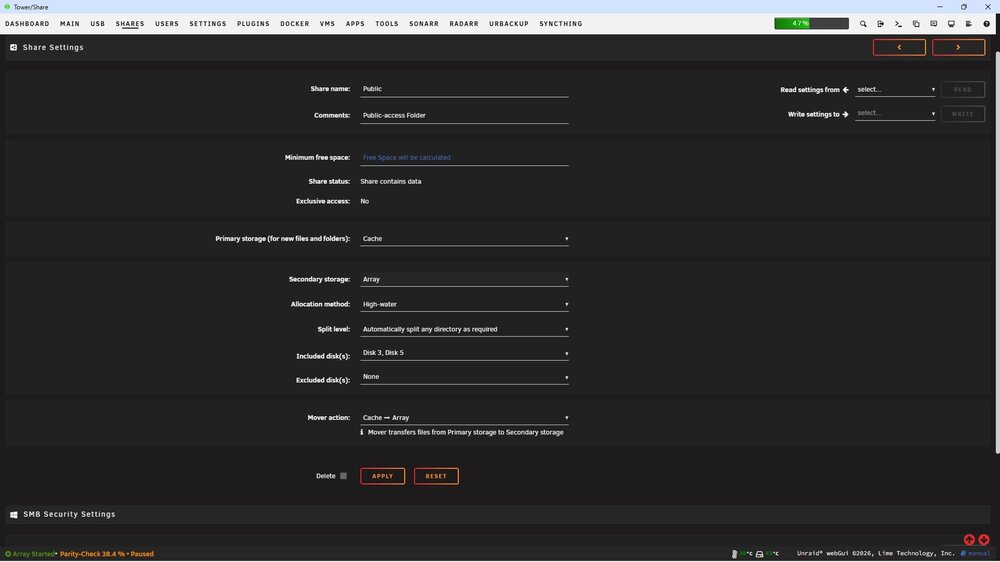
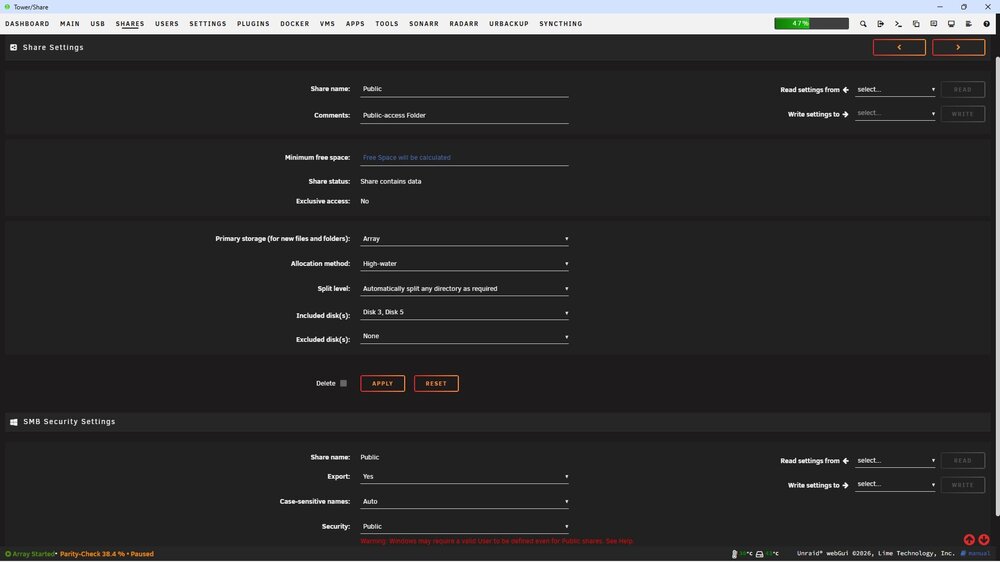
-
Awesome, thanks. It appears that I may need to do that. See below... Good to know, thanks! I ran the long SMART test and it reported "Completed: failed segments". The report is attached. It seems there are quite a few "Unrecovered Read Error" entries. I probably need to initiate a warranty replacement with Samsung. Bugger. tower-smart-20260606-1955.zip


