




128bytes
Members
-
Joined
-
Last visited
Everything posted by 128bytes
-
The bottom of preclear status report has a typo of genereated rather then generated #################################################################################################### # Unraid Server Preclear of disk ZXA12345 # # Cycle 1 of 1, partition start on sector 64. # # # .... # # # # #################################################################################################### # Report genereated on: July 15, 2025 at 13:52:42 # ####################################################################################################
-
Actually for me on 7.1.4 it does NOT specify there is a replacement plugin available: Deprecated plugin file.activity.plg This plugin has been deprecated and should no longer be used due to the following reason(s): This plugin is unknown to Community Applications. It is highly advised to uninstall this and reinstall the replacement file.activity plugin available within Apps While this plugin should still be functional, it is not recommended to continue to use it. Deprecated plugin open.files.plg This plugin has been deprecated and should no longer be used due to the following reason(s): This plugin is unknown to Community Applications. It is highly advised to uninstall this and reinstall the replacement open files plugin available within Apps While this plugin should still be functional, it is not recommended to continue to use it
-
What cmd would you like me to run on it?
-
Ive reported the padding with zeroes error before for Chrome, Im now getting it for PhotoPrism also. Woudl be great if this can be looked at as it appears in this forum for a while already. tar creation failed! Tar said: tar: /mnt/user/appdata/ferdium/.config/Ferdium/Partitions/service-1954dbfc-c6e4-49e9-8564-8e96ad85444f/Cache/Cache_Data/012cb887f079a2f9_0: File shrank by 520 bytes; padding with zeros tar creation failed! Tar said: tar: /mnt/user/appdata/ferdium/.config/Ferdium/Partitions/service-1954dbfc-c6e4-49e9-8564-8e96ad85444f/Cache/Cache_Data/012cb887f079a2f9_0: File shrank by 520 bytes; padding with zeros tar creation failed! Tar said: tar: /mnt/user/appdata/ferdium/.config/Ferdium/Partitions/service-1954dbfc-c6e4-49e9-8564-8e96ad85444f/Cache/Cache_Data/012cb887f079a2f9_0: File shrank by 520 bytes; padding with zeros Its worth noting Ferdium and Chrome are not even running in the first place...
-
Can you give example what u have? Just doesnt work for... /appdata/icons/ground7_unraid-animated-svgs/Always%20Animate/downloads.svg
-
Is there a way to reference a local icon instead of internet URL? Is it possible to have multiple rows without full expanding?? i.e. If my folder has 6+ things in it, only 5 or 6 show making it not obvious what's in there. would love to have a second 'minimized' row.
-
I'm also getting padding with zeros error. This container is not even started, and the mapped path is not in use for any other docker container [05.04.2025 12:44:44][ℹ️][ferdium] No stopping needed for ferdium: Not started! [05.04.2025 12:44:44][debug][ferdium] Not executing script: Not set! [05.04.2025 12:44:44][debug][ferdium] Backup ferdium - Container Volumeinfo: Array ( [0] => /mnt/user/appdata/ferdium:/config:rw ) [05.04.2025 12:44:44][debug][ferdium] usorted volumes: Array ( [0] => /mnt/user/appdata/ferdium ) [05.04.2025 12:44:44][ℹ️][ferdium] Should NOT backup external volumes, sanitizing them... [05.04.2025 12:44:44][debug][ferdium] Volume '/mnt/user/appdata/ferdium' IS within AppdataPath '/mnt/user/appdata'! [05.04.2025 12:44:44][ℹ️][ferdium] Calculated volumes to back up: /mnt/user/appdata/ferdium [05.04.2025 12:44:44][debug][ferdium] Target archive: /mnt/user/appdata-disks/CommunityApplicationsAppdataBackup/ab_20250405_110002/ferdium.tar [05.04.2025 12:44:44][debug][ferdium] Generated tar command: -c -P -f '/mnt/user/appdata-disks/CommunityApplicationsAppdataBackup/ab_20250405_110002/ferdium.tar' '/mnt/user/appdata/ferdium' [05.04.2025 12:44:44][ℹ️][ferdium] Backing up ferdium... [05.04.2025 12:45:12][debug][ferdium] Tar out: tar: /mnt/user/appdata/ferdium/.config/Ferdium/Partitions/service-1954dbfc-c6e4-49e9-8564-8e96ad85444f/Cache/Cache_Data/012cb887f079a2f9_0: File shrank by 520 bytes; padding with zeros [05.04.2025 12:45:12][❌][ferdium] tar creation failed! Tar said: tar: /mnt/user/appdata/ferdium/.config/Ferdium/Partitions/service-1954dbfc-c6e4-49e9-8564-8e96ad85444f/Cache/Cache_Data/012cb887f079a2f9_0: File shrank by 520 bytes; padding with zeros [05.04.2025 12:45:29][debug][ferdium] lsof(/mnt/user/appdata/ferdium) Array ( ) [05.04.2025 12:45:29][debug][ferdium] Not executing script: Not set! [05.04.2025 12:45:29][ℹ️][ferdium] Installing planned update for ferdium... [05.04.2025 12:45:40][ℹ️][ferdium] Starting ferdium is being ignored, because it was not started before (or should not be started).
-
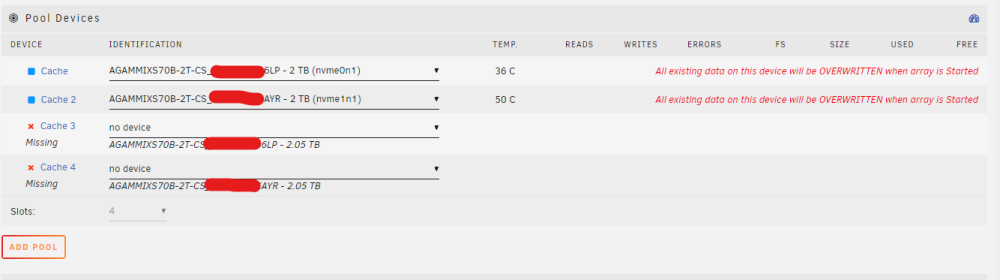
It doesn't appear so, I get quite a nice red warning All existing data on this device will be OVERWRITTEN when array is Started bridge-diagnostics-20231023-1030.zip
-
Thank you they were removed, However now the NVMes are listed as Cache 3 and Cache 4. How can I move them up to 0 and 1?
-
I've upgraded my system from 2 sata ssds to 2 nvme ssds. When I started up the array I added the 2 nvmes to the same pool as the existing 2 satas. i.e. there are now 4 drives in the pool. As far as I can tell they are raid 1. Clicking cache says: Data, RAID1: total=206.00GiB, used=204.18GiB System, RAID1: total=32.00MiB, used=48.00KiB Metadata, RAID1: total=2.00GiB, used=1.14GiB GlobalReserve, single: total=341.97MiB, used=0.00B No balance found on '/mnt/cache' Current usage ratio: 99.1 % --- No Balance required I want to remove the 2 satas. I thought I could just stop array and says pool has 2 disks but I can't lower it. So what's the procedure to simply remove the drives and let it 'rebalance' (I think) to just the 2 nvmes? bridge-diagnostics-20231022-1536.zip
-
Yes I did maintenance just to keep it offline for now. I'm saying the message sent though implies the rebuild started.
-
Also, bug report (maybe just bad wording?): I started in maintenance mode and did the unassign/assign and the notifications tell me its being reconstructed even though I didnt hit sync yet. Event: Unraid Disk 3 message Subject: Notice [BRIDGE] - Disk 3, is being reconstructed and is available for normal operation Description: WDC_WD100EMAZ-00WJTA0_JEGW40YN (sdd) Importance: normal Event: Unraid Disk 5 message Subject: Notice [BRIDGE] - Disk 5, is being reconstructed and is available for normal operation Description: WDC_WD100EMAZ-00WJTA0_JEGW1ADN (sde) Importance: normal bridge-diagnostics-20231018-1311.zip
-
1) This is xfs_repair below, just wanted to make sure seems ok to you. 2) Parity main bottleneck is drives right? I plan on upgrading the CPU on this (3rd gen i7 3770k to 12th gen i5-12600K 6p4e), just wanted to know if I should bother doing the upgrade first. Phase 1 - find and verify superblock... - block cache size set to 1419048 entries Phase 2 - using internal log - zero log... Log inconsistent (didn't find previous header) failed to find log head zero_log: cannot find log head/tail (xlog_find_tail=5) - scan filesystem freespace and inode maps... clearing needsrepair flag and regenerating metadata - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 1 - agno = 4 - agno = 0 - agno = 3 - agno = 5 - agno = 6 - agno = 7 - agno = 2 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 Phase 5 - rebuild AG headers and trees... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - agno = 4 - agno = 5 - agno = 6 - agno = 7 - agno = 8 - agno = 9 - agno = 10 - agno = 11 - agno = 12 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... Maximum metadata LSN (6:207268) is ahead of log (1:2). Format log to cycle 9. XFS_REPAIR Summary Wed Oct 18 12:23:00 2023 Phase Start End Duration Phase 1: 10/18 12:18:08 10/18 12:18:08 Phase 2: 10/18 12:18:08 10/18 12:19:10 1 minute, 2 seconds Phase 3: 10/18 12:19:10 10/18 12:19:18 8 seconds Phase 4: 10/18 12:19:18 10/18 12:19:18 Phase 5: 10/18 12:19:18 10/18 12:19:19 1 second Phase 6: 10/18 12:19:19 10/18 12:19:26 7 seconds Phase 7: 10/18 12:19:26 10/18 12:19:26 Total run time: 1 minute, 18 seconds done bridge-diagnostics-20231018-1302.zip
-
Completed with no errors! (Guess the old power supply is garbage) UI hasn't changed, I still have: Disk 1 Unmountable DIsk 3 disabled Disk 5 disabled And my option by rebuilt parity is still just Read-Check. bridge-diagnostics-20231018-1147.zip
-
So Read-Check is about to finish, 0 errors so far. Assuming that completes without errors, what's the next step?
-
So to confirm you'd recommend I should try diff PSU/cables and then rerun Read-Check?
-
I have 5 disks (14TB & 10TB) and dual parity (18TB). i7-3770K, 32GB RAM, on a UPS etc... Over the weekend I've had 1 disk get corrupted, then 2 disks get disabled. Timeline (roughly): 10/6/2023: Parity check running 10/7/2023: Presumably around here errors started happening as I have bunch of emails from AppdataBackup failing Description: Array has 3 disks with read errors Importance: warning Disk 1 - WDC_WD140EDGZ-11B1PA0_Y5KYWNNC (sdi) (errors 885744) Disk 3 - WDC_WD100EMAZ-00WJTA0_JEGW40YN (sdh) (errors 885744) Disk 5 - WDC_WD100EMAZ-00WJTA0_JEGW1ADN (sdg) (errors 2048) 10/8/2023 ~4AM (diagnostics attached before next reboot): * **disk1 (WDC_WD140EDGZ-11B1PA0_Y5KYWNNC) is disabled** * **disk5 (WDC_WD100EMAZ-00WJTA0_JEGW1ADN) is disabled** * **disk1 (WDC_WD140EDGZ-11B1PA0_Y5KYWNNC) has read errors** * **disk3 (WDC_WD100EMAZ-00WJTA0_JEGW40YN) has read errors** * **disk5 (WDC_WD100EMAZ-00WJTA0_JEGW1ADN) has read errors** * **/var/log is getting full (currently 100 % used)** * **Unable to write to disk1** 10/8/2023 9:30PM: * **disk1 (WDC_WD140EDGZ-11B1PA0_Y5KYWNNC) is disabled** * **disk5 (WDC_WD100EMAZ-00WJTA0_JEGW1ADN) is disabled** Disk 3 - WDC_WD100EMAZ-00WJTA0_JEGW40YN (sde) (errors 108928) 10/8/2023 10PM: I pull out disk1 and swap for another in case I mess something up Disk 1, is being reconstructed and is available for normal operation Data-Rebuild started 10/9/2023 12AM: Parity - ST18000NE000-2YY101_ZR54LMDX (sdc) - active 45 C [OK] Parity 2 - ST18000NM000J-2TV103_ZR56TDY7 (sdb) - active 45 C [OK] Disk 1 - WDC_WD140EDGZ-11B2DA2_2CHDSP1P (sdk) - active 34 C [DISK INVALID] Disk 2 - WDC_WD140EDGZ-11B1PA0_Y6G0EEUC (sdh) - active 37 C [OK] Disk 3 - WDC_WD100EMAZ-00WJTA0_JEGW40YN (sde) - active 33 C (disk has read errors) [NOK] Disk 4 - ST10000DM0004-2GR11L_ZJV6AXZB (sdd) - active 33 C (disk has read errors) [NOK] Disk 5 - WDC_WD100EMAZ-00WJTA0_JEGW1ADN (sdf) - active 30 C [DISK DSBL] Cache - Samsung_SSD_860_EVO_250GB_S59WNMFN703104R (sdi) - active 41 C [OK] Cache 2 - CT1000MX500SSD1_2307E6ABC2BB (sdj) - active 34 C [OK] Also note the DISK INVALID issue, seemingly need an XFS_REPAIR. I attempted that on previous disk before pulling it out and just trying to do parity rebuild. 10/12/2023 1:45AM Parity done: Disk 1 returned to normal operation Description: WDC_WD140EDGZ-11B2DA2_2CHDSP1P (sdk) Data-Rebuild finished (3299065 errors) Description: Duration: 3 days, 3 hours, 20 minutes, 25 seconds. Average speed: 51.6 MB/s <NOTE: STILL HAVE Unmountable: Unsupported or no file system for Disk 1> 10/12/2023 2AM start reconstruction on disk5: Disk 5, is being reconstructed and is available for normal operation Description: WDC_WD100EMAZ-00WJTA0_JEGW1ADN (sdf) Event: Unraid Data-Rebuild 10/13/2023 2AM: Disk 5 in error state (disk dsbl) Description: WDC_WD100EMAZ-00WJTA0_JEGW1ADN (sdf) - Disk 3 in error state (disk dsbl) Description: WDC_WD100EMAZ-00WJTA0_JEGW40YN (sde) Description: Array has 3 disks with read errors Disk 3 - WDC_WD100EMAZ-00WJTA0_JEGW40YN (sde) (errors 64) Disk 4 - ST10000DM0004-2GR11L_ZJV6AXZB (sdd) (errors 156) Disk 5 - WDC_WD100EMAZ-00WJTA0_JEGW1ADN (sdf) (errors 1024) 10/13/2023 ~11AM Diag attached: Data-Rebuild finished (3299065 errors) (obviously incorrect) Description: Duration: 3 days, 3 hours, 20 minutes, 25 seconds. Average speed: 51.6 MB/s Rebooted to change around cables. After reboot: Disk 1 - WDC_WD140EDGZ-11B2DA2_2CHDSP1P (sdj) (errors * **disk3 (WDC_WD100EMAZ-00WJTA0_JEGW40YN) is disabled** * **disk5 (WDC_WD100EMAZ-00WJTA0_JEGW1ADN) is disabled** 10/13/2023 12PM: I tried doing a recheck but the noises coming from disk1 and errors popping up make me think not best way forward. Disk 1 - WDC_WD140EDGZ-11B2DA2_2CHDSP1P (sdj) (errors 990668) Disk 4 - ST10000DM0004-2GR11L_ZJV6AXZB (sdf) (errors 607524) Currently: Disk 1: Officially available, but (1) Corrupted file system (2) making noises and log has errors Oct 13 11:48:29 kernel: I/O error, dev sdj, sector 84870416 op 0x0:(READ) flags 0x0 phys_seg 128 prio class 2 Oct 13 11:48:29 kernel: device offline error, dev sdj, sector 84871440 op 0x0:(READ) flags 0x0 phys_seg 32 prio class 2 Oct 13 11:48:30 kernel: sd 11:0:4:0: [sdj] Synchronizing SCSI cache Oct 13 11:48:30 kernel: sd 11:0:4:0: [sdj] Synchronize Cache(10) failed: Result: hostbyte=0x01 driverbyte=DRIVER_OK Disk 3: Emulated & Disabled Disk 4: Had some Reallocated Sector accounts last week, but stopped at 136. Planned on replacing soon. Disk 5: Emulated & Disabled Me: Confused bridge-diagnostics-20231008-2035.zip bridge-diagnostics-20231013-1216.zip bridge-diagnostics-20231013-1034.zip
-
4. Shut down the docker container before restarting your VM
-
Thanks - Just wanted to confirm, it does show the errors were corrected? I plan on Adding dual parity now so want to make sure.
-
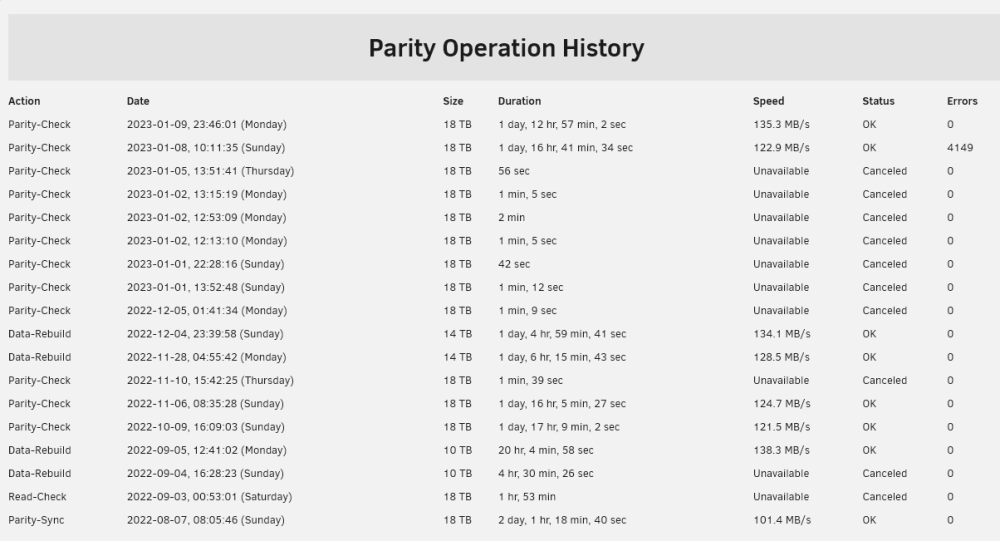
My monthly parity check without corrections said 4149 errors - this made sense to me as I had a few system hangups* the previous weeks. Started a new parity check manually with corrections on, but the history log shows 0 errors. But the email said there was 4149 errors, and the previous parity check email said I cancelled it, so I don't know whats going on now... *The hangups are a separate issue (I dont know if answers will be in the logs since I had to force reboot). They happened as I was attempting to preclear a new drive as I would like to switch to dual parity. I'm using a random Amazon pcie SATA card, so I'm assuming that the issue is simply from that and I plan on swapping that out for an LSI card. Parity Operation History: EMAILS 1-9-2023 11:47 PM: Event: Unraid Parity-Check Subject: Notice [MY_SYSTEM] - Parity-Check finished (4149 errors) Description: Duration: 1 day, 16 hours, 41 minutes, 34 seconds. Average speed: 122.9 MB/s Importance: normal 1-8-2023 10:50 AM Event: Unraid Parity-Check Subject: Notice [MY_SYSTEM] - Parity-Check started Description: Size: 18.0 TB Importance: warning 1-8-2023 10:12 AM Event: Unraid Parity-Check Subject: Notice [MY_SYSTEM] - Parity-Check finished (0 errors) Description: Canceled Importance: warning 1-6-2023 5:30 PM Event: Unraid Parity-Check Subject: Notice [MY_SYSTEM] - Parity-Check started Description: Size: 18.0 TB Importance: warning Archived notifications: 09-01-2023 11:47 PM Unraid Parity-CheckNotice [MY_SYSTEM] - Parity-Check finished (4149 errors)Duration: 1 day, 16 hours, 41 minutes, 34 seconds. Average speed: 122.9 MB/s normal 09-01-2023 12:20 AM Unraid StatusNotice [MY_SYSTEM] - array health report [PASS]Array has 8 disks (including parity & cache) normal 08-01-2023 10:50 AM Unraid Parity-CheckNotice [MY_SYSTEM] - Parity-Check started Size: 18.0 TB warning 08-01-2023 10:12 AM Unraid Parity-CheckNotice [MY_SYSTEM] - Parity-Check finished (0 errors) Canceled warning 07-01-2023 05:00 PM Community ApplicationsApplication Auto Updatetips.and.tweaks.plg Automatically Updated normal 07-01-2023 05:00 PM Community ApplicationsApplication Auto Updatecommunity.applications.plg Automatically Updated normal 06-01-2023 07:30 PM Community ApplicationsDocker Auto UpdateAirConnect bazarr firefox flaresolverr netdata plex-meta-manager prowlarr qdirstat radarr Automatically Updatednormal 06-01-2023 05:31 PM Unraid Parity-CheckNotice [MY_SYSTEM] - Parity-Check started Size: 18.0 TB warning 05-01-2023 01:52 PM Unraid Parity-CheckNotice [MY_SYSTEM] - Parity-Check finished (0 errors) Canceled warning 05-01-2023 01:51 PM Unraid Parity-CheckNotice [MY_SYSTEM] - Parity-Check started Size: 18.0 TB warning bridge-diagnostics-20230109-2353.zip
-
So what worked for me @PCR is adding HardwareDevicePath="/dev/dri/renderD129" to the preferences.xml https://forums.plex.tv/t/preferred-hw-transcoder-linux/593507
-
@nuhll this is thread on Plex forums maybe you can make more sense of it. By working again you mean on 1.29.0, right?
-
LinusServer is suggesting this is not their problem, plex is so far suggesting it should be using i965 not iHD so everyone is just pointing fingers...
-
I've downgraded to 1.29.0.6244-819d3678c and its working again. (In linuxserver container, you can set this in VERSION)
-
I've had quicksync working fine for several months, its suddenly not working. Have tried rebooting container (linuxserver) and system. I'm now on 6.11.1, recently upgraded from 6.10.3 (not sure if has worked at all under 6.11.1, (Tautulli history suggests Transcoding was working until yesterday). Any attempt to transcode resorts in the client reporting that the transcoder crashed (or in iOS app case, completely crashing) I can consistently test this, Direct Play works, I force a lower resolution and it crashes. dev output: root@$:/# ls -la /dev/dri total 0 drwxrwxrwx 3 root root 140 Oct 24 18:00 ./ drwxr-xr-x 16 root root 3660 Oct 24 18:02 ../ drwxrwxrwx 2 root root 120 Oct 24 18:00 by-path/ crwxrwxrwx 1 root video 226, 0 Oct 24 18:00 card0 crwxrwxrwx 1 root video 226, 1 Oct 24 18:00 card1 crwxrwxrwx 1 root video 226, 128 Oct 24 18:00 renderD128 crwxrwxrwx 1 root video 226, 129 Oct 24 18:00 renderD129 container settings: repo - lscr.io/linuxserver/plex version - public (tried setting to 18.07.22) quicksync - /dev/dri (tried settings to /dev/dri:/dev/dri) com.plex.system.log 2022-10-24 20:47:13,746 (147fc6811b38) : ERROR (networking:196) - Error opening URL 'http://resources-cdn.plexapp.com/hashes.json' 2022-10-24 20:47:13,747 (147fc6811b38) : CRITICAL (runtime:1299) - Exception getting hosted resource hashes (most recent call last): File "/usr/lib/plexmediaserver/Resources/Plug-ins-f4cdfea9c/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/components/runtime.py", line 1291, in get_resource_hashes json = self._core.networking.http_request("http://resources-cdn.plexapp.com/hashes.json", timeout=5).content File "/usr/lib/plexmediaserver/Resources/Plug-ins-f4cdfea9c/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/components/networking.py", line 242, in content return self.__str__() File "/usr/lib/plexmediaserver/Resources/Plug-ins-f4cdfea9c/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/components/networking.py", line 220, in __str__ self.load() File "/usr/lib/plexmediaserver/Resources/Plug-ins-f4cdfea9c/Framework.bundle/Contents/Resources/Versions/2/Python/Framework/components/networking.py", line 158, in load f = self._opener.open(req, timeout=self._timeout) File "/usr/lib/plexmediaserver/Resources/Python/python27.zip/urllib2.py", line 435, in open response = meth(req, response) File "/usr/lib/plexmediaserver/Resources/Python/python27.zip/urllib2.py", line 548, in http_response 'http', request, response, code, msg, hdrs) File "/usr/lib/plexmediaserver/Resources/Python/python27.zip/urllib2.py", line 473, in error return self._call_chain(*args) File "/usr/lib/plexmediaserver/Resources/Python/python27.zip/urllib2.py", line 407, in _call_chain result = func(*args) File "/usr/lib/plexmediaserver/Resources/Python/python27.zip/urllib2.py", line 556, in http_error_default raise HTTPError(req.get_full_url(), code, msg, hdrs, fp) HTTPError: HTTP Error 403: Forbidden Plex Media Server.log Full log below but Im guessing highlight is Oct 24, 2022 20:48:57.543 [0x147757d68b38] ERROR - [Req#3f8/Transcode/4gfp1x9ahodb86bcb4ogtbv4/55c3b60e-f6c3-4d74-a336-3e39505395b5] [AVHWDeviceContext @ 0x145afb275780] Failed to initialise VAAPI connection: -1 (unknown libva error). Oct 24, 2022 20:48:57.543 [0x147751edeb38] ERROR - [Req#3f9/Transcode/4gfp1x9ahodb86bcb4ogtbv4/55c3b60e-f6c3-4d74-a336-3e39505395b5] Device creation failed: -5. Oct 24, 2022 20:48:57.543 [0x147756252b38] ERROR - [Req#3fa/Transcode/4gfp1x9ahodb86bcb4ogtbv4/55c3b60e-f6c3-4d74-a336-3e39505395b5] Failed to set value 'vaapi=vaapi:/dev/dri/renderD129' for option 'init_hw_device': I/O error Oct 24, 2022 20:48:57.543 [0x1477576d7b38] ERROR - [Req#3fb/Transcode/4gfp1x9ahodb86bcb4ogtbv4/55c3b60e-f6c3-4d74-a336-3e39505395b5] Error parsing global options: I/O error Intel® Core™ i7-3770K CPU @ 3.50GHz 32GB RAM GTX 1650 Hardware Profile and full log attached to clean up post... hardwareProfile And plexLog.txt

