




bmrowe
Members
-
Joined
-
Last visited
Everything posted by bmrowe
-
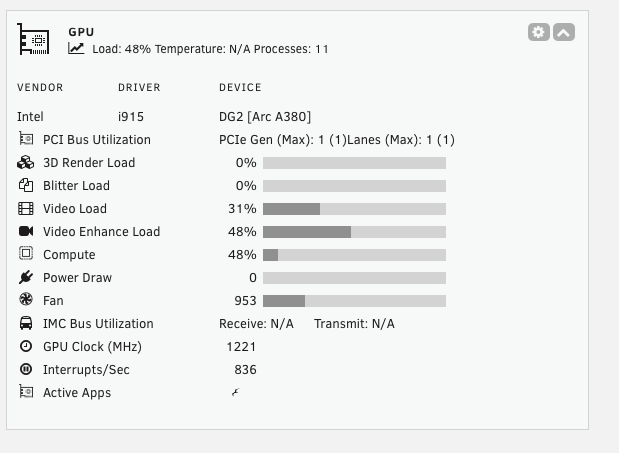
I do notice the compute bar seems inverted. Like higher compute makes the bar shrink and less compute makes it grow
-
Nice, thanks for the quick turnaround!
-
root@unraid:~# intel_gpu_top -J -n 2 [ { "period": { "duration": 46.639177, "unit": "ms" }, "frequency": { "requested": 2358.532184, "actual": 1179.266092, "unit": "MHz" }, "interrupts": { "count": 729.000857, "unit": "irq/s" }, "rc6": { "value": 28.237891, "unit": "%" }, "engines": { "Render/3D": { "busy": 0.000000, "sema": 0.000000, "wait": 0.000000, "unit": "%" }, "Blitter": { "busy": 0.000000, "sema": 0.000000, "wait": 0.000000, "unit": "%" }, "Video": { "busy": 0.000000, "sema": 0.000000, "wait": 0.000000, "unit": "%" }, "VideoEnhance": { "busy": 0.000000, "sema": 0.000000, "wait": 0.000000, "unit": "%" }, "Compute": { "busy": 0.000000, "sema": 0.000000, "wait": 0.000000, "unit": "%" } }, "clients": { "4292183874": { "name": "ffmpeg", "pid": "2783422", "memory": { "system": { "total": "28332032", "shared": "0", "resident": "28327936", "purgeable": "0", "active": "0" }, "local": { "total": "744001536", "shared": "0", "resident": "411340800", "purgeable": "262144", "active": "0" } }, "engine-classes": { "Render/3D": { "busy": "0.000000", "unit": "%" }, "Blitter": { "busy": "0.000000", "unit": "%" }, "Video": { "busy": "7.488407", "unit": "%" }, "VideoEnhance": { "busy": "0.000000", "unit": "%" }, "Compute": { "busy": "0.000000", "unit": "%" } } }, "4291768061": { "name": "ffmpeg", "pid": "3199235", "memory": { "system": { "total": "28332032", "shared": "0", "resident": "28327936", "purgeable": "0", "active": "0" }, "local": { "total": "744099840", "shared": "0", "resident": "436604928", "purgeable": "262144", "active": "0" } }, "engine-classes": { "Render/3D": { "busy": "0.000000", "unit": "%" }, "Blitter": { "busy": "0.000000", "unit": "%" }, "Video": { "busy": "7.422500", "unit": "%" }, "VideoEnhance": { "busy": "0.000000", "unit": "%" }, "Compute": { "busy": "0.000000", "unit": "%" } } }, "4292856873": { "name": "ffmpeg", "pid": "2110423", "memory": { "system": { "total": "31477760", "shared": "0", "resident": "31473664", "purgeable": "0", "active": "0" }, "local": { "total": "952610816", "shared": "0", "resident": "265269248", "purgeable": "262144", "active": "0" } }, "engine-classes": { "Render/3D": { "busy": "0.000000", "unit": "%" }, "Blitter": { "busy": "0.000000", "unit": "%" }, "Video": { "busy": "5.017866", "unit": "%" }, "VideoEnhance": { "busy": "0.000000", "unit": "%" }, "Compute": { "busy": "0.000000", "unit": "%" } } }, "4292856980": { "name": "ffmpeg", "pid": "2110316", "memory": { "system": { "total": "28332032", "shared": "0", "resident": "28327936", "purgeable": "0", "active": "0" }, "local": { "total": "750268416", "shared": "0", "resident": "405024768", "purgeable": "262144", "active": "0" } }, "engine-classes": { "Render/3D": { "busy": "0.000000", "unit": "%" }, "Blitter": { "busy": "0.000000", "unit": "%" }, "Video": { "busy": "3.709789", "unit": "%" }, "VideoEnhance": { "busy": "0.000000", "unit": "%" }, "Compute": { "busy": "0.000000", "unit": "%" } } }, "4292856780": { "name": "ffmpeg", "pid": "2110516", "memory": { "system": { "total": "28332032", "shared": "0", "resident": "28327936", "purgeable": "0", "active": "0" }, "local": { "total": "750342144", "shared": "0", "resident": "423972864", "purgeable": "262144", "active": "0" } }, "engine-classes": { "Render/3D": { "busy": "0.000000", "unit": "%" }, "Blitter": { "busy": "0.000000", "unit": "%" }, "Video": { "busy": "0.000000", "unit": "%" }, "VideoEnhance": { "busy": "0.000000", "unit": "%" }, "Compute": { "busy": "0.000000", "unit": "%" } } }, "4292856817": { "name": "ffmpeg", "pid": "2110479", "memory": { "system": { "total": "26759168", "shared": "0", "resident": "26755072", "purgeable": "0", "active": "0" }, "local": { "total": "750411776", "shared": "0", "resident": "442916864", "purgeable": "262144", "active": "0" } }, "engine-classes": { "Render/3D": { "busy": "0.000000", "unit": "%" }, "Blitter": { "busy": "0.000000", "unit": "%" }, "Video": { "busy": "0.000000", "unit": "%" }, "VideoEnhance": { "busy": "0.000000", "unit": "%" }, "Compute": { "busy": "0.000000", "unit": "%" } } }, "4292856872": { "name": "ffmpeg", "pid": "2110424", "memory": { "system": { "total": "28332032", "shared": "0", "resident": "28327936", "purgeable": "0", "active": "0" }, "local": { "total": "750489600", "shared": "0", "resident": "461869056", "purgeable": "262144", "active": "0" } }, "engine-classes": { "Render/3D": { "busy": "0.000000", "unit": "%" }, "Blitter": { "busy": "0.000000", "unit": "%" }, "Video": { "busy": "0.000000", "unit": "%" }, "VideoEnhance": { "busy": "0.000000", "unit": "%" }, "Compute": { "busy": "0.000000", "unit": "%" } } }, "4292856887": { "name": "ffmpeg", "pid": "2110409", "memory": { "system": { "total": "28332032", "shared": "0", "resident": "28327936", "purgeable": "0", "active": "0" }, "local": { "total": "750514176", "shared": "0", "resident": "468185088", "purgeable": "262144", "active": "0" } }, "engine-classes": { "Render/3D": { "busy": "0.000000", "unit": "%" }, "Blitter": { "busy": "0.000000", "unit": "%" }, "Video": { "busy": "0.000000", "unit": "%" }, "VideoEnhance": { "busy": "0.000000", "unit": "%" }, "Compute": { "busy": "0.000000", "unit": "%" } } }, "4292857652": { "name": "frigate.embeddi", "pid": "2109644", "memory": { "system": { "total": "2121728", "shared": "0", "resident": "2109440", "purgeable": "0", "active": "0" }, "local": { "total": "266358784", "shared": "0", "resident": "262361088", "purgeable": "589824", "active": "0" } }, "engine-classes": { "Render/3D": { "busy": "0.000000", "unit": "%" }, "Blitter": { "busy": "0.000000", "unit": "%" }, "Video": { "busy": "0.000000", "unit": "%" }, "VideoEnhance": { "busy": "0.000000", "unit": "%" }, "Compute": { "busy": "0.000000", "unit": "%" } } }, "4292857656": { "name": "frigate.detecto", "pid": "2109640", "memory": { "system": { "total": "2121728", "shared": "0", "resident": "2109440", "purgeable": "0", "active": "0" }, "local": { "total": "58241024", "shared": "0", "resident": "55881728", "purgeable": "589824", "active": "0" } }, "engine-classes": { "Render/3D": { "busy": "0.000000", "unit": "%" }, "Blitter": { "busy": "0.000000", "unit": "%" }, "Video": { "busy": "0.000000", "unit": "%" }, "VideoEnhance": { "busy": "0.000000", "unit": "%" }, "Compute": { "busy": "0.000000", "unit": "%" } } }, "4292857658": { "name": "frigate.detecto", "pid": "2109638", "memory": { "system": { "total": "2121728", "shared": "0", "resident": "2109440", "purgeable": "0", "active": "0" }, "local": { "total": "58241024", "shared": "0", "resident": "55881728", "purgeable": "589824", "active": "0" } }, "engine-classes": { "Render/3D": { "busy": "0.000000", "unit": "%" }, "Blitter": { "busy": "0.000000", "unit": "%" }, "Video": { "busy": "0.000000", "unit": "%" }, "VideoEnhance": { "busy": "0.000000", "unit": "%" }, "Compute": { "busy": "0.000000", "unit": "%" } } } } }, { "period": { "duration": 1033.449872, "unit": "ms" }, "frequency": { "requested": 2429.725977, "actual": 1191.155985, "unit": "MHz" }, "interrupts": { "count": 639.605285, "unit": "irq/s" }, "rc6": { "value": 26.514811, "unit": "%" }, "engines": { "Render/3D": { "busy": 0.000000, "sema": 0.000000, "wait": 0.000000, "unit": "%" }, "Blitter": { "busy": 0.000000, "sema": 0.000000, "wait": 0.000000, "unit": "%" }, "Video": { "busy": 0.000000, "sema": 0.000000, "wait": 0.000000, "unit": "%" }, "VideoEnhance": { "busy": 0.000000, "sema": 0.000000, "wait": 0.000000, "unit": "%" }, "Compute": { "busy": 0.000000, "sema": 0.000000, "wait": 0.000000, "unit": "%" } }, "clients": { "4291768061": { "name": "ffmpeg", "pid": "3199235", "memory": { "system": { "total": "28332032", "shared": "0", "resident": "28327936", "purgeable": "0", "active": "0" }, "local": { "total": "744099840", "shared": "0", "resident": "436604928", "purgeable": "262144", "active": "0" } }, "engine-classes": { "Render/3D": { "busy": "0.000000", "unit": "%" }, "Blitter": { "busy": "0.000000", "unit": "%" }, "Video": { "busy": "3.866473", "unit": "%" }, "VideoEnhance": { "busy": "34.707469", "unit": "%" }, "Compute": { "busy": "0.000000", "unit": "%" } } }, "4292183874": { "name": "ffmpeg", "pid": "2783422", "memory": { "system": { "total": "28332032", "shared": "0", "resident": "28327936", "purgeable": "0", "active": "0" }, "local": { "total": "744001536", "shared": "0", "resident": "411340800", "purgeable": "262144", "active": "0" } }, "engine-classes": { "Render/3D": { "busy": "0.000000", "unit": "%" }, "Blitter": { "busy": "0.000000", "unit": "%" }, "Video": { "busy": "3.814002", "unit": "%" }, "VideoEnhance": { "busy": "33.999871", "unit": "%" }, "Compute": { "busy": "0.000000", "unit": "%" } } }, "4292856873": { "name": "ffmpeg", "pid": "2110423", "memory": { "system": { "total": "31477760", "shared": "0", "resident": "31473664", "purgeable": "0", "active": "0" }, "local": { "total": "952610816", "shared": "0", "resident": "265269248", "purgeable": "262144", "active": "0" } }, "engine-classes": { "Render/3D": { "busy": "0.000000", "unit": "%" }, "Blitter": { "busy": "0.000000", "unit": "%" }, "Video": { "busy": "3.239327", "unit": "%" }, "VideoEnhance": { "busy": "31.685799", "unit": "%" }, "Compute": { "busy": "0.000000", "unit": "%" } } }, "4292856780": { "name": "ffmpeg", "pid": "2110516", "memory": { "system": { "total": "28332032", "shared": "0", "resident": "28327936", "purgeable": "0", "active": "0" }, "local": { "total": "750342144", "shared": "0", "resident": "423972864", "purgeable": "262144", "active": "0" } }, "engine-classes": { "Render/3D": { "busy": "0.000000", "unit": "%" }, "Blitter": { "busy": "0.000000", "unit": "%" }, "Video": { "busy": "4.141747", "unit": "%" }, "VideoEnhance": { "busy": "29.331432", "unit": "%" }, "Compute": { "busy": "0.000000", "unit": "%" } } }, "4292856980": { "name": "ffmpeg", "pid": "2110316", "memory": { "system": { "total": "28332032", "shared": "0", "resident": "28327936", "purgeable": "0", "active": "0" }, "local": { "total": "750268416", "shared": "0", "resident": "405024768", "purgeable": "262144", "active": "0" } }, "engine-classes": { "Render/3D": { "busy": "0.000000", "unit": "%" }, "Blitter": { "busy": "0.000000", "unit": "%" }, "Video": { "busy": "3.791006", "unit": "%" }, "VideoEnhance": { "busy": "23.476092", "unit": "%" }, "Compute": { "busy": "0.000000", "unit": "%" } } }, "4292856887": { "name": "ffmpeg", "pid": "2110409", "memory": { "system": { "total": "28332032", "shared": "0", "resident": "28327936", "purgeable": "0", "active": "0" }, "local": { "total": "750514176", "shared": "0", "resident": "468185088", "purgeable": "262144", "active": "0" } }, "engine-classes": { "Render/3D": { "busy": "0.000000", "unit": "%" }, "Blitter": { "busy": "0.000000", "unit": "%" }, "Video": { "busy": "4.001938", "unit": "%" }, "VideoEnhance": { "busy": "21.981841", "unit": "%" }, "Compute": { "busy": "0.000000", "unit": "%" } } }, "4292856817": { "name": "ffmpeg", "pid": "2110479", "memory": { "system": { "total": "26759168", "shared": "0", "resident": "26755072", "purgeable": "0", "active": "0" }, "local": { "total": "750411776", "shared": "0", "resident": "442916864", "purgeable": "262144", "active": "0" } }, "engine-classes": { "Render/3D": { "busy": "0.000000", "unit": "%" }, "Blitter": { "busy": "0.000000", "unit": "%" }, "Video": { "busy": "3.993424", "unit": "%" }, "VideoEnhance": { "busy": "13.675794", "unit": "%" }, "Compute": { "busy": "0.000000", "unit": "%" } } }, "4292856872": { "name": "ffmpeg", "pid": "2110424", "memory": { "system": { "total": "28332032", "shared": "0", "resident": "28327936", "purgeable": "0", "active": "0" }, "local": { "total": "750489600", "shared": "0", "resident": "461869056", "purgeable": "262144", "active": "0" } }, "engine-classes": { "Render/3D": { "busy": "0.000000", "unit": "%" }, "Blitter": { "busy": "0.000000", "unit": "%" }, "Video": { "busy": "3.178358", "unit": "%" }, "VideoEnhance": { "busy": "1.136582", "unit": "%" }, "Compute": { "busy": "0.000000", "unit": "%" } } }, "4292857656": { "name": "frigate.detecto", "pid": "2109640", "memory": { "system": { "total": "2121728", "shared": "0", "resident": "2109440", "purgeable": "0", "active": "0" }, "local": { "total": "58241024", "shared": "0", "resident": "55881728", "purgeable": "589824", "active": "0" } }, "engine-classes": { "Render/3D": { "busy": "0.000000", "unit": "%" }, "Blitter": { "busy": "0.023170", "unit": "%" }, "Video": { "busy": "0.000000", "unit": "%" }, "VideoEnhance": { "busy": "0.000000", "unit": "%" }, "Compute": { "busy": "0.885962", "unit": "%" } } }, "4292857658": { "name": "frigate.detecto", "pid": "2109638", "memory": { "system": { "total": "2121728", "shared": "0", "resident": "2109440", "purgeable": "0", "active": "0" }, "local": { "total": "58241024", "shared": "0", "resident": "55881728", "purgeable": "589824", "active": "0" } }, "engine-classes": { "Render/3D": { "busy": "0.000000", "unit": "%" }, "Blitter": { "busy": "0.015323", "unit": "%" }, "Video": { "busy": "0.000000", "unit": "%" }, "VideoEnhance": { "busy": "0.000000", "unit": "%" }, "Compute": { "busy": "0.583820", "unit": "%" } } }, "4292857652": { "name": "frigate.embeddi", "pid": "2109644", "memory": { "system": { "total": "2121728", "shared": "0", "resident": "2109440", "purgeable": "0", "active": "0" }, "local": { "total": "266358784", "shared": "0", "resident": "262361088", "purgeable": "589824", "active": "0" } }, "engine-classes": { "Render/3D": { "busy": "0.000000", "unit": "%" }, "Blitter": { "busy": "0.000000", "unit": "%" }, "Video": { "busy": "0.000000", "unit": "%" }, "VideoEnhance": { "busy": "0.000000", "unit": "%" }, "Compute": { "busy": "0.000000", "unit": "%" } } } } }]
-
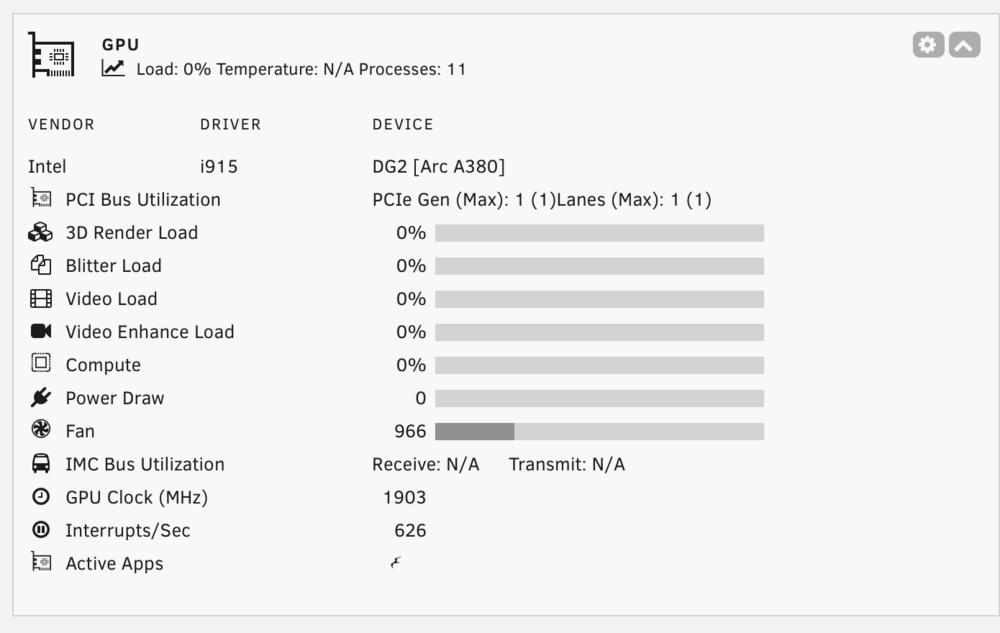
I have an intel i13500 and an intel arc a380. I have the plugin configured to pull stats from my a380. All fields besides fan, GPU Glock, interrupts, and active apps are always blank.
-
Ok, so I've now run stably on each of the TPUs (independently) on the dual edge card. Since this issue only seems to arise when using both TPUs, is there any further troubleshooting I can do, or should I assume the dual TPU card has some flaw causing this instability when both TPUs are used?
-
I was getting multiple crashes per 24 hours. Running on one TPU was stable for an entire day. Now trying with just the second TPU. If both work independently, but not together, would that point to a driver or motherboard issue? I can't imagine the magic-blue-smoke pcie adapter is the problem.
-
This is what I was thinking too. I'll enable one, run it for a bit, and see if it crashes.
-
Yes, the machine is hard powering off and then auto starting back up. I replaced the PSU last week thinking that it was a probable cause but the crashes continued. It's 850W for just: an intel i13500, LSI HBA card, 5 hard drives, 2 nvme drives, and the dual coral tpu pcie card. From my calculations, it's way overpowered for just that, right? I'm also under the impression that the coral is pretty low wattage - so the fact that not using the corals w/ frigate stops the crashes makes me think it's not PSU related. Also, I've shifted frigate to use the i13500 cpu for detection and the wattage use on the computer has increased significantly.
-
I have the syslog history through crashes. But it restarts instantly after crashing. In this example of a crash at 11:53am, this is what the syslog looked like around the crash time.

-
I've got this card: https://coral.ai/products/m2-accelerator-dual-edgetpu/ plugged into this adapter https://www.makerfabs.com/dual-edge-tpu-adapter.html?srsltid=AfmBOorFfIb0tFJk7EvTSAjgGIHqytS6y9fDgoaJakAV_RjztfuqG_Zw with a thermal pad and this heatsink: https://www.mouser.com/ProductDetail/Advanced-Thermal-Solutions/ATS-CPX040040020-115-C2-R0?qs=MLItCLRbWswyZ7Q9sz7GLA%3D%3D&countryCode=US¤cyCode=USD I've never noticed the temps get high. Are you thinking it is heating to over 100C and shutting the whole unraid machine down?
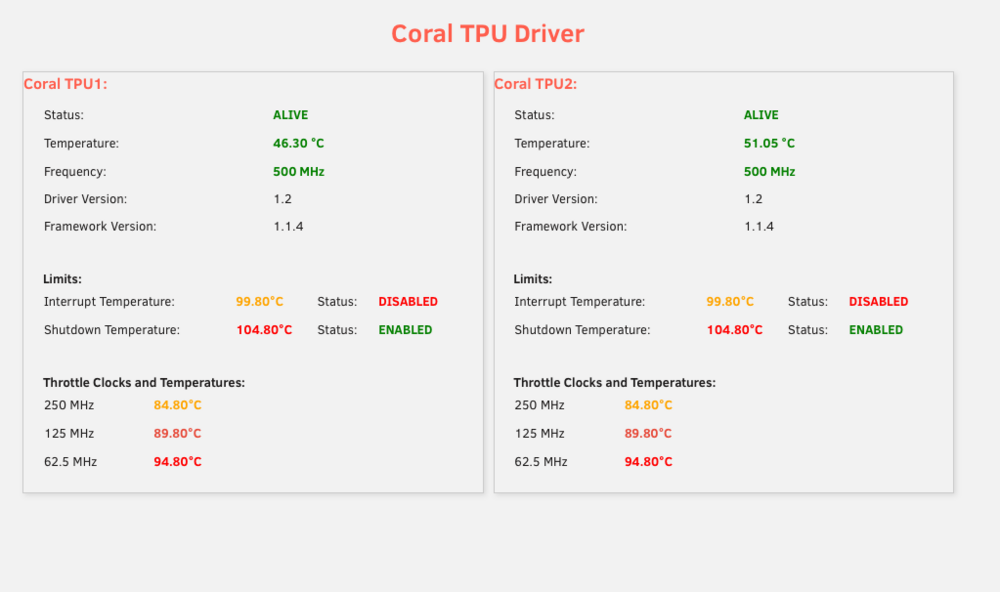
-
@ich777 I've had a working dual coral TPU w/ pcie adapter frigate setup for some time. But I've been dealing with occasional machine crashes. After replacing way too much hardware, I've narrowed the problem down to the Frigate container, only when I enable the two TPUs as detectors. I've posted frigate related stuff here: https://github.com/blakeblackshear/frigate/discussions/18038 and Unraid related stuff here: The only somewhat interesting thing in the syslog is the write back errors: I saw you post earlier to "enable above 4G Decoding in your BIOS". I'm going to check that. Could that be causing this issue? Or something else?

-
@JorgeB I think I’ve narrowed it down. I run Frigate and use a dual coral tpu m.2 plugged into a pcie adapter. This all works great and shows up in unraid. However, if I disable the TPUs from being used in Frigate (and use my cpu instead), unraid appears stable. The only thing in the logs are those ‘write back’ errors/warnings. Any idea what might be happening?
-
I replaced the power supply yesterday and the issue happened today. The only hardware that hasn't been replaced at this point is: CPU (i13500) Motherboard (Gigabyte B760M) LSI HBA card (LSI 9201-8i) Dual Coral M.2 card Temperatures on the system are never over 140F, so I don't think its related to overheating. Are there instances of docker containers causing entire system crashes? I'd think that the isolated nature of a container would prevent that, but this feels more and more like its software related given the amount of hardware I have replaced..
-
Ok. That bug has been around awhile, was just hoping it was somehow related. (here is the history on that bug, hopefully it gets included in an update:
-
Yes. I can fix it by going into settings, disabled docker, and re-enabling docker.
-
@JorgeB One other weird thing that I just thought of. When the system comes back up after the crash and unclean shutdown, my networking table is always jacked up. For some reason, the shim disappears on restart. Below is the routing table before and after these crashes. Any chance this is related? Before crash: After crash and systems comes back online:


-
I'd have to buy another one. It would be a weird failure as its only 18 months old and overpowered for my build: https://www.corsair.com/us/en/p/psu/cp-9020180-na/rmx-series-rm850x-850-watt-80-plus-gold-certified-fully-modular-psu-cp-9020180-na
-
I have been troubleshooting random crashes/restarts (and the associated unclean shutdowns) for months. This has led to me guessing at root cause and replacing the two NVME cache drives, all the RAM, and my UPS. More recently, I have had the syslog on since April 9th, and had the following shutdowns: 4/10/25 @ 8:58pm 4/20/25 @ 2:03am 4/30/25 @ 3:13pm The system is critical in the operation of our house (DNS, security cameras, HA for home automation, Plex, etc.), so I can't run it in NAS mode for 10+ days (one of the common suggestions for troubleshooting further). I'm tempted to replace the power supply, or maybe screw around with the bios, but I'm running out of ideas. Thoughts? Diags and syslog for the past 21 days attached. unraid-diagnostics-20250430-1735.zip syslog-192.168.1.198.log
-
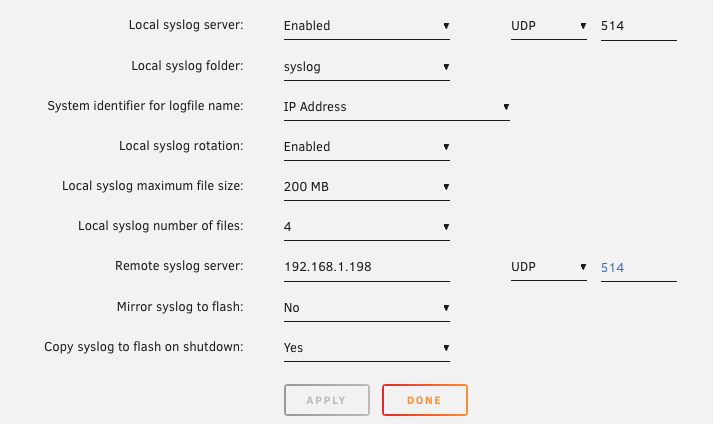
I've been having random unclean shutdowns, so I have syslog server running (settings below). After an unclean reboot, the syslog file that is being written appears overwritten (meaning, anything before the shutdown is gone). I expected the syslog to just add another line and continue the file. Any advice?
-
Those warnings stem from a dual coral tpu pci card I’m using with frigate. Not sure if they are normal. I’ll open a thread there as well. is there any additional logging I can be doing? I was hoping the logs would be more verbose. Like I remember weird things in the past when my battery backup gets close to end of life - but I don’t want to go replace RAM, battery backup, power supply, etc without some indication.
-
I've triggered two shutdowns (to replace the nvme drive and later go back and add a heatsink), neither were unclean from what I remember. All the shutdowns that are concerning me, like the one this morning around 830am, are not being triggered by me.
-
Thanks for taking a look. I have been mirroring the syslog. Attached. syslog-127.0.0.1.log
-
I've been dealing with unclean shutdowns since moving to unpaid 7. I assumed they were coincidental with unraid 7 release timing, so I replaced an older (and notorious) nvme drive this week thinking that might solve the issue. It did not. Wondering if anyone sees any memory issues or any other hardware indications on what might be going on in my diags. They are attached. Thanks in advance unraid-diagnostics-20250317-0902.zip
-
Since upgrading to beta 4, I've been opening the unraid web UI to see that there was an unclean shutdown and a parity check is in progress. I have no scheduled or planned reboots, so this must mean that unraid is completely crashing and restarting. Prior to this beta, I had never seen this happen and would have multi-month uptime. unraid-diagnostics-20241201-1739.zip
-
I just used this as well. I was thinking I was in for a very long night and this solved it.







