




handycapp
Members
-
Joined
-
Last visited
-
Hi folks, this issue has taken me an inordinate amount of time to identify. My environment: Unraid OS: 7.2.3 VM Type: UEFI (OVMF) Guest OS: Debian 12 (but issue is hypervisor‑level, not guest‑specific) Hypervisor: KVM/QEMU via libvirt Storage: vdisk1.img on /mnt/user/domains/<vmname>/ UEFI VMs are the default for most modern OSes. Cloning is essential for: staging changes testing upgrades templating disaster recovery snapshot‑style workflows At present, cloning a UEFI VM requires manual intervention in multiple areas of the XML and filesystem, which is error‑prone and not discoverable. Summary of the Problem Cloning a UEFI VM via the Unraid VM Manager produces a VM definition that is not bootable, even when: The vdisk is valid The vdisk path is correct No passthrough devices are assigned No ISO is attached Boot order is correct BIOS type matches the source VM The cloned VM always drops into OVMF BIOS and cannot locate a bootloader. This behaviour is fully reproducible. Root Cause Analysis After detailed inspection of the generated XML and libvirt runtime state, the following issues are present in every clone: 1. Missing NVRAM (VARS) file for the cloned VM The source VM has: Code <nvram>/etc/libvirt/qemu/nvram/<UUID>_VARS-pure-efi.fd</nvram> The cloned VM’s XML references a different UUID, but no corresponding VARS file is created in: Code /etc/libvirt/qemu/nvram/ As a result, OVMF has: no EFI variables no boot entries no BootOrder no saved boot manager state This alone is sufficient to cause a drop into BIOS. Manual fix (works): Code cp /etc/libvirt/qemu/nvram/<sourceUUID>_VARS-pure-efi.fd \ /etc/libvirt/qemu/nvram/<cloneUUID>_VARS-pure-efi.fd Then update the <nvram> path in the clone’s XML. 2. Inherited passthrough <hostdev> blocks The clone inherits all <hostdev> entries from the source VM, including GPU audio functions, USB controllers, NVMe devices, etc. If the source VM is running, the clone cannot start because the PCI devices are already bound to vfio-pci by the source domain. Even when removed in the GUI, the XML may still contain stale <hostdev> blocks. 3. Inherited ISO <disk device='cdrom'> block Even when the GUI shows “None” for OS Install ISO, the cloned XML still contains: Code <disk type='file' device='cdrom'> <source file='/mnt/user/isos/<installer>.iso'/> </disk> This causes QEMU to prioritize the CD-ROM device unless boot order is explicitly overridden. 4. Boot order is not reset The clone inherits the source VM’s boot order, which may prioritize: CD-ROM Network boot Nonexistent devices Combined with missing NVRAM, this guarantees a BIOS drop. 5. vdisk path is correct, but clone still fails to boot Even when pointing the clone directly at the source VM’s known‑good vdisk, the clone still drops into BIOS. This confirms the issue is not related to: vdisk corruption block‑commit snapshot chain copy failure The failure is entirely in the VM definition (XML + missing NVRAM). Steps to Reproduce (Minimal) Create a UEFI VM (OVMF) Shut it down Use Clone in VM Manager Manually copy the vdisk to the clone’s folder Start the cloned VM Result: VM enters OVMF BIOS and cannot boot. Expected Behaviour Cloning a VM should: Generate a new NVRAM (VARS) file Remove passthrough devices unless explicitly selected Remove ISO references Reset boot order to vdisk first Produce a bootable clone without manual XML editing Actual Behaviour Cloning produces a VM that: Has no NVRAM file Contains stale passthrough hostdevs Contains stale ISO references Has incorrect boot order Cannot boot even with a known‑good vdisk Questions for Lime Technology: Is the absence of automatic NVRAM generation for cloned UEFI VMs a known limitation in 7.2.3? Is there an officially supported method to clone UEFI VMs without manual XML/NVRAM intervention? Is automatic NVRAM creation planned for a future 7.x release? Should the VM Manager remove inherited hostdev and ISO blocks when cloning? Is the VM Manager rewrite (mentioned in prior forum posts) expected to address these issues? sagittarius-diagnostics-20260107-2100.zip
-
Doh!😆Thanks Kilrah very muchly. Thought I was going bananas,cheers😄
-
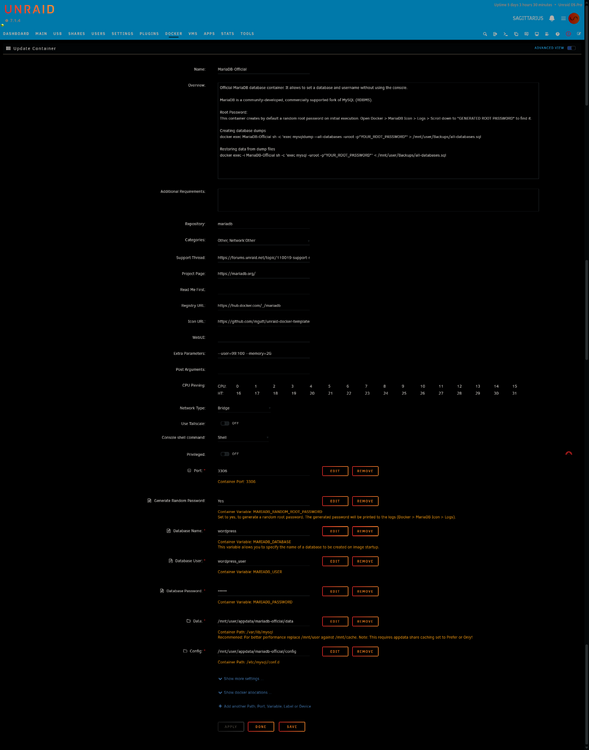
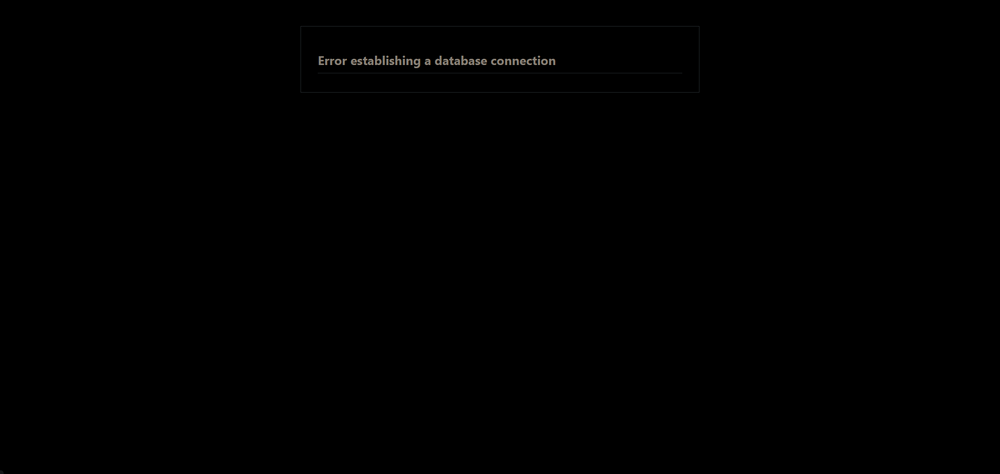
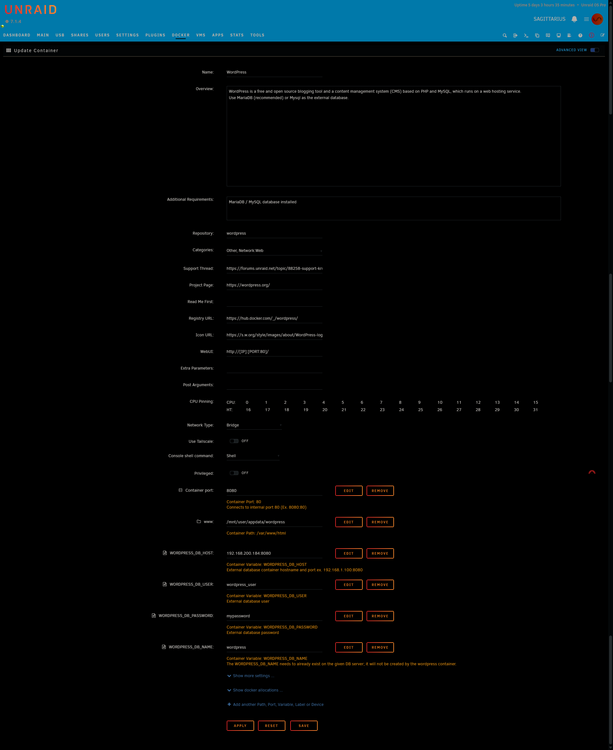
Summary: Wordpress not connecting to mariadb, and I'm not getting anywhere yet. Newly installed MariaDB.Official and Wordpress dockers today. Wordpress will not launch from the machine's local network IP address:8080 I've attached logs of both dockers and their configs, as well as diagnostics. I can't see any glaring errors in configs, mariadb log perhaps? Diagnostics file for docker is empty, and other dockers appear to be fully functional. Any help would be greatly appreciated... 2025-10-06 local-logterminal-MariaDB-Official.log.txt 2025-10-06 logterminal-WordPress.log.log.txt sagittarius-diagnostics-20251006-1847.zip
-
Ah yes 7.2, thanks Jorge. Yes, so far so good. Running long enough now with both drives parity sync, couple of Dockers and VMs running under load. No notifications or errors pertaining to drives whatsover ... (yet). Cheers
-
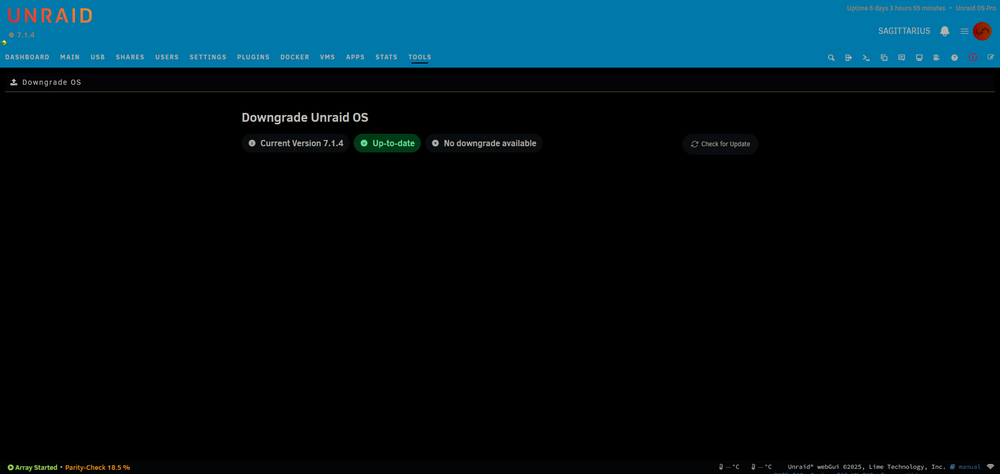
Hi Jorge, it seems the cause of USB disconnections and system crashes was a faulty drive (#13). Once that was removed and -> New Config => system appears stable 😀 So haven't gone to 7.1.5 beta yet. Downgrades however weren't available to select?
-
Yes, the USB driver and resource limitations are not ideal. Yet, I've had the same setup for years with 2 NUC models and never had these issues before, albeit with 4 fewer drives & no drive enclosure. Currently it's a non-critical backup server, it's worth testing it with the beta and may go back versions until stability is evident. Cheers Jorge.
-
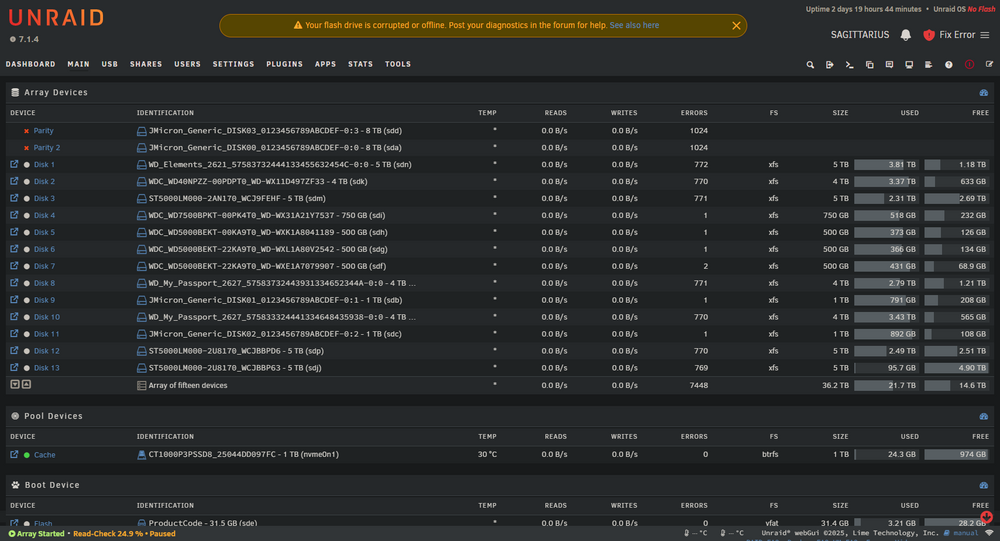
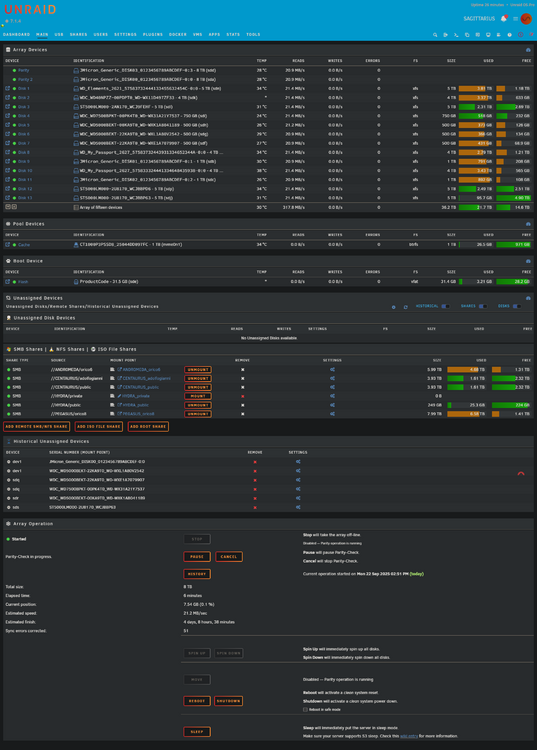
Ok... interesting, it's happened again Jorge. Overnight all drives now with read errors, flash drive unreadable ... diags attached. unsuccessful stop via GUI stop via console -> emcmd cmdStop=Stop -> no indication of array stopping neither from GUI nor console. no option but to powercycle. On rebooting and array start, system seems ok. No read errors, just parity check running ... diags attached. So, the next troubleshooting stage is an upgrade to Unraid 7.2 beta. sagittarius-diagnostics-20250922-1403.zip sagittarius-diagnostics-20250922-1454.zip
-
Thanks Jorge, @ console nginx stop and start fixes the issue and am monitoring system with Netdata docker to confirm causes. Yes, if it happens again overnight, I'll update from Tools > Update OS after another flash backup and parity disk 2 sync finishes. Very much appreciate the support Jorge😊 Cheers
-
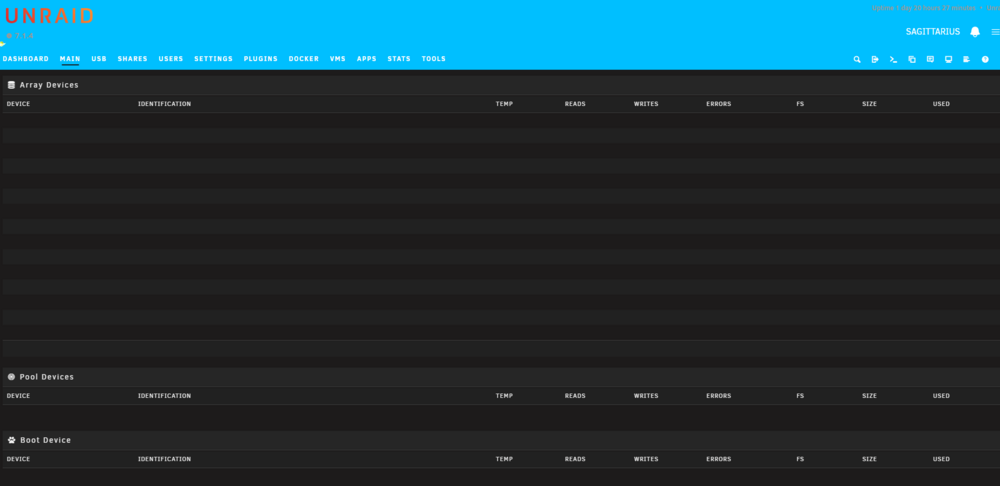
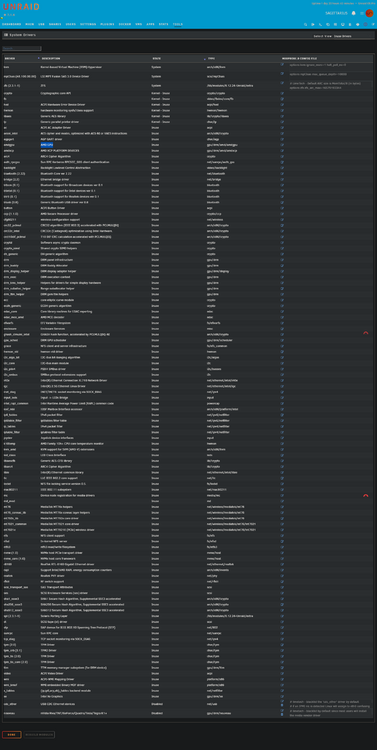
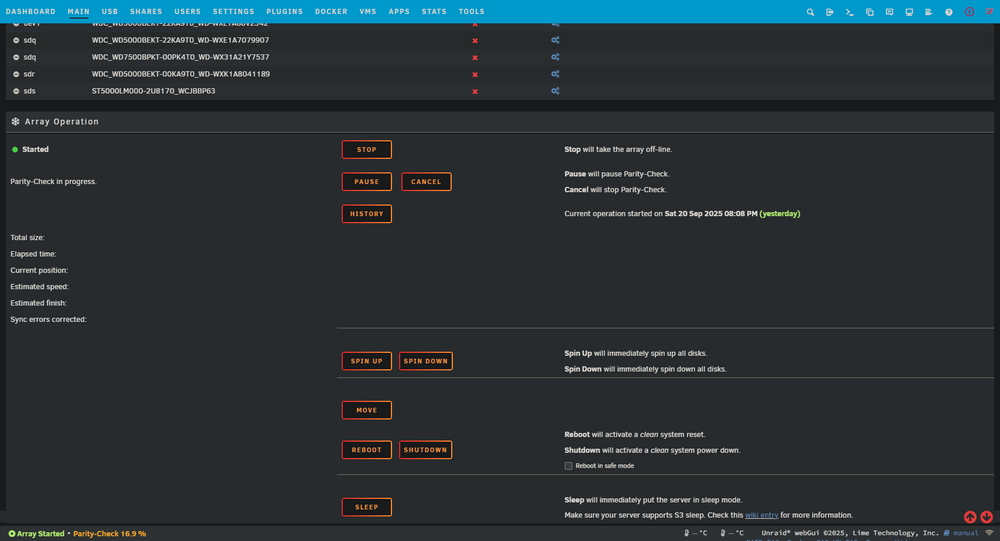
Interesting development Jorge. The system seemed stable and was rebuilding as expected but overnight the display of Main view is blank and have tested with several devices and browsers, all showing the same thing as per attached screenshot. Other GUI views such as Dashboard, Plugins, Settings etc display as normal, and the Parity rebuilding at the bottom end of Main view (attached) suggests it still running, although system log at time 6:25:40 shows this nginx error: Sep 21 06:25:40 SAGITTARIUS nginx: 2025/09/21 06:25:40 [error] 17238#17238: MEMSTORE:01: force-reaping msg with refcount 1 On searching for this error i found this description and possible causes/solutions: The error MEMSTORE:00: force-reaping msg with refcount 1 typically indicates a memory management issue in Unraid, often related to Nginx or the Nchan module. This can occur when shared memory resources are exhausted or improperly released. Possible Causes Shared Memory Exhaustion: Insufficient memory allocated for Nchan or other shared memory operations. Improper Resource Cleanup: Messages or channels not being properly released, leading to lingering references. High System Load: Excessive traffic or resource usage causing instability. 1. Increase Shared Memory Allocation Adjust the nchan_max_reserved_memory parameter in your Nginx configuration to allocate more memory for Nchan. Example Configuration Update: nchan_max_reserved_memory 256M; Restart Nginx after making changes: /etc/rc.d/rc.nginx restart 2. Debugging and Restarting Services If the issue persists, restart Nginx to clear any lingering memory issues: /etc/rc.d/rc.nginx reload 3. Check System Logs and Resources Monitor system logs (/var/log/nginx/error.log) and resource usage using tools like top or htop to identify bottlenecks. 4. Update Unraid and Plugins Ensure you are running the latest version of Unraid and its plugins, as updates often include bug fixes for such issues. 5. Reduce System Load If high traffic is causing the problem, consider optimizing your configuration or scaling resources. By following these steps, you can address the "force-reaping msg with refcount 1" error and improve system stability. Fix common problems finds nothing of concern. I've attached in-use system drivers' screenshot, Diags, dmesg. log, graphql-api log and system log. Checking the nginx.conf nchan shared memory value -> already set at 256M http { ## # Basic Settings ## # Hide nginx version information. server_tokens off; # Define the MIME types for files. include /etc/nginx/mime.types; default_type application/octet-stream; # Shared memory slab pre-allocated for Nchan. # default is 128M nchan_shared_memory_size 256M; # How long to allow each connection to stay idle; longer values are better # for each individual client, particularly for SSL, but means that worker # connections are tied up longer. (Default: 65) keepalive_timeout 20; Re: Disk 13 was new and as such console> du -h -d 1 /x shows 0 /x sagittarius-diagnostics-20250921-1458.zip sagittarius-syslog-20250921-0505.zip dmesg.txt graphql-api.log
-
Ok, thanks Jorge. Disk 13 mounted /x and browsable but no data actualy there as it never completed rebuilding the disk in the array due to the usb uasp driver issue. Disk 6 mounted /x and was browsable with data as expected. I will now execute the new config as suggested. Cheers
-
~# sgdisk -o -a 8 -n 1:32K:0 /dev/sdj The operation has completed successfully. root@SAGITTARIUS:~# blkid /dev/sdj1 /dev/sdj1: UUID="5bc5fd60-401f-49a2-b8ec-bedab02890f6" BLOCK_SIZE="512" TYPE="xfs" PARTUUID="37e727ec-a367-4c51-a072-9672fff29dbe"
-
/dev/sdj1: PARTUUID="8f3eb9c1-3c4c-4b5a-a783-078375cb002c"
-
Let's try that again sagittarius-diagnostics-20250919-2039.zip
-
Ok diags posted thanks Jorgesagittarius-diagnostics-20250918-1811.zip
-
Now if I do /dev/sdg (the new assignment) instead of /dev/sdj (the original assignment) then ~# sgdisk -o -a 8 -n 1:1M:0 /dev/sdg *************************************************************** Found invalid GPT and valid MBR; converting MBR to GPT format in memory. *************************************************************** Warning! Secondary partition table overlaps the last partition by 33 blocks! You will need to delete this partition or resize it in another utility. Non-GPT disk; not saving changes. Use -g to override. The GUID overlaps by 33 blocks. If i use -g override, I don't think it would change the fact it's no longer being recognised as a Seatay device and the wrong drive issue remains. I guess in that scenario would you agree that I then have to do an array reset with Tools>New Config and select "Preserve current assignments: All" ??












