




Phredwerd
Members
-
Joined
-
Last visited
Everything posted by Phredwerd
-
Is there a way to disable having to sign in to see all the recipes? Mealie 0.5.6 allowed this and I could easily share mealie with people without needing for a login.
-
After a bit of fiddling, I did get this to work and mealie V1 now has my recipes. Thanks!
-
RIght sorry, I wrote that quite late and was tired so I missed a detail. As I mentioned, I was getting that bad gateway error with 0.5.6 so I uninstalled it thinking it had to do with the reverse proxy I have setup to access it. I re-installed it via the container templates list but it still wouldn't work even when accessing it without the reverse proxy so I deleted it from my templates and went to find another version that would work but I can't find any. In the link above: https://nightly.mealie.io/documentation/getting-started/migrating-to-mealie-v1/ It mentions needing to be able to access my old mealie install to export the data but the issue is, I can't! So I need to find a working 0.5.6 build I can install to export the data.
-
I was running 0.5.6 but recently I started getting Bad Gateway 502 when I tried loading it up. I have all my recipes there and I need a way to export those so that I can migrate to 1.0. I can't seem to find v0.5.6 on the Unraid App store anymore. What are my options here? I really don't want to loose all those recipes!
-
Hi there, I've set this docker up in my server and configured it to use Digital Ocean following this template: https://github.com/qdm12/ddns-updater/blob/master/docs/digitalocean.md The config.json file: { "settings": [ { "provider": "digitalocean", "domain": "mydomain.ca", "host": "@", "token": "<my token>", "ip_version": "ipv4" } ] } Docker starts fine and the WebUI output shows this: But when I got look at my DNS Panel in Digital Ocean, no A record gets set. Even 12 hours later. Here is the contents from updates.json: { "records": [ { "domain": "mydomain.ca", "host": "@", "ips": [ { "ip": "<my ip>", "time": "2024-01-25T23:43:37.728524444-05:00" }, { "ip": "<my ip>", "time": "2024-01-26T00:21:35.437335624-05:00" } ] } ] } Everything looks right. Did I miss something? Thanks!

-
Is there one in particular you can recommend that has worked for you?
-
Is there anyway to change how the USB adaptor in this device presents the ID? That's really annoying that it does that.
-
Yeeahh I was thinking this may have been the culprit. Both drives involved in this issue are encased in an Orico brand hard drive enclosure. This one in particular: https://www.orico.com.cn/product/detail/397.html
-
It doesn't matter which USB port I plug either drive into, they both present with the same device ID. Even if I change the mount point this won't work. So drive one's mount point is Video and the other drive is Space. If I plug in the first drive, it will mount as Video but if I then plug in the second drive whilst the first is also plugged in, Video disappears and Space takes it's place. They are vastly different drives too! One is a 500GB Toshiba I lifted out of on an old mac book and the other a 1GB Hitachi. It's really bizarre.
-
I've got a bit of an odd scenario. I've somehow got two separate USB drives that I plug in to do backups with that both have the same disk identification numbers. How is that even possible and how can I change the ID of one of the drives?
-
Ok it seems that the Nebula theme (installed via the Customizer plugin) was causing this issue as well as this error: Warning: filemtime(): stat failed for /var/www/app/assets/css/app.min.css in /var/www/app/app/Helper/AssetHelper.php on line 41 Showing up at the top of any page you were on. I guess it must be outdated? Too bad. I liked that theme.
-
Is there a way to revert the sub-task organization back to how it used to be as opposed to the way it's setup now with stacking? I preferred it with the "X" moving icon, the drop down and the name of the task be all in the same line.

-
This appears at the top of any page I'm on Warning: filemtime(): stat failed for /var/www/app/assets/css/app.min.css in /var/www/app/app/Helper/AssetHelper.php on line 41 I tried clearing the sessions table, stopping and restarting the kanban app, docker itself and even re-installed kanban but that didn't seem to work so not sure what else can be done?
-
What strikes me odd as that setup persisted for a good 18 months through multiple parity checks. Then the one I ran in May one showed those errors. I ran another check with corrections enabled and it resulted in 0 errors but this still persists. Also, I have my unraid setup such that it sends me a telegram every morning at 12:20 AM and it constantly shows up as FAIL because of this. Kind of annoying more than anything at this point.

-
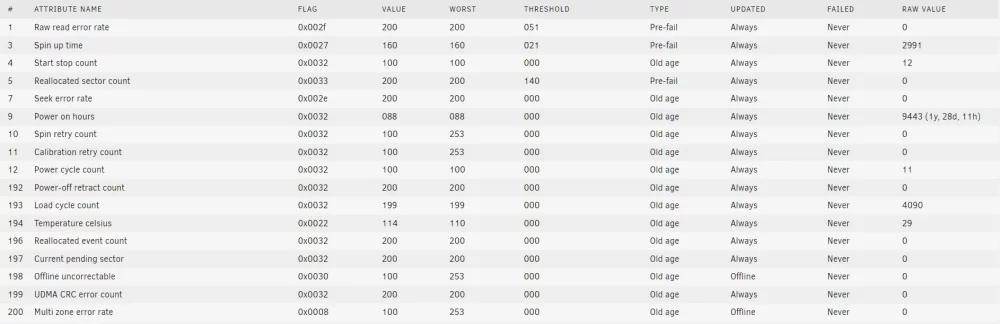
Hi everyone, so my server has an 8TB parity drive with date on 3TB, 2TB and 2TB drives. All running XFS. Last month, I ran a parity check and the second drive showed 336 errors. SMART short self-test resulted in no errors. The drive attributes seem pretty solid as well. This is the drive log (server name redacted): May 11 01:27:42 <ServerName> kernel: ata6.00: exception Emask 0x0 SAct 0x1fc000 SErr 0x0 action 0x0 May 11 01:27:42 <ServerName> kernel: ata6.00: irq_stat 0x40000008 May 11 01:27:42 <ServerName> kernel: ata6.00: failed command: READ FPDMA QUEUED May 11 01:27:42 <ServerName> kernel: ata6.00: cmd 60/40:70:28:09:80/05:00:4b:00:00/40 tag 14 ncq dma 688128 in May 11 01:27:42 <ServerName> kernel: ata6.00: status: { DRDY ERR } May 11 01:27:42 <ServerName> kernel: ata6.00: error: { UNC } May 11 01:27:42 <ServerName> kernel: ata6.00: configured for UDMA/133 May 11 01:27:42 <ServerName> kernel: sd 6:0:0:0: [sde] tag#14 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=11s May 11 01:27:42 <ServerName> kernel: sd 6:0:0:0: [sde] tag#14 Sense Key : 0x3 [current] May 11 01:27:42 <ServerName> kernel: sd 6:0:0:0: [sde] tag#14 ASC=0x11 ASCQ=0x4 May 11 01:27:42 <ServerName> kernel: sd 6:0:0:0: [sde] tag#14 CDB: opcode=0x28 28 00 4b 80 09 28 00 05 40 00 May 11 01:27:42 <ServerName> kernel: I/O error, dev sde, sector 1266682824 op 0x0:(READ) flags 0x0 phys_seg 84 prio class 0 May 11 01:27:42 <ServerName> kernel: ata6: EH complete May 11 01:27:51 <ServerName> kernel: ata6.00: exception Emask 0x0 SAct 0x40c0001f SErr 0x0 action 0x0 May 11 01:27:51 <ServerName> kernel: ata6.00: irq_stat 0x40000008 May 11 01:27:51 <ServerName> kernel: ata6.00: failed command: READ FPDMA QUEUED May 11 01:27:51 <ServerName> kernel: ata6.00: cmd 60/40:20:e8:0e:80/05:00:4b:00:00/40 tag 4 ncq dma 688128 in May 11 01:27:51 <ServerName> kernel: ata6.00: status: { DRDY ERR } May 11 01:27:51 <ServerName> kernel: ata6.00: error: { UNC } May 11 01:27:51 <ServerName> kernel: ata6.00: configured for UDMA/133 May 11 01:27:51 <ServerName> kernel: sd 6:0:0:0: [sde] tag#4 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=20s May 11 01:27:51 <ServerName> kernel: sd 6:0:0:0: [sde] tag#4 Sense Key : 0x3 [current] May 11 01:27:51 <ServerName> kernel: sd 6:0:0:0: [sde] tag#4 ASC=0x11 ASCQ=0x4 May 11 01:27:51 <ServerName> kernel: sd 6:0:0:0: [sde] tag#4 CDB: opcode=0x28 28 00 4b 80 0e e8 00 05 40 00 May 11 01:27:51 <ServerName> kernel: I/O error, dev sde, sector 1266684232 op 0x0:(READ) flags 0x0 phys_seg 92 prio class 0 May 11 01:27:51 <ServerName> kernel: ata6: EH complete May 11 01:27:58 <ServerName> kernel: ata6.00: exception Emask 0x0 SAct 0x600fe20 SErr 0x0 action 0x0 May 11 01:27:58 <ServerName> kernel: ata6.00: irq_stat 0x40000008 May 11 01:27:58 <ServerName> kernel: ata6.00: failed command: READ FPDMA QUEUED May 11 01:27:58 <ServerName> kernel: ata6.00: cmd 60/40:60:28:14:80/05:00:4b:00:00/40 tag 12 ncq dma 688128 in May 11 01:27:58 <ServerName> kernel: ata6.00: status: { DRDY ERR } May 11 01:27:58 <ServerName> kernel: ata6.00: error: { UNC } May 11 01:27:58 <ServerName> kernel: ata6.00: configured for UDMA/133 May 11 01:27:58 <ServerName> kernel: sd 6:0:0:0: [sde] tag#12 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=DRIVER_OK cmd_age=27s May 11 01:27:58 <ServerName> kernel: sd 6:0:0:0: [sde] tag#12 Sense Key : 0x3 [current] May 11 01:27:58 <ServerName> kernel: sd 6:0:0:0: [sde] tag#12 ASC=0x11 ASCQ=0x4 May 11 01:27:58 <ServerName> kernel: sd 6:0:0:0: [sde] tag#12 CDB: opcode=0x28 28 00 4b 80 14 28 00 05 40 00 May 11 01:27:58 <ServerName> kernel: I/O error, dev sde, sector 1266685032 op 0x0:(READ) flags 0x0 phys_seg 160 prio class 0 May 11 01:27:58 <ServerName> kernel: ata6: EH complete May 18 00:24:32 <ServerName> emhttpd: read SMART /dev/sde May 18 00:44:58 <ServerName> emhttpd: read SMART /dev/sde I then followed the steps outlined here in that I stopped the array and restarted in maintenance mode. I ran the xfs_repair GUI command with -v as the parameters which, according to the docs "tests and reports, making changes when necessary". I can't seem to find anything bad in the log file nor recommendations. Which is listed here: Phase 1 - find and verify superblock... - reporting progress in intervals of 15 minutes - block cache size set to 359968 entries Phase 2 - using internal log - zero log... zero_log: head block 108140 tail block 108140 - 19:55:38: zeroing log - 29809 of 29809 blocks done - scan filesystem freespace and inode maps... - 19:55:39: scanning filesystem freespace - 32 of 32 allocation groups done - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - 19:55:39: scanning agi unlinked lists - 32 of 32 allocation groups done - process known inodes and perform inode discovery... - agno = 30 - agno = 15 - agno = 0 - agno = 1 - agno = 31 - agno = 16 - agno = 2 - agno = 17 - agno = 18 - agno = 19 - agno = 20 - agno = 21 - agno = 22 - agno = 23 - agno = 24 - agno = 25 - agno = 26 - agno = 3 - agno = 4 - agno = 5 - agno = 27 - agno = 28 - agno = 29 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - agno = 13 - agno = 14 - 19:55:51: process known inodes and inode discovery - 24256 of 24256 inodes done - process newly discovered inodes... - 19:55:51: process newly discovered inodes - 32 of 32 allocation groups done Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - 19:55:51: setting up duplicate extent list - 32 of 32 allocation groups done - check for inodes claiming duplicate blocks... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - agno = 13 - agno = 14 - agno = 15 - agno = 16 - agno = 17 - agno = 18 - agno = 19 - agno = 20 - agno = 21 - agno = 22 - agno = 23 - agno = 24 - agno = 25 - agno = 26 - agno = 27 - agno = 28 - agno = 29 - agno = 30 - agno = 31 - 19:55:51: check for inodes claiming duplicate blocks - 24256 of 24256 inodes done Phase 5 - rebuild AG headers and trees... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - agno = 13 - agno = 14 - agno = 15 - agno = 16 - agno = 17 - agno = 18 - agno = 19 - agno = 20 - agno = 21 - agno = 22 - agno = 23 - agno = 24 - agno = 25 - agno = 26 - agno = 27 - agno = 28 - agno = 29 - agno = 30 - agno = 31 - 19:55:53: rebuild AG headers and trees - 32 of 32 allocation groups done - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - agno = 0 - agno = 15 - agno = 30 - agno = 1 - agno = 16 - agno = 17 - agno = 2 - agno = 31 - agno = 18 - agno = 19 - agno = 3 - agno = 20 - agno = 4 - agno = 5 - agno = 21 - agno = 6 - agno = 22 - agno = 7 - agno = 8 - agno = 23 - agno = 9 - agno = 24 - agno = 25 - agno = 10 - agno = 11 - agno = 26 - agno = 12 - agno = 27 - agno = 13 - agno = 14 - agno = 28 - agno = 29 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... - 19:55:57: verify and correct link counts - 32 of 32 allocation groups done XFS_REPAIR Summary Fri May 26 19:55:59 2023 Phase Start End Duration Phase 1: 05/26 19:55:37 05/26 19:55:38 1 second Phase 2: 05/26 19:55:38 05/26 19:55:39 1 second Phase 3: 05/26 19:55:39 05/26 19:55:51 12 seconds Phase 4: 05/26 19:55:51 05/26 19:55:51 Phase 5: 05/26 19:55:51 05/26 19:55:53 2 seconds Phase 6: 05/26 19:55:53 05/26 19:55:57 4 seconds Phase 7: 05/26 19:55:57 05/26 19:55:57 Total run time: 20 seconds done I then restarted the array in normal mode, and still saw the drive showing 336 errors just as before. I then ran parity check again with the 'Write corrections to parity' option checked. It resulted in no errors BUT the 336 errors still persist so not sure where to go next with this. The only thing I can think of is to run xfs_repair with the -L option which clears the log but not sure what side effects that command brings. Any insight?! Thanks!

-
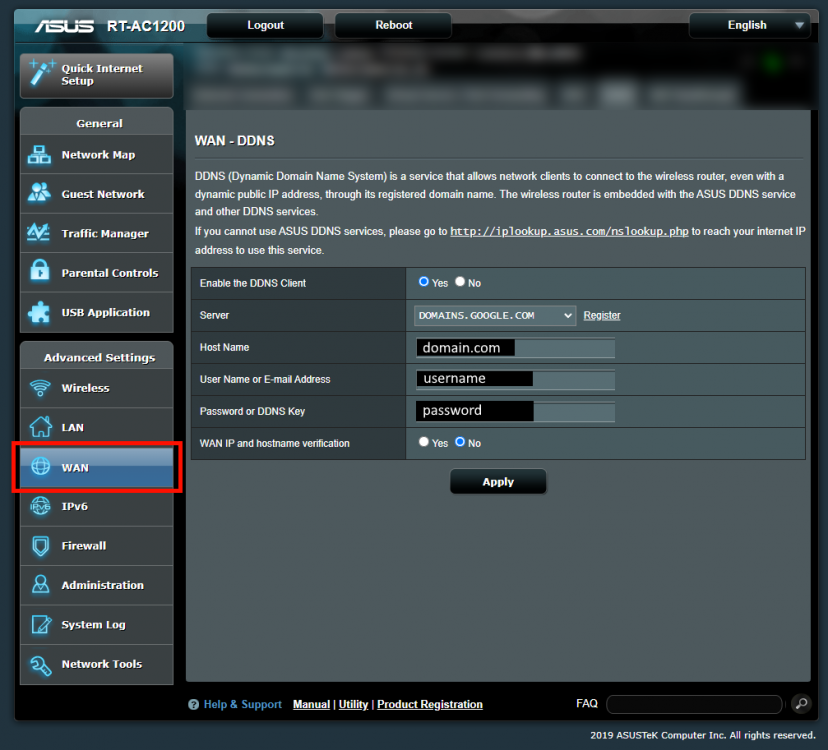
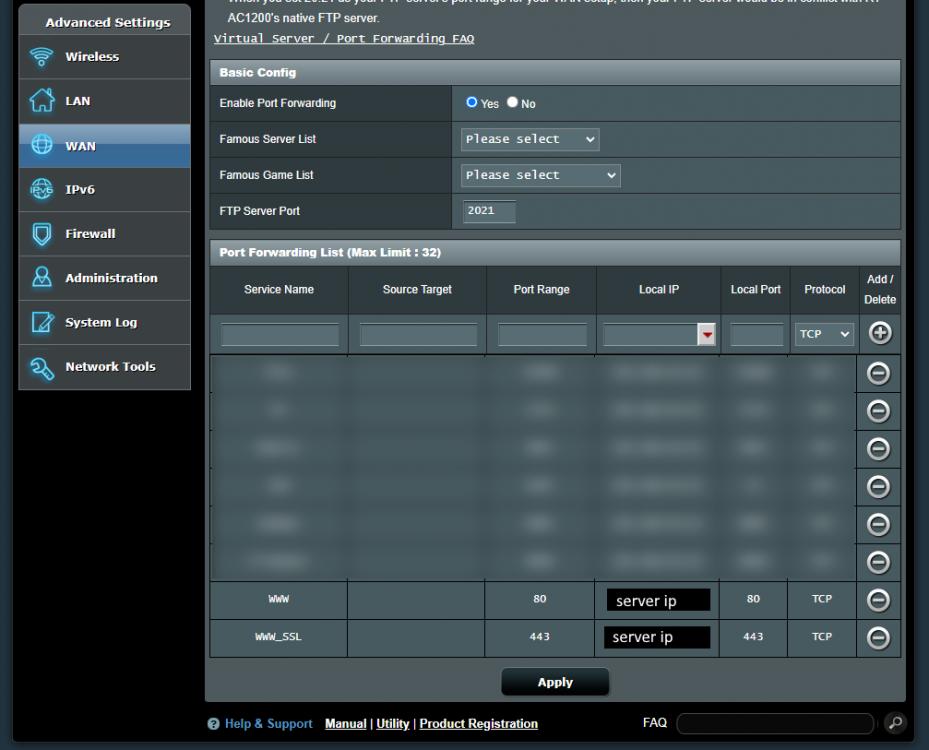
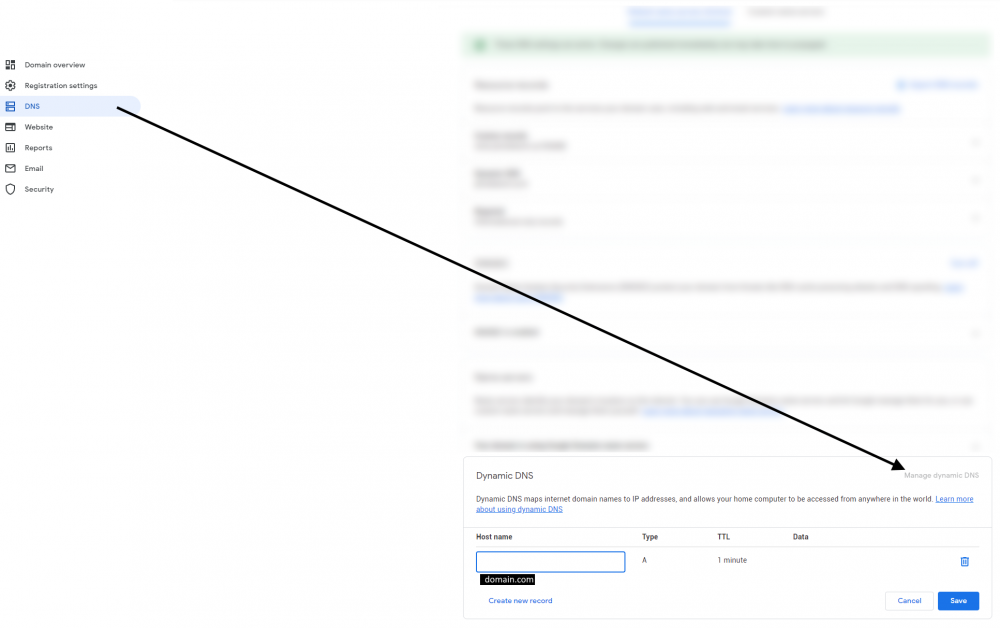
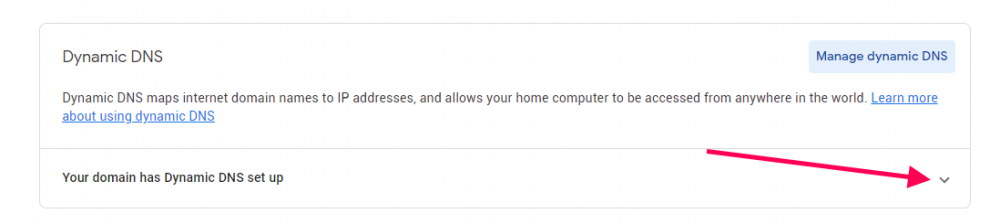
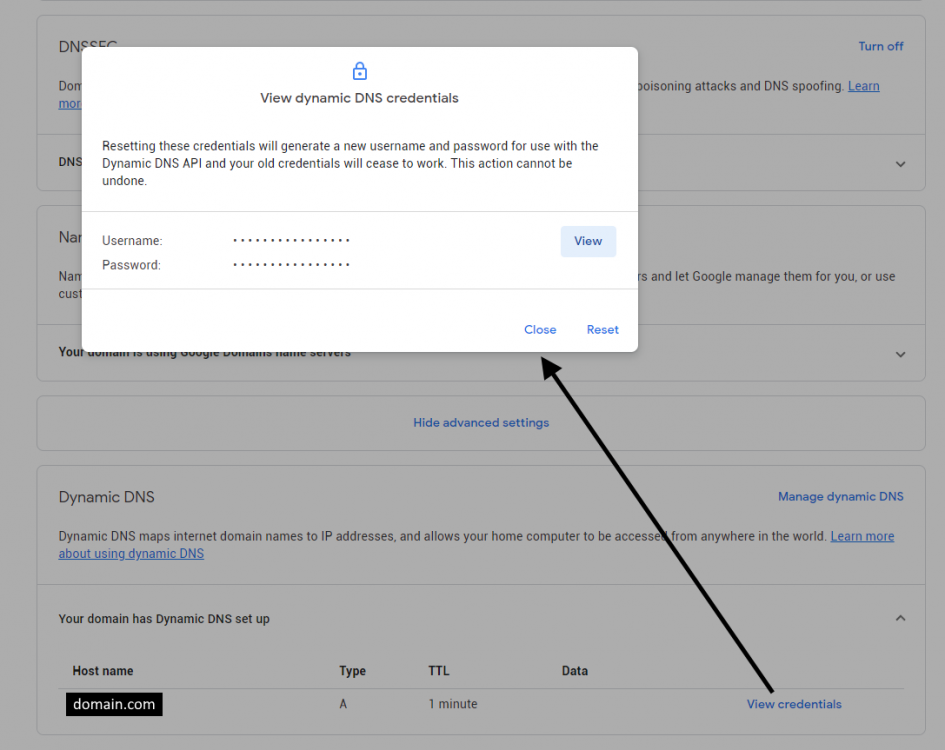
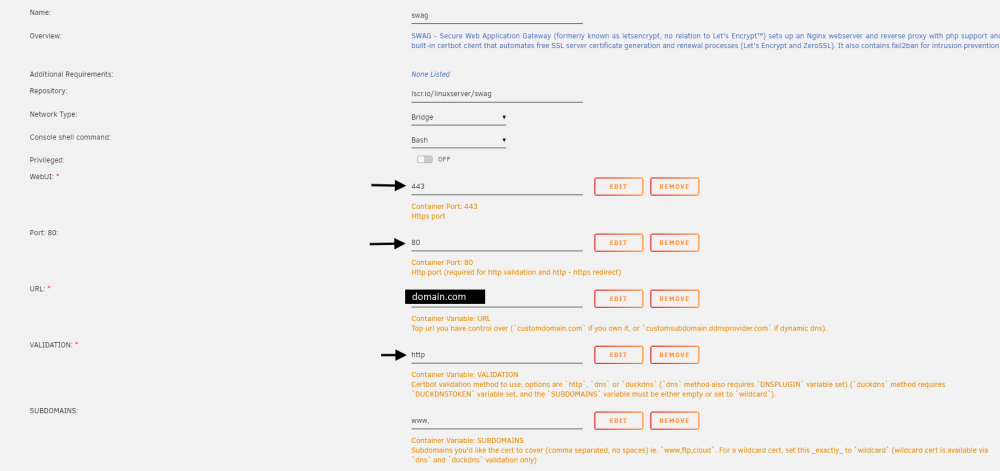
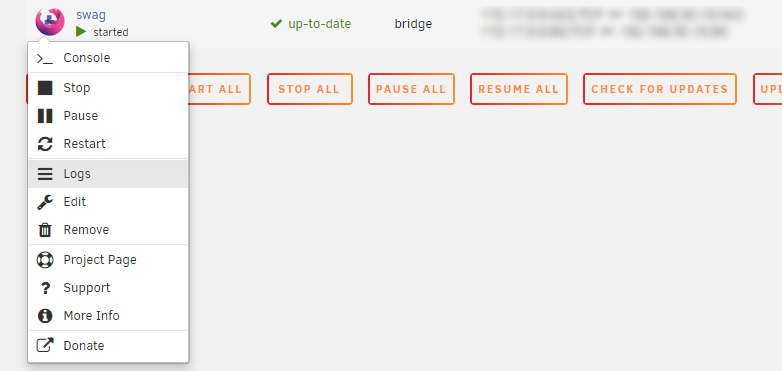
Hey everyone, I just recently setup a personal website running on my Unraid server with Google Domains complete with SSL courtesy of Let's Encrypt. It took a little while to figure this all out but maybe someone else would like to know what I did. Ok first off, I've got the Asus RT-AC1200 which allows for DDNS support via Google Domains which means you can register your domain there (for cheap) and have your domain.com point to your router. I think a lot of the other higher end ASUS routers do this. No idea what the other brands do. The first thing you'll need to do is head on over there and get your domain. Once purchased, you'll need to add a CNAME record so that www.domain.com resolves to domain.com. You can do that under the DNS menu up top. Next you need to click on "Manage Dynamic DNS" way down at the bottom of the page to add a DDNS entry. It should default to your domain.com so hit save and you're done. Once you hit save, it'll close and then you need to click on the little upside down triangle to expand the DDNS details. From there, click on credentials which will present you with a username/password combo which you will then need to enter into the DDNS screen on your router. On my router, this is done in the WAN section. Enable the DDNS client, select DOMAINS.GOOGLE.COM then enter in your domain name along with the user name/password combo you got from Google Domains in the previous step. I kept WAN IP and hostname verification off as that was the default. Hit apply. Next, you'll need to ensure port forwarding is setup for both HTTP (80) and HTTPS (443) to point to your Unraid server inside your LAN. One thing to note is that the Unraid GUI by default uses port 80, so you'll either have to change which port Unraid uses in the settings (which is what I did) OR map HTTP to an internal port to something other than 80 in your router settings and then ensure your docker server listens to that port. I did it the first way (moved Unraid GUI to use another port) as in the SWAG docs, it said it needed port 80. I didn't try the other way but really.. it should work right? At this point, if you spin up a simple NGINX docker, type in your domain.com, you should see the nginx welcome page. Ensure both domain.com and www.domain.com work! This is what that first step way above back in Google Domain should resolve and is key in getting the SSL working properly below. Ok last step is to get our site working with SSL and SWAG. Luckily SWAG includes an app called CertBot which does all the hard stuff for you, you just need to set a few details and you're off. First remove your test nginx server if you set one up above and from the apps section, install the SWAG server. When filling in the details, ensure you enter in your domain.com and select http for validation. If you used different ports in the port forwarding step on your router, you will enter them here. From what I've understood, the dns method doesn't work with Google Domains but HTTP will work just fine, From there hit apply and let the docker setup do it's thing. Once done, the docker will start up. Click on the SWAG icon and select logs to see what the server is doing. What you want to see is something along the lines of: ``` Using Let's Encrypt as the cert provider SUBDOMAINS entered, processing SUBDOMAINS entered, processing Sub-domains processed are: -d www.domain.com No e-mail address entered or address invalid http validation is selected Certificate exists; parameters unchanged; starting nginx The cert does not expire within the next day. Letting the cron script handle the renewal attempts overnight (2:08am). [custom-init] no custom files found exiting... [ls.io-init] done. Server ready ``` If server IS INDEED ready, you should be able to hit https://www.domain.com and see the nginx welcome page and you are ready to start building up your site all running off your own home server. Hope this helps and hopefully the pro's can weigh in on this as well! The End

-
Is there an easy way to enable SSL?
-
So I have Kanboard running on another system that uses MySql but I see this installation option uses SQLite. I guess to migrate over I'd need to setup a MySQL docker and then somehow configure the Kanboard install to use MySql? Or is there an easier way or is that even possible?












