




maxx8888
Members
-
Joined
-
Last visited
-
ERROR: MISCONF Redis is configured to save RDB snapshots, but it is currently not able to persist on disk. Commands that may modify the data set are disabled, because this instance is configured to report errors during writes if RDB snapshotting fails (stop-writes-on-bgsave-error option). Please check the Redis logs for details about the RDB error. I'm getting this Error few times a second, after the Docker is running around 5minutes. At that point also the Web Interface is becoming really slow. No idea what's wrong 😕
-
Ok, After an Uptime of around an week, again complete crash. Syslog is not really showing something special again. Crash happend at 14:11:20. I guess this is a Hardware Problem, since i was pressing reset Button first, but no BIOS Post, after power cycle, normal Startup again. Decided to change Memory Dimm slot order and also reseated them. Syslog: Feb 8 08:01:50 NAS emhttpd: read SMART /dev/sdk Feb 8 08:01:50 NAS emhttpd: read SMART /dev/sdg Feb 8 08:01:50 NAS emhttpd: read SMART /dev/sde Feb 8 08:24:40 NAS emhttpd: spinning down /dev/sdk Feb 8 08:24:40 NAS emhttpd: spinning down /dev/sdg Feb 8 08:24:40 NAS emhttpd: spinning down /dev/sde Feb 8 09:09:50 NAS kernel: x86/split lock detection: #AC: CPU 1/KVM/10285 took a split_lock trap at address: 0xfffff803da45ab8e Feb 8 10:23:36 NAS kernel: x86/split lock detection: #AC: CPU 0/KVM/10284 took a split_lock trap at address: 0xfffff803da5c40a5 Feb 8 12:11:06 NAS emhttpd: read SMART /dev/sdk Feb 8 12:11:06 NAS emhttpd: read SMART /dev/sdg Feb 8 12:11:18 NAS emhttpd: read SMART /dev/sde Feb 8 12:27:20 NAS emhttpd: spinning down /dev/sdk Feb 8 12:27:20 NAS emhttpd: spinning down /dev/sdg Feb 8 12:27:20 NAS emhttpd: spinning down /dev/sde Feb 8 13:41:36 NAS kernel: x86/split lock detection: #AC: CPU 0/KVM/10284 took a split_lock trap at address: 0xfffff803da5c40a5 Feb 8 20:00:37 NAS kernel: mdcmd (36): set md_write_method 1 Feb 8 20:00:37 NAS kernel: Feb 8 20:00:37 NAS cache_dirs: Arguments=-l off Feb 8 20:00:37 NAS cache_dirs: Max Scan Secs=10, Min Scan Secs=1 Feb 8 20:00:37 NAS cache_dirs: Scan Type=adaptive Feb 8 20:00:37 NAS cache_dirs: Min Scan Depth=4 Feb 8 20:00:37 NAS cache_dirs: Max Scan Depth=none Feb 8 20:00:37 NAS cache_dirs: Use Command='find -noleaf' Feb 8 20:00:37 NAS cache_dirs: ---------- Caching Directories ---------------
-
Yep, same for me. I've decided to keep XMP Profile off also hoping that this helps to keep system stable (and without RAM Errors). For iGPU i was hoping to be able to attach it to a WindowsVM were i have Plex running, but so far this doesn't work 😕 gvt-d seems also to be supported only till 10th gen. Would be great if something similar will be availabe for newer CPUs in future...
-
So I've stopped my Win11 VMs, Errors where reduced a lot, but there are 2x 2k12 Servers still running with CPU pinning. Those pinned cores are now still reporting the Error. Not sure if this Message causes Issues at all, or if it is only Information. I'll keep Unraid running without Win11 VMs for the next week to see if it crashes again...
-
Windows 11 is running.
-
Hi, I've build a new Unraid Setup also: ASUS PRIME Z690M-PLUS D4 i7-12700K 128 GiB DDR4 I've not added dev/dri to any container but had an sudden crash after 4 days uptime as well. Not sure if it is related to 12th gen or something else. Nothing special found in syslog before/after crash. But during runtime i've a lot of these entries: Jan 26 06:38:52 NAS kernel: x86/split lock detection: #AC: CPU 2/KVM/9930 took a split_lock trap at address: 0xfffff802027c20a5 And also found this: Jan 26 06:58:35 NAS kernel: #011[00] BAD 00 ff ff ff ff ff ff 00 ff ff ff ff ff ff ff ff Jan 26 06:58:35 NAS kernel: #011[00] BAD ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff Jan 26 06:58:35 NAS kernel: #011[00] BAD ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff Jan 26 06:58:35 NAS kernel: #011[00] BAD ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff Jan 26 06:58:35 NAS kernel: #011[00] BAD ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff Jan 26 06:58:35 NAS kernel: #011[00] BAD ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff Jan 26 06:58:35 NAS kernel: #011[00] BAD ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff Jan 26 06:58:35 NAS kernel: #011[00] BAD ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff
-
Not sure if this was asked earlier already but is this Plugin also working with Intel 12th Gen? I'm owning a 12700k and would like to attach iGPU to a Windows VM for Plex transcoding...
-
Hi, I'm pretty new to Unraid, so maybe just a stupid question here... I'm currently transfering a large amount of Data from old Nas to Unraid. When i start adding new Shares, during a File Copy is ongoing, the File Operation is interrupted. Is that the "wanted" behaviour? That means everytime i'm changing something on the Shares, all connected Users will loose there ongoing Transfers? For me this would be a huge drawback...
-
Beim "Balance" Knopf kann man die Art des Balance aussuchen. Habe hier Raid1 gewählt und nochmals gebalanced. Jetzt ist der Status: Data, RAID1: total=549.00GiB, used=545.65GiB System, RAID1: total=64.00MiB, used=112.00KiB Metadata, RAID1: total=2.00GiB, used=259.11MiB GlobalReserve, single: total=213.22MiB, used=0.00B Ist das so OK? Was ist die Global Reserve? Die Shares auf dem NVME zeigen alle "some or all files unprotected"...
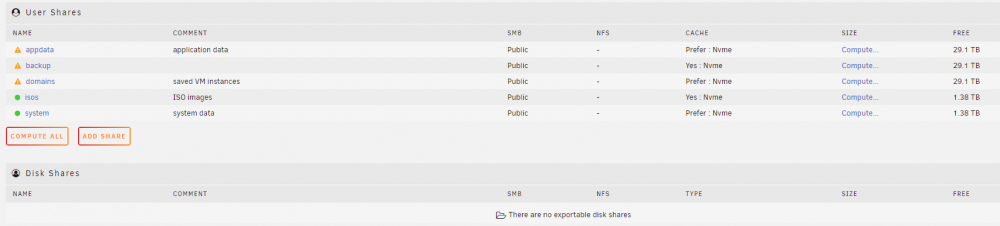
-
Hi, Bin begeisterter aber blutiger Anfänger mit Unraid. Einige VMs und Docker laufen schon, Cache Drive (2x 1,92TB Ironwolf M.2) halb voll. Da mir die Daten wichtig sind wollte ich testen wie ob BTRFS Raid1 tut wie es soll und habe den Server heruntergefahren und eine SSD rausgezogen. Hochgefahren und alle Daten perfekt noch immer verfügbar. Server wieder herunter gefahren, 2. Platte wieder reingesteckt und BTRFS hat perfekt angefangen wieder zu spiegeln. Hab dann aber während das spiegeln noch gelaufen die Arrays gestoppt, weil ich auf den anderen Platten noch was umstellen wollte. Nach dem nächsten Start, sind zwar meine Daten am Cache noch immer verfügbar aber auf einmal als Single Drives. btrfs filesystem df: Data, single: total=436.00GiB, used=435.40GiB System, single: total=32.00MiB, used=80.00KiB Metadata, single: total=1.00GiB, used=203.75MiB GlobalReserve, single: total=188.70MiB, used=0.00B Keine Ahnung warum das passiert ist, aber nachdem alles noch da ist, halb so schlimm. Kann ich das filesystem wieder irgendwie zurück stellen auf Raid1 ohne das ich jetzt alle Daten wieder runterlöschen und neu anlegen muß? Vielen Dank für eure Hilfe!
-
I was able to help myself :-). Since VM coming from Qnap is legacy boot (non UEFI), BIOS needed to be changed to "SeaBIOS" and everthing come up fine.
-
Hi, Just trying to setup my first brandnew Unraid server. Till now i was working with Qnap and have several VMs running on it (Windows + Linux). I've tried to convert according to following Thread: https://forums.unraid.net/topic/111436-eine-vm-ova-in-unraid-importieren/ qemu-img convert dateiname.vmdk deinwunschname.qcow2 -O qcow2 However, it seems like Unraid tries to start that Image in UEFI Mode, or Image is not bootable after starting VM. Is there a procedure on how-to move VMs? Thanks a lot!
-
Thanks a lot for your Support Guide, actually it speeded up my setup (Quick Boot Problem). For iGPU usage i'm currently trying to add first VM. I was wondering how you setup your memory for stable Operation. Are you using XMP Profile? Wouldn't be default (Auto) setup be more stable to use?
