





itsalljustdata
Members
-
Joined
-
Last visited
-
I've done a bit of swapping around of hardware in recent months and thought i'd better get my iGPU (no dGPU any more on this box) transcoding back up and running again... but I don't seem to have a /dev/dri folder to pass through to the jellyfin docker container! lspci knows about the iGPU 0b:00.0 VGA compatible controller: Advanced Micro Devices, Inc. [AMD/ATI] Cezanne [Radeon Vega Series / Radeon Vega Mobile Series] (rev c8) (prog-if 00 [VGA controller]) Subsystem: Advanced Micro Devices, Inc. [AMD/ATI] Device 1636 Flags: bus master, fast devsel, latency 0, IRQ 4, IOMMU group 16 Memory at d0000000 (64-bit, prefetchable) [size=256M] Memory at e0000000 (64-bit, prefetchable) [size=2M] I/O ports at f000 [size=256] Memory at fcb00000 (32-bit, non-prefetchable) [size=512K] Expansion ROM at 000c0000 [virtual] [disabled] [size=128K] Capabilities: [48] Vendor Specific Information: Len=08 <?> Capabilities: [50] Power Management version 3 Capabilities: [64] Express Legacy Endpoint, IntMsgNum 0 Capabilities: [a0] MSI: Enable- Count=1/4 Maskable- 64bit+ Capabilities: [c0] MSI-X: Enable- Count=4 Masked- Capabilities: [100] Vendor Specific Information: ID=0001 Rev=1 Len=010 <?> Capabilities: [270] Secondary PCI Express Capabilities: [2b0] Address Translation Service (ATS) Capabilities: [2c0] Page Request Interface (PRI) Capabilities: [2d0] Process Address Space ID (PASID) Capabilities: [400] Data Link Feature <?> Capabilities: [410] Physical Layer 16.0 GT/s <?> Capabilities: [440] Lane Margining at the Receiver Kernel driver in use: vfio-pci Kernel modules: amdgpu radeontop gives a couple of errors, but still launches. root@beast:/dev# radeontop Failed to find DRM devices: error 2 (No such file or directory) Failed to open DRM node, no VRAM support. Collecting data, please wait.... Any bright ideas? (my money's on my own stupidity carrying some previous config through somewhere along the line) beast-diagnostics-20240922-1526.zip
-
I'm getting an error when mover is running (caused by dodgy data, but whatever...) I have a folder in my cache which ends with a trailing space "/mnt/cache/transcode/thumbs/Thumbs/2012-08-02 - " the value is being written correctly into the list (/tmp/Mover/Mover_Tuning_2023-11-10T105025.list), but when it gets read back in (for the purpose of checking for hardlinks) the script is being helpful and trimming that space off the end for me.. mvlogger: Hard File Path: .."/mnt/cache/transcode/thumbs/Thumbs/2012-08-02 -".. stat: cannot statx '/mnt/cache/transcode/thumbs/Thumbs/2012-08-02 -': No such file or directory #Test for hardlinks of the file LINK_COUNT=$(stat -c "%h" "$HARDFILEPATH") downstream it's also causing failures in here... totalsizeFilelist() { #Loop throug the custom mover filelist and add up all the sizes for each entry. #echo "Grabbing total filesize" #start looping while read CUSTOMLINE; do #PULL out file size mvlogger "..$CUSTOMLINE.." CUSTOMLINESIZE=$(echo "$CUSTOMLINE" | sed -n 's/.*;\(.*\)/\1/p') mvlogger "Custom Size: ..${CUSTOMLINESIZE}.." ((TOTALCACHESIZE+=$CUSTOMLINESIZE)) done <$CUSTOM_MOVER_FILELIST } Changing all (9) occurances of while read in /usr/local/emhttp/plugins/ca.mover.tuning/age_mover to while IFS=""; read appears to fix this issue, but is this going to break anything else?
-
diags attached beast-diagnostics-20230417-1234.zip
-
Hi All I'm seeing a weird error in Docker Settings (6.11.5) If the Docker service is stopped, but the array is still up then I get this error. If I stop the array, then go back to docker settings, then all behaves fine.. Irritatingly, none of the other pages which need Docker to be stopped recognise it as being stopped while this error is in place. So i have to stop the array to change these settings (it's network this morning....) I've checked the DockerClient.php file, and it's consistent with what was the current commit in GitHub as of the 6.11.5 release date, so I'm content that i've not borked anything at the UI level. Any ideas on where to look next? Is there an extra unnecesary extra slash in "unix:///var/run/docker.sock" - and if so is that being retrieved from somewhere?
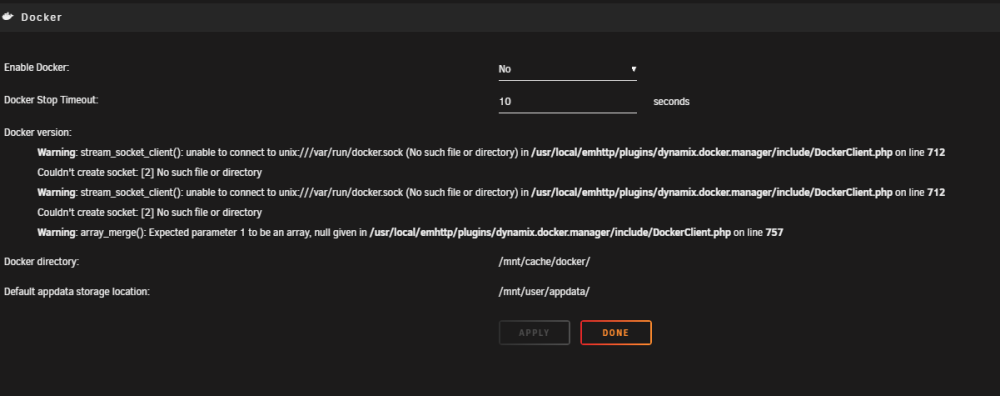
-
a bit of a necro-post, but I was having a play around with this earlier, and to get it working you just need to put DOCKER_OPTS="-H tcp://0.0.0.0:2376 -H unix:///var/run/docker.sock" into /boot/config/docker.cfg of course, you then get the warning... And the Docker Start Stop page in the UI cracks the whoops a bit as well.... I'm actually now moving onto using a dockersocket proxy container instead (tecnativa/docker-socket-proxy)
-
Funny you should mention this, I actually *like* the fact that it tells me that it's Google Authenticator. Then I don't need to check my Microsoft one first! 😁sorry, just noticed this! No idea really... I just did, and it worked! My theory was that the /identify page returned less data so was less "work" for the server to do (for when 16 cores/32 threads isn't enough?)I run a docker container called "autoheal" (willfarrell/autoheal:1.2.0 is the version you want to use as the "latest" one is regenerated daily which is a PITA) just give each container you want it to monitor a label of "autoheal=true" it also needs some sort of healthcheck command (if there's not one included in the image itself) - here's my plex one (goes in "extra parameters" on the advanced view --health-cmd 'curl --connect-timeout 15 --silent --show-error --fail http://localhost:32400/identity' *Remember - the port in this URL is the one from INSIDE the container, not where it's mapped to on the server * you can do similar for most containers, although a trap for young players is that some of the images don't have curl, so you need to use wget (and alter parameters to suit) I've attached my template for autoheal (from /boot/config/plugins/dockerMan/templates-user) my-autoheal.xml
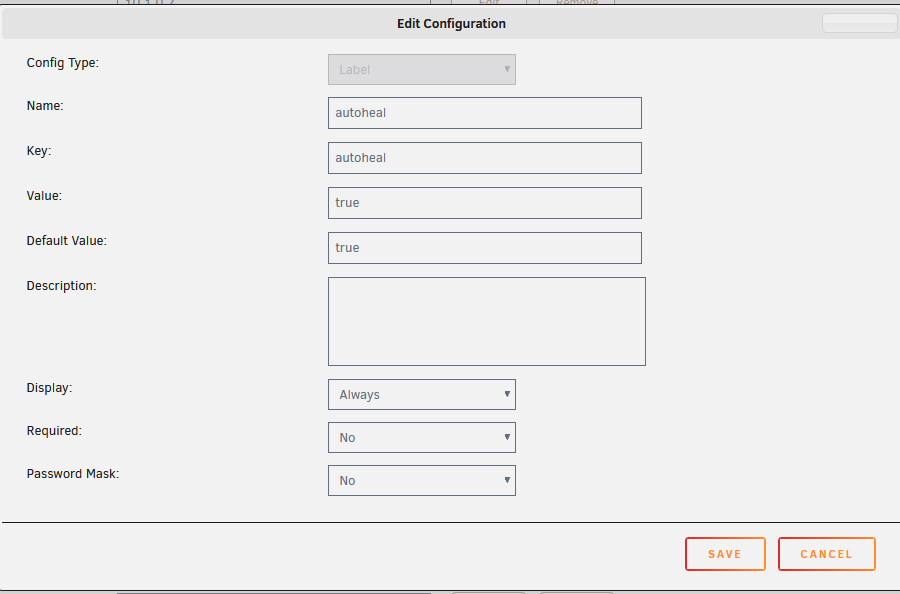 It appears that running your browser using 2 seperate profiles is enough to fool it. I've got it working here with 2 instances of firefoxhuh.... I'll give that a blast then....I'm hoping it's just me, but the webUI doesn't seem to want to perform multiple tasks concurrently (in seperate tabs/browsers). For instance, if i'm adding a docker container (doing the pull etc) in one tab - another window with something else in it will just hang (and eventually give me a timeout) when i try to refresh/navigate. Is there some nginx setting I need to tweak, or is this by design? beast-diagnostics-20220128-0825.zipyou'd put it just before consold8 find "/mnt/user/Media/Movies" -mindepth 1 -maxdepth 1 -type d -print0 | xargs -0 -n 1 bash consld8 -fOr you can just "bash" them into submission..... so instead of just doing diskmv blah blah2 (which will fail as no execute permission on diskmv) do bash diskmv blah blah2For posterity here's what i've done to fix it... at the bottom of /boot/config/go i added rm /root/.ssh cp -R /boot/config/ssh/root/ /root/.ssh and then i've done a User Script (scheduled hourly) to sync the data back to the flash drive rsync -au /root/.ssh/ /boot/config/ssh/root/
It appears that running your browser using 2 seperate profiles is enough to fool it. I've got it working here with 2 instances of firefoxhuh.... I'll give that a blast then....I'm hoping it's just me, but the webUI doesn't seem to want to perform multiple tasks concurrently (in seperate tabs/browsers). For instance, if i'm adding a docker container (doing the pull etc) in one tab - another window with something else in it will just hang (and eventually give me a timeout) when i try to refresh/navigate. Is there some nginx setting I need to tweak, or is this by design? beast-diagnostics-20220128-0825.zipyou'd put it just before consold8 find "/mnt/user/Media/Movies" -mindepth 1 -maxdepth 1 -type d -print0 | xargs -0 -n 1 bash consld8 -fOr you can just "bash" them into submission..... so instead of just doing diskmv blah blah2 (which will fail as no execute permission on diskmv) do bash diskmv blah blah2For posterity here's what i've done to fix it... at the bottom of /boot/config/go i added rm /root/.ssh cp -R /boot/config/ssh/root/ /root/.ssh and then i've done a User Script (scheduled hourly) to sync the data back to the flash drive rsync -au /root/.ssh/ /boot/config/ssh/root/




