




xoC
Members
-
Joined
-
Last visited
Everything posted by xoC
-
Okay, I'm pretty sure I have some disk on a 1 to 4 sata splitter. I'll unmount the power supply to check what it is.
-
Thanks, Yep I have multiple splitters, as the PSU doesn't have lot of this kind of power output and I have 10 disks. Are there good practices recommanded here ? Or maybe specific PSUs with more disk outputs ?
-
Hello, it has been quite some time that I have a lot of issues with my server. there almost always are new read errors when parity checking. If I change the sata cable it works for one or two week and it comes back. It was mostly on disk 5, even with new cables and a new disk. and here is my last parity check : I attached diagnostics as well. I tried numerous new cables, I added sata expansion cards in case in was the internal MB sata ports that were failing, and I've no clues anymore on what to do except that I don't trust my server anymore. Could it be power supply related ? Thanks in advance for your help. nastorm-diagnostics-20260608-0900.zip

-
Hello, I'm really struggling to get stability from my Unraid server. I get read errors and can't seem to cure it. These two disk have been rebuild last week, showing 0 read errors. Cables are new from last week. Then parity check this Sunday and both are disabled. They both are connected to a "Unraid supported" sata card. Attached are my diagnostics. Thanks in advance for your help. nastorm-diagnostics-20250422-1039.zipI tried the mv command on one of the old folder in lost+found and... it doesn't change the timestamps (at least the one of the last modification, which i'm interested in) ! Last modified timestamps are important for me, as my nextcloud share host my professional data (I'm a sound engineer) and my software checks that timestamp for every subproject that is rendered and imported in a main project. If the date doesn't match, when opening an old project (for referencing), it will force a re-rendering of everything. And since software/plugins florish and die fast, that would break a lot of projects. Thanks for your help !So after checking in detail every disk. 1) My data from the nextcloud share is properly ordered at once, just in a Lost&Found Folder. 2) My backup data on disk 5 is a total mess, split in thousand+ folders. This is backup data from my nextcloud share, so if I can get back my nextcloud share as it was, I can rebuild new backup from it instead of trying to order all backup data on disk 5 (which are split between disk 5 & 6, only data on 5 is a mess). 2) is not a problem if I can recover from 1). now big question I didn't find the answer looking on the net : How can I move the data from Disk 2 to Disk 2 (renaming the nextcloud share folder and moving it in the root folder), and be sure that all timestamps will be preserved ? It seems mv can't guarantee that. cp can but I don't have enough space on the disk to do a copy preserving timestamp then deleting original. Any ideas ?With further analysis : Disk 1 has 4 folders in lost & found : - 3 of them contain a few files - the last one seem to contain all the data of the Nextcloud share, properly ordered. And the size / number of file seems coherent. Could it be possible that the file system error concerned just the root folders of the disk, and everything else was preserved ? If I move that folder from lost&found to the Nextcloud share, should it work ? Edit : is it safe to say that the three other folders are very old lost & founds since their modified date is 2021 ? In green the folder with the nextcloud share. Sorry for the gazillion questions, I'm slightly panicking.
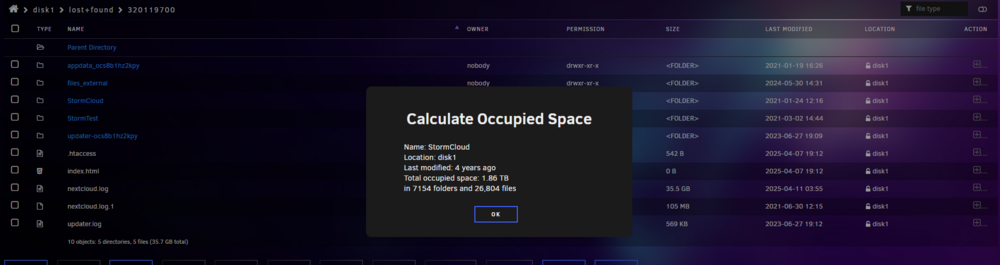
 All the files I'm concerned about are the ones stored in the Nextcloud share. I've stopped Nextcloud for the time being, but does Nextcloud rely on the file system of the array, or it relies on its own database for that and I could recover from Nextcloud ?If I put back the old disk5, unraid will force a rebuild, but it concerns only data, not file structure right ? So maybe I can get something working by reinstalling the old disk5, getting back the old file structure, and I can recover from one of my versioned backups ? Edit : I should mention that I repaired the file system of disk 5 after swapping disks and data rebuild on the new disk. So the old one is probably unmountable, but I don't think it was "zero log-ed".Hello, Due do bad sata cables and an unclean shutdown, I had 3 disk marked "unmountable". I did repair the file system on each three, it was talking about bag log but they never got mountable. After zero log the disks : - Disk 1 has all its data in lost&found, in random named folder - Disk 2 has just a few files, nothing alarming here - Disk 5 has all its data in lost&found, in random named folder Disk 1 & 2 support my Nextcloud share, sporting 4 TB of data. Disk 5 & 6 are versioned backups of the nextcloud share, done with Rsync. I just rebuilt disk 5 on a brand new disk but I have the older one (although giving a lot of read errors). In the Lost & Found folders, files seems okay with proper names, but put randomly. Any ideas ?
All the files I'm concerned about are the ones stored in the Nextcloud share. I've stopped Nextcloud for the time being, but does Nextcloud rely on the file system of the array, or it relies on its own database for that and I could recover from Nextcloud ?If I put back the old disk5, unraid will force a rebuild, but it concerns only data, not file structure right ? So maybe I can get something working by reinstalling the old disk5, getting back the old file structure, and I can recover from one of my versioned backups ? Edit : I should mention that I repaired the file system of disk 5 after swapping disks and data rebuild on the new disk. So the old one is probably unmountable, but I don't think it was "zero log-ed".Hello, Due do bad sata cables and an unclean shutdown, I had 3 disk marked "unmountable". I did repair the file system on each three, it was talking about bag log but they never got mountable. After zero log the disks : - Disk 1 has all its data in lost&found, in random named folder - Disk 2 has just a few files, nothing alarming here - Disk 5 has all its data in lost&found, in random named folder Disk 1 & 2 support my Nextcloud share, sporting 4 TB of data. Disk 5 & 6 are versioned backups of the nextcloud share, done with Rsync. I just rebuilt disk 5 on a brand new disk but I have the older one (although giving a lot of read errors). In the Lost & Found folders, files seems okay with proper names, but put randomly. Any ideas ?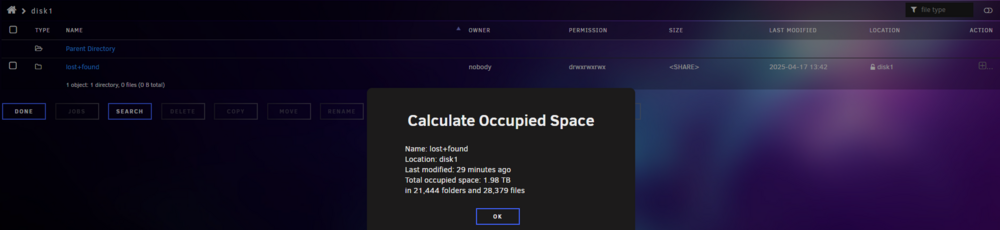
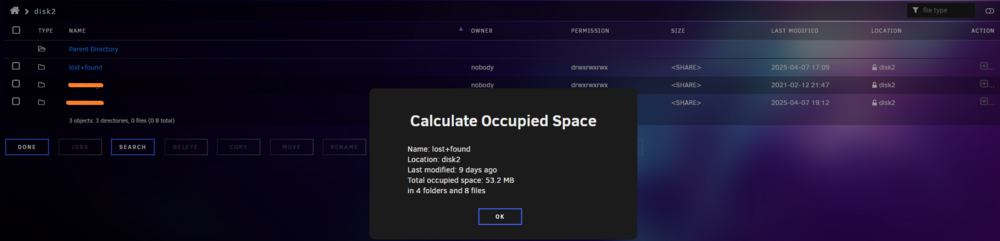
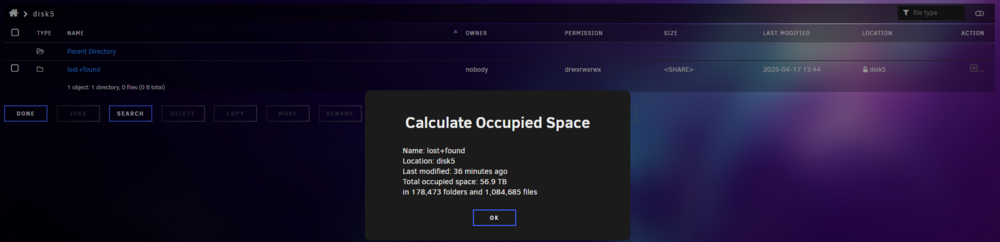 Thanks for your answer. Sometime ago, I did a mistake and began to move files from the GUI (not with Rsync) and it just filled my disks with full copies. I've deleted the non important backups, but looking at the overall size of the backups and considering my backup is from a folder where I only add files, never delete, it is way bigger than it should be if I didn't mess with a bad moving command. Since then, I've followed your commands in that topic to move all my backups will be on the Share / Disks I want with the Rsync command. Is it possible then to run a "check" and if a file is there multiple times (from a same source path), full copies of the same file in different folders, to "convert" all this copies to one hardlink each and shrink my backup size ? edit : oh and one more question, to better understand the "system" : if a backup share is on multiple disk, when we move with Rsync from one disk to another, can hardlinks from one drive link to data on another disk ? Because when we do "rsync --archive --hard-links --remove-source-files" it only speaks about disks, not shares. How could it know ?Small question : if I want to manually delete a backup from day X, can I naively use delete from the unraid GUI or do I need an Rsync delete command ?I have the same thing happening since an update somewhere in september/october IIRC. Usually at these times, the dashboard shows this : Dashboard becomes unresponsive. Everything else also. Can't even power off it doesn't respond (even from a one push on the HW button). And the terminal doesn't load so I can see what happens with HTOP... Edit : Since the last few months, I managed to get some diagnostics during one of this hang, showing nothing also. Edit2 : it was before September actually :
Thanks for your answer. Sometime ago, I did a mistake and began to move files from the GUI (not with Rsync) and it just filled my disks with full copies. I've deleted the non important backups, but looking at the overall size of the backups and considering my backup is from a folder where I only add files, never delete, it is way bigger than it should be if I didn't mess with a bad moving command. Since then, I've followed your commands in that topic to move all my backups will be on the Share / Disks I want with the Rsync command. Is it possible then to run a "check" and if a file is there multiple times (from a same source path), full copies of the same file in different folders, to "convert" all this copies to one hardlink each and shrink my backup size ? edit : oh and one more question, to better understand the "system" : if a backup share is on multiple disk, when we move with Rsync from one disk to another, can hardlinks from one drive link to data on another disk ? Because when we do "rsync --archive --hard-links --remove-source-files" it only speaks about disks, not shares. How could it know ?Small question : if I want to manually delete a backup from day X, can I naively use delete from the unraid GUI or do I need an Rsync delete command ?I have the same thing happening since an update somewhere in september/october IIRC. Usually at these times, the dashboard shows this : Dashboard becomes unresponsive. Everything else also. Can't even power off it doesn't respond (even from a one push on the HW button). And the terminal doesn't load so I can see what happens with HTOP... Edit : Since the last few months, I managed to get some diagnostics during one of this hang, showing nothing also. Edit2 : it was before September actually :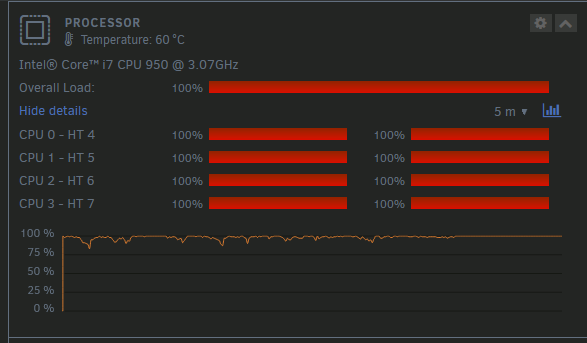 Hi. Yes the Dynamix one. I'm disabling it to test, thanks.Hello, My CPU activity is a bit weird. See following screenshot from just freshly rebooted server : Is it normal ?
Hi. Yes the Dynamix one. I'm disabling it to test, thanks.Hello, My CPU activity is a bit weird. See following screenshot from just freshly rebooted server : Is it normal ? Extended SMART test passed, I'm gonna give it one last chance.Do you think it's a big enough reason to get a warranty replacement ?Ok... I bought that disk in march 2023, so it seems like a pretty bad oneSo, we're back at smart errors. Disk was at "reported uncorrect = 1" when I re-plugged it (before rebuilding the array). I acknowledged the issue and let the server run, it rebuilt and there was no error. This night I received a mail after parity check saying it failed, with "Disk 5 - ST4000VN006-3CW104_ZW603BKR (sdk) - active 32 C (disk has read errors) [NOK]" with reported uncorrect gone to 2. System log show some read errors on disk 5, on sectors close to each other, but no more disk reset with the new controller. It is a quite recent disk BTW. Nov 26 04:15:21 NAStorm kernel: ata22.00: exception Emask 0x0 SAct 0x7f SErr 0x0 action 0x0 Nov 26 04:15:21 NAStorm kernel: ata22.00: error: { UNC } Nov 26 04:15:21 NAStorm kernel: I/O error, dev sdk, sector 146077392 op 0x0:(READ) flags 0x0 phys_seg 59 prio class 2 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077328 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077336 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077344 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077352 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077360 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077368 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077376 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077384 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077392 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077400 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077408 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077416 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077424 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077432 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077440 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077448 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077456 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077464 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077472 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077480 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077488 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077496 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077504 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077512 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077520 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077528 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077536 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077544 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077552 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077560 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077568 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077576 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077584 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077592 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077600 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077608 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077616 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077624 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077632 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077640 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077648 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077656 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077664 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077672 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077680 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077688 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077696 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077704 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077712 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077720 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077728 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077736 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077744 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077752 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077760 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077768 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077776 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077784 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077792 Nov 26 04:30:15 NAStorm root: Fix Common Problems: Error: disk5 (ST4000VN006-3CW104_ZW603BKR) has read errors I'm attaching current diagnostics. nastorm-diagnostics-20231127-1642.zip
Extended SMART test passed, I'm gonna give it one last chance.Do you think it's a big enough reason to get a warranty replacement ?Ok... I bought that disk in march 2023, so it seems like a pretty bad oneSo, we're back at smart errors. Disk was at "reported uncorrect = 1" when I re-plugged it (before rebuilding the array). I acknowledged the issue and let the server run, it rebuilt and there was no error. This night I received a mail after parity check saying it failed, with "Disk 5 - ST4000VN006-3CW104_ZW603BKR (sdk) - active 32 C (disk has read errors) [NOK]" with reported uncorrect gone to 2. System log show some read errors on disk 5, on sectors close to each other, but no more disk reset with the new controller. It is a quite recent disk BTW. Nov 26 04:15:21 NAStorm kernel: ata22.00: exception Emask 0x0 SAct 0x7f SErr 0x0 action 0x0 Nov 26 04:15:21 NAStorm kernel: ata22.00: error: { UNC } Nov 26 04:15:21 NAStorm kernel: I/O error, dev sdk, sector 146077392 op 0x0:(READ) flags 0x0 phys_seg 59 prio class 2 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077328 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077336 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077344 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077352 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077360 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077368 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077376 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077384 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077392 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077400 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077408 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077416 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077424 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077432 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077440 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077448 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077456 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077464 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077472 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077480 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077488 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077496 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077504 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077512 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077520 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077528 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077536 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077544 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077552 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077560 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077568 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077576 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077584 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077592 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077600 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077608 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077616 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077624 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077632 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077640 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077648 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077656 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077664 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077672 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077680 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077688 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077696 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077704 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077712 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077720 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077728 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077736 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077744 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077752 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077760 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077768 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077776 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077784 Nov 26 04:15:21 NAStorm kernel: md: disk5 read error, sector=146077792 Nov 26 04:30:15 NAStorm root: Fix Common Problems: Error: disk5 (ST4000VN006-3CW104_ZW603BKR) has read errors I'm attaching current diagnostics. nastorm-diagnostics-20231127-1642.zip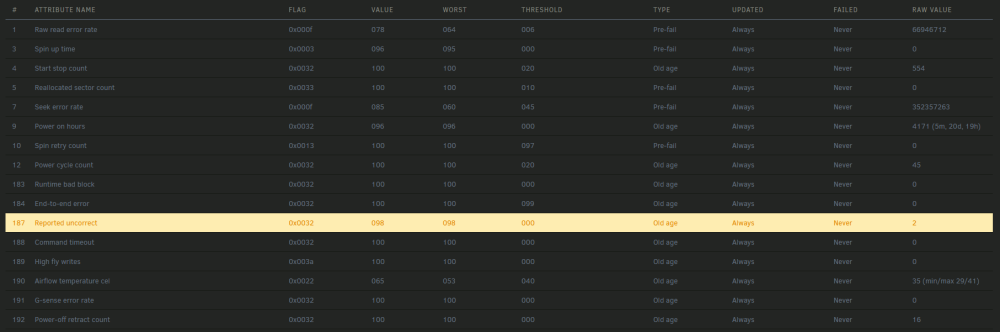 Thanks. Currently rebuilding the disabled disk, let's hope it will be good this time !So I've bought a 6 port card based on ASM1166, upgraded the firmware to the latest. How's the procedure to migrate disk ? I have in mind to move all the ones connected to the maxwell & jmicron chipsets. Can I just move the 4 disks at the same time, restart and it will be recognized ?Thanks for your clarificationIt's one of the controller from the motherboard (which has 3 controllers managing 10 ports). Maybe it is failing ?Hello ! So, it worked for ~20 days and then I got some error. It was late september, and I had too much work and no time to check, so my server has been powered down since that time. I managed to get the diagnostics before shutting down, they are attached. Thanks in advance. nastorm-diagnostics-20230927-1715.zip
Thanks. Currently rebuilding the disabled disk, let's hope it will be good this time !So I've bought a 6 port card based on ASM1166, upgraded the firmware to the latest. How's the procedure to migrate disk ? I have in mind to move all the ones connected to the maxwell & jmicron chipsets. Can I just move the 4 disks at the same time, restart and it will be recognized ?Thanks for your clarificationIt's one of the controller from the motherboard (which has 3 controllers managing 10 ports). Maybe it is failing ?Hello ! So, it worked for ~20 days and then I got some error. It was late september, and I had too much work and no time to check, so my server has been powered down since that time. I managed to get the diagnostics before shutting down, they are attached. Thanks in advance. nastorm-diagnostics-20230927-1715.zip









