Richard Harnwell
Members
-
Joined
-
Last visited
-
Thank you (sorry, didn't see the notification for this at the time). So, it looks like the above entry is disabling various low power states? Not sure whether to try that or wait a bit longer for 7.2 update when it comes....
-
Thanks. I have it up and running, on the "good" drive now. After the reboot I tried starting the array with just that one pool/cache drive, and Unraid refused as mentioned. I then tried it with no pool, and it refused, but interestingly when I then (for no good reason) tried again with just the one drive, it started up this time. All VMs and containers looked OK, so I took backups of everything and have left it in that state for now. I would love to understand why this has happened twice for me (on two different drives), especially why BTRFS RAID1 couldn't cope with a disk issue, but my main focus was to get Blue Iris and Home Assistant up and running again. I see there is a known issue in 7.0.1 (that I'm on) with VVME drives disappearing. Looks like this is fixed in 7.2, so I'm thinking I should wait for the public release of that and upgrade. https://forums.unraid.net/bug-reports/prereleases/72-beta-3-request-kernel-bug-fix-for-nvme-ssd-reset-r4044/ That would seems like a good time to try to get the second drive re-introduced to the pool. Would be very grateful for any thoughts on what might be happening or anything I can do to help with the robustness of my setup. I have taken another diagnostics dump - the log file appears to start straight after the reboot last night. tower-diagnostics-20251025-1154.zip
-
Desperate to get my VMs (Blue Iris and Home Assistant) up and running again, so I've taken to seeking some help from CoPilot, while being very cautious with it's suggestions. To try to get to a clean state I've ended up restarting, after having to manually kill off the two VM processes (the VMs tab was just blank so couldn't be done in the gui) to allow the array to stop. Now it's come back (array still stopped) I see the problem SSD shows as "missing". I remember this is exactly what happened last time. Back then I shutdown, reseated drive, powered up and it appeared, but I then ended up replacing the drive. This time round it seems unlikely the new drive has failed again. and I see there is a known error with NVME drive dropouts after boot in 7.0.1. I'm thinking I should maybe stabilise the system before upgrading, and trying to get it running on just the one "good" cache drive. Unfortunately when I try to start the array with just one (or even none) cache drive it refuses.
-
I'm on Unraid 7.0.1, running on a AOOSTAR WTR PRO AMD NAS box. My cache pool is on two 1TB NVME SSD drives using BTRFS RAID1. Earlier today all my VMs and containers died and looking at the logs I see seems related to issues on one of the drives. Lots of these: Oct 24 16:42:28 Tower kernel: BTRFS error (device nvme1n1p1: state EA): bdev /dev/nvme0n1p1 errs: wr 13726102, rd 291197, flush 80309, corrupt 802103, gen 0 It's a bit frustrating that I relatively recently added a second drive to my cache so I had redundancy, but this is now the second time that errors reported on just one drive seems to stop everything using the cache pool. The Pool Devices section shows both drives as normal, active. SMART shows no errors, though the pool device stats shows a massive amount of errors for the one drive. Id Path Write errors Read errors Flush errors Corruption errors Generation errors -- -------------- ------------ ----------- ------------ ----------------- ----------------- 2 /dev/nvme1n1p1 0 0 0 0 0 4 /dev/nvme0n1p1 13732034 291232 80309 802103 0This was the same situation I had a few months ago with another drive. This led me to believe it was a hardware issue, so I replaced the drive. This error is now for the replaced drive (a WD Blue 750), so I'm starting to think maybe these aren't hardware errors unless I've been incredibly unlucky. Could it be an issue with the M.2 slot maybe? Here's the btrfs filesystem usage: Overall: Device size: 1.84TiB Device allocated: 774.06GiB Device unallocated: 1.08TiB Device missing: 0.00B Device slack: 0.00B Used: 699.04GiB Free (estimated): 591.96GiB (min: 591.96GiB) Free (statfs, df): 580.78GiB Data ratio: 2.00 Metadata ratio: 2.00 Global reserve: 512.00MiB (used: 0.00B) Multiple profiles: no Data Metadata System Id Path RAID1 RAID1 RAID1 Unallocated Total Slack -- -------------- --------- -------- -------- ----------- --------- ----- 2 /dev/nvme1n1p1 384.00GiB 3.00GiB 32.00MiB 566.84GiB 953.87GiB - 4 /dev/nvme0n1p1 384.00GiB 3.00GiB 32.00MiB 544.48GiB 931.51GiB - -- -------------- --------- -------- -------- ----------- --------- ----- Total 384.00GiB 3.00GiB 32.00MiB 1.08TiB 1.84TiB 0.00B Used 347.70GiB 1.82GiB 80.00KiB I can't help thinking there's something fundamentally wrong with my setup, as I would rather hope an error on just one of my RAID1 cache drives would flag an issue, but allow everything to continue on one drive. Would be very grateful for any help to get my VMs back online as soon as possible, and then maybe understand what's going wrong here. At the moment I'd be happy to go back to my old cache arrangement of one drive that I backed up regularly, as that seemed much more fault tolerant than this RAID1 setup! Have attached a diagnostics zip in case it's useful. tower-diagnostics-20251024-1709.zip
-
working for me again too
-
Tried an Unraid (controlled) restart to see if it fixed it. Now it's come back I've lost one of my two SSD cache disks. I assume that's just a coincidence!
-
Yep, I've just hit the same issue.
-
I got it working with a Ubuntu server VM that I passed the USB port/stick to, and following the Hauppauge instructions from https://www.hauppauge.com/pages/support/support_linux.html , namely: sudo add-apt-repository ppa:b-rad/kernel+mediatree+hauppauge sudo apt-get update sudo apt-get install linux-mediatree sudo reboot sudo apt-get install linux-firmware-hauppauge I then installed TVHeadEnd, and I have it working and receiving all the channels (haven't figured out how to get them down to just the subset I want easily yet). The video quality is far from perfect though - see screenshots. Behaves as if the signal is poor, when in fact it is perfect on my Sky box. Not had chance to investigate that much yet though. You're right, I would prefer not to have to devote a whole Linux VM to it though. Mind you, could be worse, if that didn't work I would have probably tried it with a Windows VM!


-
Thank you, that's a pain. My Unraid runs on a AOOSTAR WTR PRO which unfortunately has no card slots, so has to be USB for my use case. Before I abandon this stick (or resign myself to buiding a standalone Windows box for it) I wonder if it's worth my trying an Ubuntu VM and passing through the USB port to it, given Hauppauge specifically mention getting it working with that distro...
-
Thanks. I tried the command. Not sure if you'd expect output from it, but there was none. Have attached new diagnostics in case anything has changed. tower-diagnostics-20250225-0039.zip

-
Thank you fo that. That's very confusing/annoying, as I bought it based on the UK page saying it is supported! Is the Ubuntu PPA mentioned some sort of workaround/add-on for Linux support? If so, could I maybe get around it by using an Ubuntu VM and passing the USB through to it? https://www.hauppauge.co.uk/site/products/data_novas2.html

-
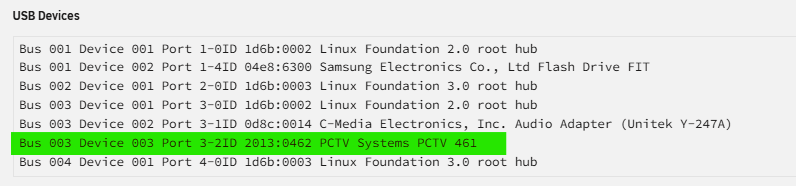
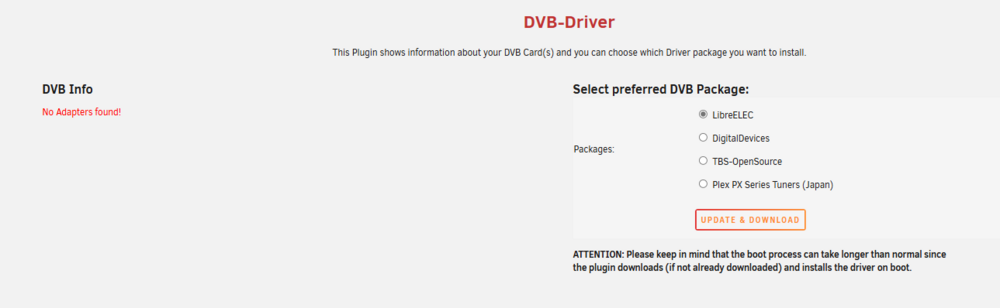
Any tips on getting this working with Hauppauge WinTV-NOVA-S2 USB dongle? I have one plugged in, and have installed the plugin and rebooted. I see it appearing under USB devices via the System Devices plugin, but there is no /dev/dvb file/folder. tower-diagnostics-20250223-2007.zip
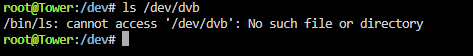
-
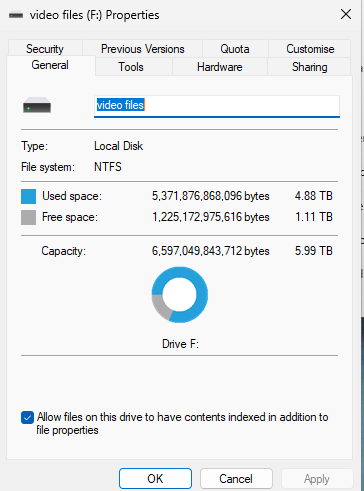
Thanks. Not really got my head around the subtleties of allocating a disk to a VM though, so no quite sure what you mean. The disk was certainly showing 1TB of free space in the guest VM though. I have since found another drive and allocated that and it seems OK so far. I think I've obviously allocated it slightly differently this time though, as this time it doesn't show the used percentage in Unraid. In the VM settings I'm referencing it as /dev/disk/by-id/ata.. Would you consider this the correct/best way? Now the old/problematic disk (6TB) isn't in use for Blue Iris I started a SMART extended self test on it. It has seemingly locked up at 10% (no obvious way to interrupt it). So I guess maybe there is a fundamental issue with it?



-
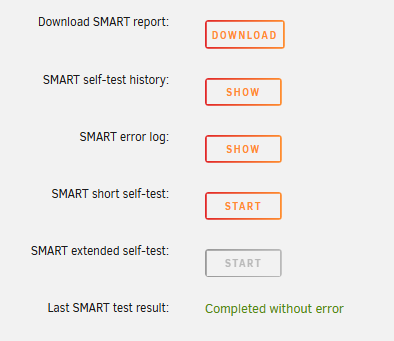
My Windows 11 Blue Iris VM has been running fine until it suddenly now keeps getting paused. It won't resume, but when I force shutdown and start it it will run long enough for me to RDP and everything looks OK in the client (no power savings turned on, plenty of disk space), but it's only lasting a matter of minutes before getting paused again. In the libvirt diagnostic file I've just seen this: 2025-02-08 11:03:27.912+0000: 12703: warning : qemuProcessHandleIOError:866 : Transitioned guest vm-blueiris to paused state due to IO error 2025-02-09 11:37:07.454+0000: 12703: warning : qemuProcessHandleIOError:866 : Transitioned guest vm-blueiris to paused state due to IO error 2025-02-09 11:37:20.045+0000: 12703: warning : qemuProcessHandleIOError:866 : Transitioned guest vm-blueiris to paused state due to IO error Is there any way to get more info on this, at least which disk is the issue? It's using the cache pool for its C drive, and that's 2x 1TB NVME SSDs with btrfs. They both show 0 errors. The main video recording drive is a WD Purple 6TB HDD, that's accessed as an Automounted Unassigned Device. It shows full in Unraid but in the VM I can see it has plenty of free space. The dashboard isn't showing a disk error count, but when I run a SMART short test (extended greyed out) it shows 0 errors. EDIT - when I do a Tools -> Check Disk on the both drives from within the VM, the C drive scan finished fine, but when I do it on the video storage drive, it locks up the whole VM in seconds. So I guess I've answered that question. Seems weird though, that such an issue with a non-OS drive can completely lock up Windows/the VM, and also that Unraid itself doesn't see an issue with the drive (at least the quick SMART scan). I'm on 7.0.0. Would appreciate any advice as I'm without my security recording system until I get this fixed!


-
Earlier today I accidentally shutdown Unraid, and it felt a bit too easy... I'd been working in Home Assistant on my iPad, and needed a new (Safari) tab. To try to tackle my normal ever growing number of tabs, I just selected an old one to re-use. It was one I'd used to shutdown Unraid days/weeks ago, but I thought no more of it - just pasted in new URL and went to that site. When I shortly after returned to Home Assistant (Unraid VM) and saw it was unavailable I realised Unraid was now shutdown! I guess it must have been because I was maybe waking an old tab, and the "shutdown URL" was resent to the host? I'm certain that I wasn't asked any "are you sure you want to resubmit this?" type question. Is it expected that this could happen as I described? I realise I should have probably closed my tab after Unraid was shut (I certainly will from now on), but I still feel that maybe there should be something in place to guard against this. Keen to hear others' thoughts on the matter.