Garbonzo
Members
-
Joined
-
Last visited
-
I have to pull the cooler to get to the ram in this build ...but I will report the results back when I can.. Thanks again, -g
-
I am attaching new diagnostics since its been running another week or so now, but I just don't know what to look for. I have an older Ryzen I can put back in (I upgraded an old R7 1700 with an R9 5900x about 6 months back. Prior to that I had used the same MB/Memory for 2+ yrs. So the processor sticks out as the most likely to me... Any advice helpful and welcome. -G ezra-diagnostics-20250923-0935.zip
-
I was worried that becuase I kept seeing an L3 error it was a CPU problem.. I will try to get the time to take it down and swap some memory around this weekend. What diagnostic approach would you take? I have 4 matching ram sticks, I figure 2 and 2 to test... I just need to know what software/process to get something repeatable.. Thanks once again for your help.
-
I don't want to just "acknowledge" an error in fix common problems like this without understanding it (somewhat)... Here are the events as I recall, yesterday afternoon I got an error, that I can no longer find, and I didn't have time to research properly, but a quick google was indicating that it could have been something with my ECC memory (detecting an error?) or L3 cache maybe, either way, I was going to have to post here, so I tried getting diagnostics to save, but my music was still streaming via Emby, so I didn't think about it any more until this afternoon... ..At this point the dashboard showed "log filesystem" at 100% so something was writing there, and I got an email sent from "Console and webGui login account" (which is either something built in, or something I set up a few years ago and don't remember) that read as follows.. error: error writing to /var/log/libvirt/libvirtd.log.1: No space left on device error: error copying /var/log/libvirt/libvirtd.log to /var/log/libvirt/libvirtd.log.1: No space left on device but after a reboot that is sitting at 3% which seems more reasonable.. I however don't know how to read the diagnostics... The relevant bits (based on nothing other than the example shown after clicking on the error in "fix common problems" tool)... Sep 15 19:14:50 Ezra kernel: mce: [Hardware Error]: Machine check events logged Sep 15 19:14:50 Ezra kernel: [Hardware Error]: Corrected error, no action required. Sep 15 19:14:50 Ezra kernel: [Hardware Error]: CPU:0 (19:21:2) MC18_STATUS[-|CE|MiscV|AddrV|-|-|SyndV|CECC|-|-|-]: 0x9c2040000000011b Sep 15 19:14:50 Ezra kernel: [Hardware Error]: Error Addr: 0x000000013f2c72c0 Sep 15 19:14:50 Ezra kernel: [Hardware Error]: IPID: 0x0000009600150f00, Syndrome: 0x455c00040a800d00 Sep 15 19:14:50 Ezra kernel: [Hardware Error]: Unified Memory Controller Ext. Error Code: 0 Sep 15 19:14:50 Ezra kernel: EDAC MC0: 1 CE Cannot decode normalized address on mc#0csrow#0channel#1 (csrow:0 channel:1 page:0x0 offset:0x0 grain:64 syndrome:0x4) Sep 15 19:14:50 Ezra kernel: [Hardware Error]: cache level: L3/GEN, tx: GEN, mem-tx: RD Sep 15 19:15:01 Ezra unassigned.devices: Remote Share '//192.168.111.99/media_backup' is not set to auto mount. Sep 15 19:15:01 Ezra unassigned.devices: Remote Share '//192.168.111.99/Z' is not set to auto mount. Sep 15 19:15:01 Ezra unassigned.devices: Remote Share '//TRUENAS/idiot' is not set to auto mount. Sep 15 19:15:01 Ezra unassigned.devices: Remote Share '//TRUENAS/jane' is not set to auto mount. Sep 15 19:16:19 Ezra nmbd[2708]: [2025/09/15 19:16:19.943080, 0] ../../source3/nmbd/nmbd_incomingdgrams.c:303(process_local_master_announce) Sep 15 19:16:19 Ezra nmbd[2708]: process_local_master_announce: Server HOMEASSISTANT at IP 192.168.111.158 is announcing itself as a local master browser for workgroup WORKGROUP and we think we are master. Forcing election. Sep 15 19:19:20 Ezra nmbd[2708]: [2025/09/15 19:19:20.068259, 0] ../../source3/nmbd/nmbd_incomingdgrams.c:303(process_local_master_announce) Sep 15 19:19:20 Ezra nmbd[2708]: process_local_master_announce: Server HOMEASSISTANT at IP 192.168.111.158 is announcing itself as a local master browser for workgroup WORKGROUP and we think we are master. Forcing election. Sep 15 19:23:01 Ezra root: Fix Common Problems Version 2025.08.07 Sep 15 19:23:06 Ezra root: Fix Common Problems: Error: Machine Check Events detected on your server Sep 15 19:23:06 Ezra root: mcelog: ERROR: AMD Processor family 25: mcelog does not support this processor. Please use the edac_mce_amd module instead. Sep 15 19:23:06 Ezra root: CPU is unsupported I am sure there are many things that I can improve, and all help is welcomed, but specifically I need to know about this error so I can either move on or dig in 🤣 thanks in advance -G ezra-diagnostics-20250915-1933.zip
-
Ok, if I was going to do that I guess I could just re-format it and re-add it and see what happens. It just gave me the warning that I would loose the pre-check info and that re-formatting it would cause it to take awhile to add again (I was thinking that kinda implied about the time of a parity-check or something, wasn't sure... (and the extended test is still running... not sure exactly how many hrs, but around 10 now... So it sounds like there's no ""magic" thing I need to do to maintain the pre-check data or whatever, that ship has sailed? I just need to add it as if it was a disk I just put hands on... I am not going to cancel this extended self check if it is still running, I read that can sometimes take like 18hrs? Am I good do to use the array/dockers/vms just not shut down the array (or of course reboot). Thanks once again for your assistance @JorgeB
-
Yeah, I guess I dont understand what needs to be rebuilt... from my perspective I failed to add a disk6 that had been pre-cleared... the array never mounted from my pov. meaning it didn't have that red x until I removed it because the array wouldn't start. Only then, now that its disabled does it have the X and is showing "not installed" but there was never any data written to it so I didn't think what I was seeing now was an "emulated" disk6 of the 14tb that I failed to add... I am confused but its 4:19am and I should't reply anymore tonight (probably not productive) but thanks for the response, and I will look at any further responses with fresh eyes in the a.m. Thanks again, -G
-
OK, so I will try to keep this short. Needed to add a drive. Got the least expensive drive I could (twice, one doa) a 14tb Recert WDC_WUH721414ALE604 I precleared it. When I attempted to add it to the array, the array failed to start.. I disabled the newly added drive to run a SMART scan, but then could not restart the array. I shut-down and restarted, so now I can start the array but disk6 is showing not installed (I guess I just expected it to go back to 1-5 the way it was, but I am unsure why it didn't mount. It told me anything on the disk would be erased... I though maybe I could just reformat and try again.. however I then got the message I would loose the pre-clear info that took like 18hrs to run, so I didn't want to do that if it still would not work... So I just started an Extended SMART scan, it seems that can take quite a while too... I just want to make sure the disk is sound as well... drives aren't cheap atm, and I don't have another spare, so I am just trying to understand what is going on... I attached my diagnostics, but can attach the SMART log once that completes (how long is TOO long to wait, its been going over an hour at 90% completed) EDIT: I was thinking about the diagnostics, and they were not saved fully (thanks brave) when I shut-down and restarted after the new drive failed to mount the first time, so I am not sure if it will show the same thing, because I had set it back to disabled before the reboot... I am unsure of alot right now (its 3am). Thanks in advance, -G ezra-diagnostics-20250308-0124.zip
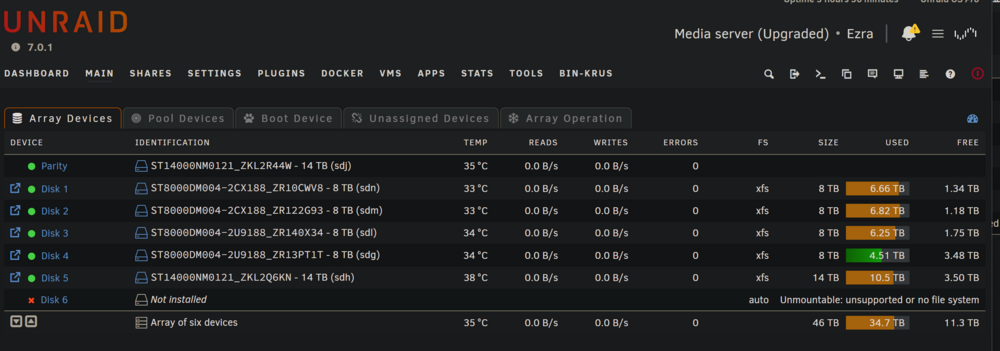
-
Sorry about the diags, I was rushing. Yes, I had rebooted. The system didn't lockup or crash, it just started emulation disk 4 when I unplugged the DOA disk (it wasnt hot swappable, just regular HBA-4way sata cable) that wasn't in the array, it still affected it. The only time I had CRC errors keep growing was a bad cable set, since replacing these I had not had the issue, but figured messing with another connection while powered on was the cause... I am just trying to get that disk back working again. I cleared it on the dashboard. It SEEMS like to clear the dread red x previously, I had to set the device to "unassigned" and restart the array... then stop it... then add the disk back... then start... I am trying that now. EDIT: yeah, it seems like that is just going to rebuild it from the parity, I haven't pulled the trigger in case you tell me there is a way to get it back in place, so I am leaving it unassigned so it stays emulated until you tell me I have to rebuild it ezra-diagnostics-20250223-0330.zip
-
I hate that I can never seem to figure these out without asking for help. But people are always super helpful about telling me HOW to fix it, if never giving me any idea of what to search for in the diagnostics to look for these things... I am sure there are keywords to search for or a tool to parse the diagnostics in a way to make them a little easier to grok. EITHER WAY, here is my latest (self inflicted) issue. Array was FINE, needed SPACE. I order a 14tb reman'd drive from amazon to try... they were cheap atm and have a 3yr warranty, so figure try... other than the SMR drives I have, usually if it lasts the first year its good for 5 or more... just my experience. Anyway, that drive was DOA. While I had my case open and the drive wouldn't work, I had accidentally removed the power... everything was fine... about 10 mins later, I figured with no power there shouldn't be a problem pulling the data wire... wrong. None of the other drives were touched or bothered in any way... didn't want to even touch the cables.. Disk 4 dropped anyway. I have powered down, reseated the cables, etc... last time I had a similar problem, running the repair in maint mode fixed and then there was a way to add it back.. I just don't recall the steps and some things have... SO - I would LIKE to get disk4 back online, and then add my replacement 14tb as disk6 when it arrives. However, if I have to, I suppose I could replace disk4 with the 14tb and REBUILD, then decide if I am going to keep that 8tb SMR drive in there at all... (the plan is to get all of those 8tb SMR drives out of there this year, I just can only do one every couple of months...) Thanks so much in advance, I wish I had more time to re-read and edit my text up there, but wouldn't get this posted before heading out for dinner, and am hoping to get working on this later tonight... so, apologies if long winded and scattered, it was really stream of consciousness.. -G Unconfirmed 801928.crdownload
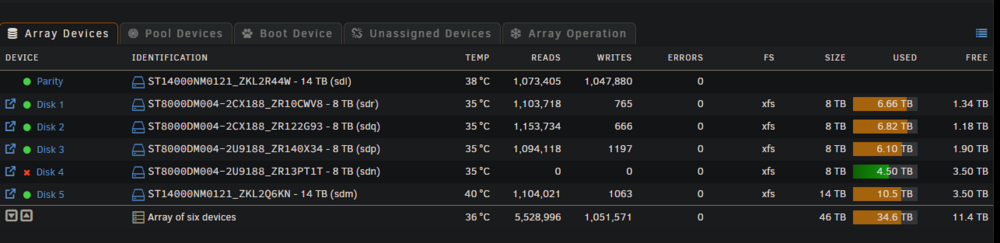
-
I have been sticking with MacVlan for some time now, but am wanting to switch to IPvlan to see if it stops the once-a-month or so crash I am having... I don't have the skill currently to figure out WHY the crash is happening, but I do keep getting this message telling me to switch to IPvlan. Back when the issue (about macvlans) started, I read through the "help" and it was pretty confusing and complicated. Since I wasn't having problems, I put it on the back burner. Now I am trying to switch and see that there might be some issues with which versions of what docker I use, and so on... plus my mediastack is a custom network, and the latest instructions I just read through said to put anything needing to be proxied in "BRIDGE" so I am wondering where I am gonna land there. I guess, if anyone has good current info on just making the switch that might come in handy, I would appreciate it. -G
-
Disk5 started throwing some errors while I was out of town for Xmas. It has been emulated since then, and I am going to try to move forward with it today, but may not have time to open it up and move some drives around (the 2x 14tb drives I added just last month run hot where they are mounted without another fan, so I want to move them a bit). But I am not sure if I should move the contents of DIsk5 to the mostly empty DIsk6 and then just replace Disk5 later, but at least have the array back operating in the green... or remove and re-add Disk5 and run some test/diags to make sure I am ok... This seems to happen whenever I have a hard drive problem.. errors of any kind really, I just don't feel like I know where to START or the best way to BEGIN reading/trying to understand what is going on... I understand there are many variables with harrd drives. But is there any resource that will give me some direction like: Look "here" to determine type of error, or something.. then based on that, probable reasons WHY they occurred... Also, I have many of these shucked 8tb Seagate drives from Costco (SMR) that are problematic for multiple reasons.. Several that are removed because of various "reasons" over time, but they are working without issue in other devices (botrh in TrueNAS Scale and a 5bay usb enclosure using drive pooling) Other than doing a pre-clear, how can I check to see if one of these drives would be BETTER to replace Disk5 with on a temporary basis until I can get ANOTHER new drive to replace it with. The NEW Seagate 14tb drives that Costco had turned out to be the newer dual actuator Exos 2x14 drives. A step up for sure! (but they do run even warmer than the SMR drives). So whenever they get them back in stock, I am planning to replace ALL of the 8tb's over this coming year... as I CAN (hopefully NOT as I HAVE TO). Anyway, every time I have an issue, I post the diags and get my problem solved, but never feel like I have learned how to figure anything out for myself moving forward.. Obviously I appreciate the help, but would like to be moving toward self sufficiency for these kinds of situations.. So two related questions: best way to handle the "x" disabled drive TODAY. best way to understand why/what is cause behind the failure (I suppose) TIA, -G ezra-diagnostics-20231226-0540.zip
-
Somehow the Windows Server VM that is connected to these terrible drives for the purpose of a second "backup" had it's network discovery turned off. I need to better understand the plugin anyway, especially the common script in general, its over my head atm tbh, and I really would love a way to delay the mount until the VM is online... that is something I have to do manually every time I restart the server, and would LOVE to automate! But sincere thanks for helping me focus in to find the problem I was having with the mount... it surprised me that the plugin searched and found the server, and share and let me set it up again, but I guess to be fair, when I pinged the EzraWin server it showed the IP address, just didn't return any pings, so I guess DNS resolved the ip, but I am shocked it took the username/password and showed me the mountable shares... but really, thanks!
-
Ok, back home and here is the new diags. I really do appreciate you taking a look! ezra-diagnostics-20231210-1702.zip
-
yeah, sorry, that was my bad, I forgot I turned that on when trying to figure this out when I first noticed it a few days ago after the update... I will get on that and post back soon, thanks for the quick reply though!
-
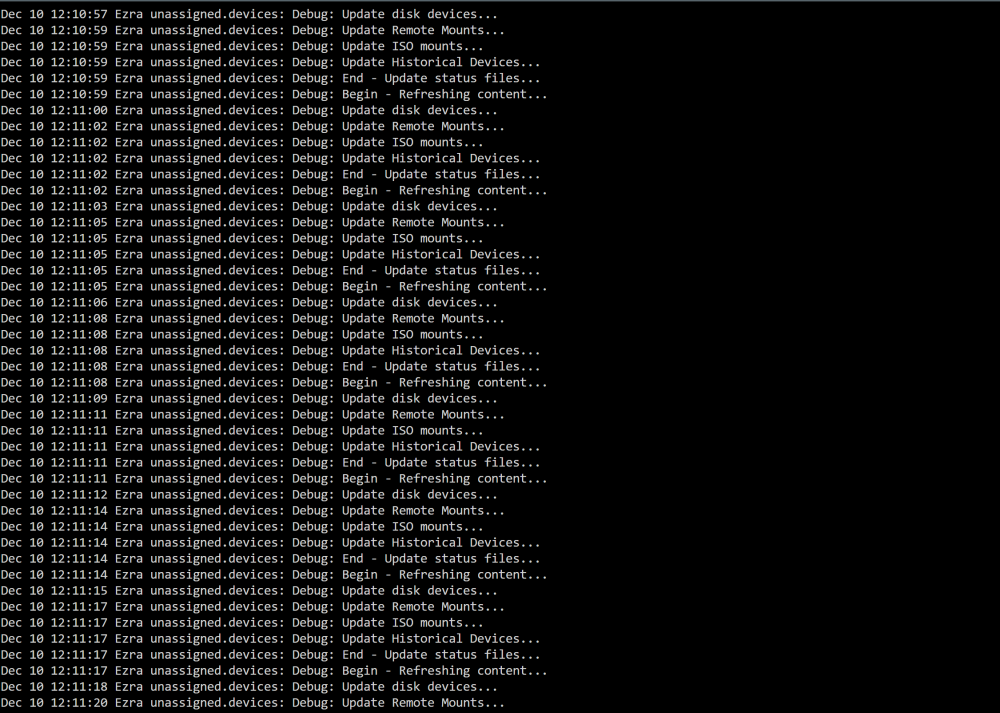
I have been using UD without issues before updating from 6.12.4 to 6.12.6 but have not been able to mount anything since. The log shows this happens ever few seconds... here are my diags ezra-diagnostics-20231210-1212.zip I really don't know where to start and haven't been able to google anything particularly helpful on my own, so asking for help from those that know... TIA -G