




Coogan2007
Members
-
Joined
-
Last visited
Everything posted by Coogan2007
-
Kinda figured. Loosing the pool isn't a big deal; I already have a backup copy of my library stored elsewhere, so the only thing I'd be losing is the 36-48 hours it'll take to copy the library back over. Thanks JorgeB 👍
-
Yes, deleting the partition was part of the screw-up I made. I thought reformatting might fix it. <morganfreeman>It didn't </morganfreeman>
-
root@unRAID:~# btrfs fi show Label: none uuid: 6effd5dd-ac37-4c79-8b7e-1b092477d839 Total devices 4 FS bytes used 4.56GiB devid 1 size 465.76GiB used 64.00GiB path /dev/nvme0n1p1 devid 2 size 1.86TiB used 177.00GiB path /dev/sdj1 devid 3 size 465.76GiB used 54.01GiB path /dev/sde1 devid 4 size 465.76GiB used 63.01GiB path /dev/sdf1 Label: none uuid: 3bb64198-8832-41c3-aa32-210bca89b80b Total devices 1 FS bytes used 8.81GiB devid 1 size 200.00GiB used 17.02GiB path /dev/loop2 Label: none uuid: 36899d09-a8d8-43c1-be01-7f91d98ebd4b Total devices 1 FS bytes used 144.00KiB devid 1 size 1.82TiB used 2.07GiB path /dev/sdk1 Label: 'PlexBackup3' uuid: c545cf29-eba2-4f8b-a185-63522a08304d Total devices 3 FS bytes used 8.31TiB devid 1 size 4.55TiB used 4.20TiB path /dev/sdd1 devid 2 size 4.55TiB used 4.20TiB path /dev/sdb1 *** Some devices missing The /dev/sdk1 is the device that is missing. Thanks for taking a look at this, JorgeB
-
I have two 5TB USB drives attached to my unRAID server, formatted in BTRFS and lashed together as a single 10TB drive, used as a tertiary backup to my media library. Space was starting to get a little tight so I connected an unused 2TB drive, formatted it, and added it to the pool. Well, I screwed something up and ended up removing the partition from the 2TB drive. Now the entire pool won't mount. I realized my mistake and know what to do now, but I can't get back to the starting point (unless, I guess, I scrap the entire pool and start over from scratch again). I'm pretty sure the problem is that there's now a big 2TB unformatted chunk of space in the pool. Below is the error in the log. The mount point for the pool is /mnt/disks/PlexBackup3. It currently doesn't exist and any time I manually create it, it gets deleted when I attempt to mount the pool. The id of the missing disk is devid 3. May 7 21:36:20 unRAID unassigned.devices: Mounting partition 'sdd1' at mountpoint '/mnt/disks/PlexBackup3'... May 7 21:36:20 unRAID unassigned.devices: Mount cmd: /sbin/mount -t 'btrfs' -o rw,relatime,space_cache=v2 '/dev/sdd1' '/mnt/disks/PlexBackup3' May 7 21:36:20 unRAID kernel: BTRFS info (device sdd1): first mount of filesystem c545cf29-eba2-4f8b-a185-63522a08304d May 7 21:36:20 unRAID kernel: BTRFS info (device sdd1): using crc32c (crc32c-intel) checksum algorithm May 7 21:36:20 unRAID kernel: BTRFS info (device sdd1): using free space tree May 7 21:36:20 unRAID kernel: BTRFS error (device sdd1): devid 3 uuid 45e0b911-317c-4954-9de4-fd44d79c8e5f is missing May 7 21:36:20 unRAID kernel: BTRFS error (device sdd1): failed to read chunk tree: -2 May 7 21:36:20 unRAID kernel: BTRFS warning (device sdd1): folio private not zero on folio 1107125698560 May 7 21:36:20 unRAID kernel: BTRFS warning (device sdd1): folio private not zero on folio 1107125702656 May 7 21:36:20 unRAID kernel: BTRFS warning (device sdd1): folio private not zero on folio 1107125706752 May 7 21:36:20 unRAID kernel: BTRFS warning (device sdd1): folio private not zero on folio 1107125710848 May 7 21:36:20 unRAID kernel: BTRFS warning (device sdd1): folio private not zero on folio 1107139280896 May 7 21:36:20 unRAID kernel: BTRFS warning (device sdd1): folio private not zero on folio 1107139284992 May 7 21:36:20 unRAID kernel: BTRFS warning (device sdd1): folio private not zero on folio 1107139289088 May 7 21:36:20 unRAID kernel: BTRFS warning (device sdd1): folio private not zero on folio 1107139293184 May 7 21:36:20 unRAID kernel: BTRFS error (device sdd1): open_ctree failed May 7 21:36:21 unRAID unassigned.devices: Mount of 'sdd1' failed: 'mount: /mnt/disks/PlexBackup3: mount system call failed: No such file or directory. dmesg(1) may have more information after failed mount system call.' Any ideas on how to pry this missing disk out of the BTRFS config? I spend some time googling for help but almost everything I found assumed that the filesystem can be mounted.

-
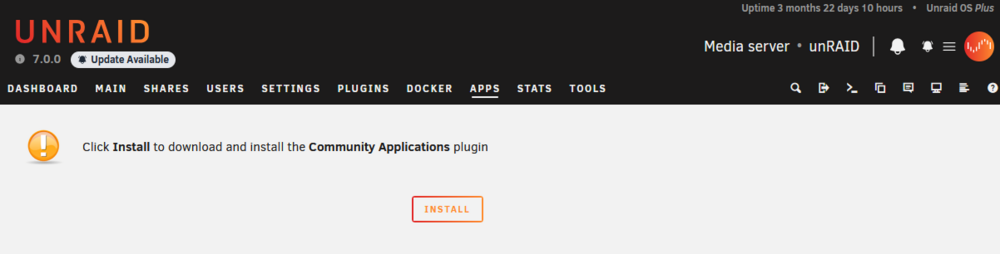
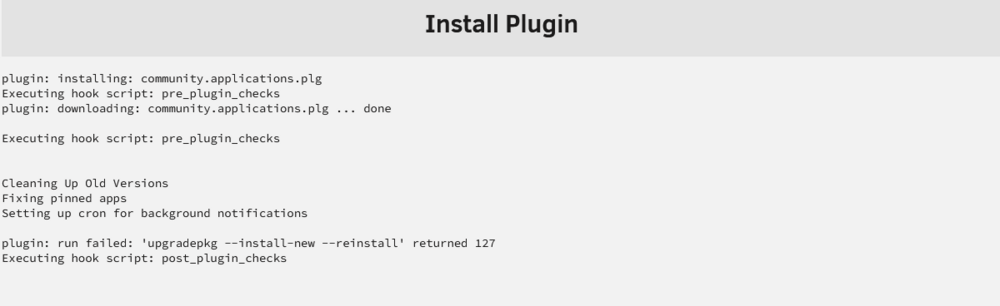
I've lost access to the Community Apps plugin. I got notified it needed to be updated, so I did, and it failed, and now I get this. When I try to install it, I get the 2nd. Diagnostics attached. unraid-diagnostics-20250703-2300.zip
-
Nope, everything is on the same network. Only thing in between this PC and the server is a switch.
-
I'm updating the system on the same computer that I'm posting this from; it's in another browser tab. This PC definitely has internet access.
-
No issues with internet access. root@unRAID:~# ping 8.8.8.8 PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data. 64 bytes from 8.8.8.8: icmp_seq=1 ttl=118 time=10.8 ms 64 bytes from 8.8.8.8: icmp_seq=2 ttl=118 time=11.3 ms 64 bytes from 8.8.8.8: icmp_seq=3 ttl=118 time=11.4 ms 64 bytes from 8.8.8.8: icmp_seq=4 ttl=118 time=13.2 ms 64 bytes from 8.8.8.8: icmp_seq=5 ttl=118 time=9.96 ms 64 bytes from 8.8.8.8: icmp_seq=6 ttl=118 time=11.1 ms 64 bytes from 8.8.8.8: icmp_seq=7 ttl=118 time=10.1 ms 64 bytes from 8.8.8.8: icmp_seq=8 ttl=118 time=8.59 ms
-
At 5 hours now and nothing new. I can open a new tab to the system and it still shows it running normally, and shows Update Available at the top. This is literally the only thing it's shown during that time. These are the only files in /var/log that have been written to since I started the update: -rw-rw-rw- 1 root root 34 Jul 3 18:40 gitcount -rw-rw-rw- 1 root root 22K Jul 3 18:40 gitflash -rw-r--r-- 1 root root 517K Jul 3 21:19 syslog -rw-rw-rw- 1 root root 314K Jul 3 21:26 graphql-api.log This is the only updates in syslog in that time: Jul 3 16:39:01 unRAID flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update Jul 3 17:19:07 unRAID crond[1746]: exit status 1 from user root php /usr/local/emhttp/plugins/community.applications/scripts/notices.php > /dev/null 2>&1 Jul 3 18:19:16 unRAID crond[1746]: exit status 1 from user root php /usr/local/emhttp/plugins/community.applications/scripts/notices.php > /dev/null 2>&1 Jul 3 18:39:01 unRAID flash_backup: adding task: /usr/local/emhttp/plugins/dynamix.my.servers/scripts/UpdateFlashBackup update Jul 3 19:19:16 unRAID crond[1746]: exit status 1 from user root php /usr/local/emhttp/plugins/community.applications/scripts/notices.php > /dev/null 2>&1 Jul 3 20:19:16 unRAID crond[1746]: exit status 1 from user root php /usr/local/emhttp/plugins/community.applications/scripts/notices.php > /dev/null 2>&1 Jul 3 21:19:16 unRAID crond[1746]: exit status 1 from user root php /usr/local/emhttp/plugins/community.applications/scripts/notices.php > /dev/null 2>&1 tail -20 gitflash [2025/07/03 18:40:00 America/Chicago] update local repo size is acceptable (75872 < 100000) [2025/07/03 18:40:02 America/Chicago] update ssh_output You have successfully authenticated over SSH but interactive shells are not supported here.Unraid Flash Backup should have no issues connecting. Goodbye. [2025/07/03 18:40:03 America/Chicago] update Command 'git -C /boot reset origin/master' exited with code 0 [2025/07/03 18:40:05 America/Chicago] update Command 'git -C /boot checkout -B master origin/master' exited with code 0 [2025/07/03 18:40:05 America/Chicago] update Command 'git -C /boot status --porcelain' exited with code 0 [2025/07/03 18:40:05 America/Chicago] update Command 'git -C /boot show --summary' exited with code 0 [2025/07/03 18:40:05 America/Chicago] update Command 'git -C /boot ls-files --cached --ignored --exclude-standard' exited with code 0 [2025/07/03 18:40:05 America/Chicago] update Command 'git -C /boot add -A' exited with code 0 [2025/07/03 18:40:06 America/Chicago] update Command 'git -C /boot commit -m 'Config change'' exited with code 0 [2025/07/03 18:40:11 America/Chicago] update Command 'git -C /boot push --force --set-upstream origin master' exited with code 0 tail -20 graphql-api.log [20:41:58.733] WARN: Activation directory /boot/config/activation not found when searching for JSON file. {"logger":"api","req":{"id":"req-iv","method":"POST","url":"/graphql"},"context":"CustomizationService"} [20:41:58.733] WARN: No activation JSON file found. {"logger":"api","req":{"id":"req-iv","method":"POST","url":"/graphql"},"context":"CustomizationService"} [21:11:58.940] WARN: Activation directory /boot/config/activation not found when searching for JSON file. {"logger":"api","req":{"id":"req-j0","method":"POST","url":"/graphql"},"context":"CustomizationService"} [21:11:58.940] WARN: No activation JSON file found. {"logger":"api","req":{"id":"req-j0","method":"POST","url":"/graphql"},"context":"CustomizationService"} [21:11:58.942] WARN: Activation directory /boot/config/activation not found when searching for JSON file. {"logger":"api","req":{"id":"req-iz","method":"POST","url":"/graphql"},"context":"CustomizationService"} [21:11:58.942] WARN: No activation JSON file found. {"logger":"api","req":{"id":"req-iz","method":"POST","url":"/graphql"},"context":"CustomizationService"} [21:11:58.942] WARN: Activation directory /boot/config/activation not found when searching for JSON file. {"logger":"api","req":{"id":"req-iz","method":"POST","url":"/graphql"},"context":"CustomizationService"} [21:11:58.942] WARN: No activation JSON file found. {"logger":"api","req":{"id":"req-iz","method":"POST","url":"/graphql"},"context":"CustomizationService"} [21:15:10.363] WARN: Activation directory /boot/config/activation not found when searching for JSON file. {"logger":"api","req":{"id":"req-j5","method":"POST","url":"/graphql"},"context":"CustomizationService"} [21:15:10.363] WARN: No activation JSON file found. {"logger":"api","req":{"id":"req-j5","method":"POST","url":"/graphql"},"context":"CustomizationService"} [21:15:10.364] WARN: Activation directory /boot/config/activation not found when searching for JSON file. {"logger":"api","req":{"id":"req-j4","method":"POST","url":"/graphql"},"context":"CustomizationService"} [21:15:10.364] WARN: No activation JSON file found. {"logger":"api","req":{"id":"req-j4","method":"POST","url":"/graphql"},"context":"CustomizationService"} [21:15:10.364] WARN: Activation directory /boot/config/activation not found when searching for JSON file. {"logger":"api","req":{"id":"req-j4","method":"POST","url":"/graphql"},"context":"CustomizationService"} [21:15:10.365] WARN: No activation JSON file found. {"logger":"api","req":{"id":"req-j4","method":"POST","url":"/graphql"},"context":"CustomizationService"} [21:26:03.050] WARN: Activation directory /boot/config/activation not found when searching for JSON file. {"logger":"api","req":{"id":"req-ja","method":"POST","url":"/graphql"},"context":"CustomizationService"} [21:26:03.050] WARN: No activation JSON file found. {"logger":"api","req":{"id":"req-ja","method":"POST","url":"/graphql"},"context":"CustomizationService"} [21:26:03.051] WARN: Activation directory /boot/config/activation not found when searching for JSON file. {"logger":"api","req":{"id":"req-j9","method":"POST","url":"/graphql"},"context":"CustomizationService"} [21:26:03.051] WARN: No activation JSON file found. {"logger":"api","req":{"id":"req-j9","method":"POST","url":"/graphql"},"context":"CustomizationService"} [21:26:03.051] WARN: Activation directory /boot/config/activation not found when searching for JSON file. {"logger":"api","req":{"id":"req-j9","method":"POST","url":"/graphql"},"context":"CustomizationService"} [21:26:03.052] WARN: No activation JSON file found. {"logger":"api","req":{"id":"req-j9","method":"POST","url":"/graphql"},"context":"CustomizationService"}
-
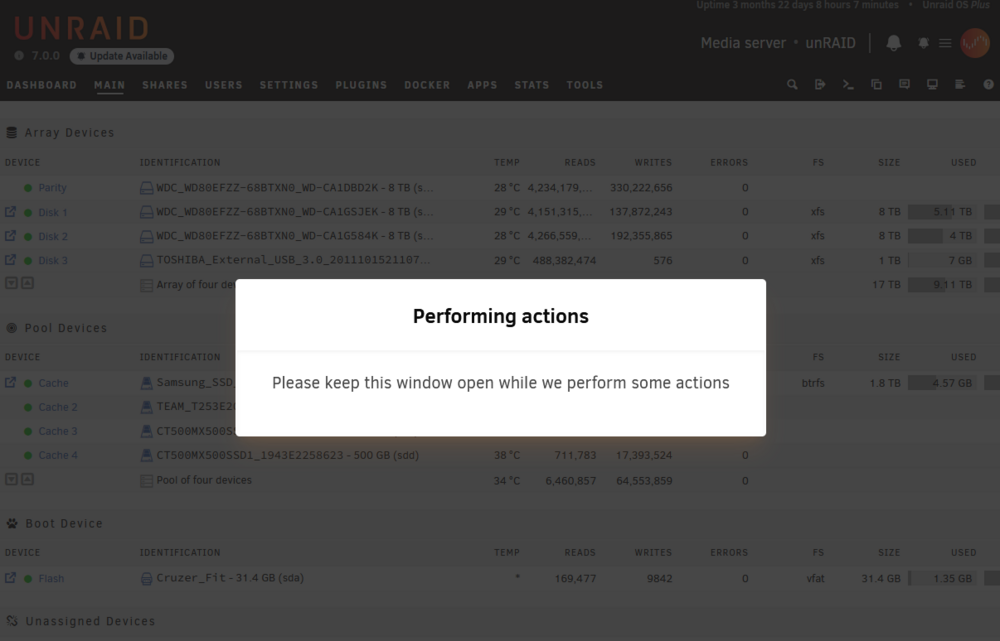
I started the update an hour and 45 minutes ago and this message "Performing Actions: Please Keep This Window Open While We Perform Some Actions" hasn't gone away. The box is right behind me and AFAICT nothing has been happening. I opened another browser tab to the system and it doesn't appear to be doing anything. Nothing is showing up in the syslog to indicate it's actually doing anything at all. How long can I expect this to stay up?
-
Anything new on this? It's been 6 weeks and I still cannot update the UD. And now it's affecting the community app plugin; same error. Now I cannot access Community Apps at all. Edit: Just noticed the actual error message aren't showing in the log for some reason. Any response to plugin-manager: running: upgradepkg --install-new --reinstall throws out an error with code 127. Jul 2 08:39:08 unRAID monitor_nchan: Stop running nchan processes Jul 3 15:58:36 unRAID plugin-manager: creating: /boot/config/plugins/unassigned.devices/unassigned.devices-2025.06.15-x86_64-1.txz - downloading from URL https://raw.githubusercontent.com/unraid/unassigned.devices/master/archive/unassigned.devices-2025.06.15-x86_64-1.txz Jul 3 15:58:36 unRAID plugin-manager: checking: /boot/config/plugins/unassigned.devices/unassigned.devices-2025.06.15-x86_64-1.txz - MD5 Jul 3 15:58:36 unRAID plugin-manager: running: upgradepkg --install-new --reinstall /boot/config/plugins/unassigned.devices/unassigned.devices-2025.06.15-x86_64-1.txz Jul 3 15:59:22 unRAID plugin-manager: running: 'anonymous' Jul 3 15:59:22 unRAID plugin-manager: running: 'anonymous' Jul 3 15:59:22 unRAID plugin-manager: creating: /boot/config/plugins/community.applications/community.applications-2025.06.04a-x86_64-1.txz - downloading from URL https://raw.githubusercontent.com/unraid/community.applications/master/archive/community.applications-2025.06.04a-x86_64-1.txz Jul 3 15:59:22 unRAID plugin-manager: checking: /boot/config/plugins/community.applications/community.applications-2025.06.04a-x86_64-1.txz - MD5 Jul 3 15:59:22 unRAID plugin-manager: running: upgradepkg --install-new --reinstall /boot/config/plugins/community.applications/community.applications-2025.06.04a-x86_64-1.txz Jul 3 15:59:49 unRAID plugin-manager: running: 'anonymous' Jul 3 15:59:49 unRAID plugin-manager: running: 'anonymous' Jul 3 15:59:49 unRAID plugin-manager: checking: /boot/config/plugins/community.applications/community.applications-2025.06.04a-x86_64-1.txz - MD5 Jul 3 15:59:49 unRAID plugin-manager: skipping: /boot/config/plugins/community.applications/community.applications-2025.06.04a-x86_64-1.txz already exists Jul 3 15:59:49 unRAID plugin-manager: running: upgradepkg --install-new --reinstall /boot/config/plugins/community.applications/community.applications-2025.06.04a-x86_64-1.txz
-
Diagnostics are attached. Thanks for helping with this. unraid-diagnostics-20250520-1106.zip
-
I'm having an issue where I cannot update either Unassigned Devices or UD Preclear containers. In the Action Center I click to update either and it just throws up a blank white window with "Close" at the bottom. Last week I tried to update and it wouldn't update, and when I checked the log it said something like Error 127, I think? Anyway, here's what the logs are tossing out tonight: May 19 21:19:30 unRAID plugin-manager: checking: /boot/config/plugins/unassigned.devices/unassigned.devices-2025.04.14-x86_64-1.txz - MD5 May 19 21:19:30 unRAID plugin-manager: skipping: /boot/config/plugins/unassigned.devices/unassigned.devices-2025.04.14-x86_64-1.txz already exists May 19 21:19:30 unRAID plugin-manager: running: upgradepkg --install-new --reinstall /boot/config/plugins/unassigned.devices/unassigned.devices-2025.04.14-x86_64-1.txz May 19 21:22:02 unRAID plugin-manager: running: 'anonymous' May 19 21:22:02 unRAID plugin-manager: checking: /boot/config/plugins/unassigned.devices.preclear/unassigned.devices.preclear-2025.02.25.tgz - MD5 May 19 21:22:02 unRAID plugin-manager: skipping: /boot/config/plugins/unassigned.devices.preclear/unassigned.devices.preclear-2025.02.25.tgz already exists May 19 21:22:02 unRAID plugin-manager: checking: /boot/config/plugins/unassigned.devices.preclear/tmux-3.1b-x86_64-1.txz - MD5 May 19 21:22:02 unRAID plugin-manager: skipping: /boot/config/plugins/unassigned.devices.preclear/tmux-3.1b-x86_64-1.txz already exists May 19 21:22:02 unRAID plugin-manager: running: upgradepkg --install-new /boot/config/plugins/unassigned.devices.preclear/tmux-3.1b-x86_64-1.txz It's been 10 minutes and hasn't done anything. Anything I can do or provide?
-
Anybody have any insight on this? It's still happening and it's getting annoying. I'm gonna open a bug report if there's no answer for this.
-
Not sure if this is place for this so let me know if it needs to be asked somewhere else. This started happening with 7.0. I have containers behind the NordLynx container using it's network interface. Everything has been working fine, but after a few days I can no longer connect to the containers' UI. If I restart the container(s) everything works fine again but I have errors in them because they lost their network connection. Like I said, it works great at the beginning. All the ports are correctly mapped, but after a few days (not exactly sure how long; I only check it every 4-5 days) the containers connection to the VPN container "decays" (best way I can think to describe it) and they all become unreachable. Any ideas?
-
Final update (hopefully). Everything seems to be OK. I reformatted the cache pool, as well as re-arranging the order of the drives (don't know if that actually helps) and after a brief panic when all my exportable user shares were gone (fixed by a quick reboot), everything is running fine. One of the SSDs threw out a "percent lifetime remaining" SMART error but I'll fix that at some point. My docker appdata was indeed wiped out at some point. Fortunately, the docker container whose app data was going to be the most time-consuming to rebuild kept regular backups of it's database and a quick restore later it's all good. Still got VPN and all my *arrs to fix but there's no rush for that. Thanks for all the help, JorgeB. You're a life-saver.
-
Got it. A few more questions about this if you don't mind. I invoked the mover and it didn't seem to do anything. The shares still say either "Share contains data" or "Share is empty". Do all of them need to say they're empty to know that all the data was moved to the array? Regarding the appdata folder. It's my understanding that this is where Docker containers keep all their application data. My appdata folder is empty. I assume that means all data my containers held is now gone? If so is there a way to recover it? Trying to save myself weeks of re-googling, retrying, and rebuilding all my containers from the ground up.
-
OK I'm back from holiday and hope to start fixing this. I started following the instructions for reformatting the cache pool in the Storage Management page and immediately hit a problem: There's nothing in any of the share settings that say "Use Cache" anywhere. There's a "Primary Storage" setting. Is that it? Am I looking at the wrong thing?
-
The cache pool? How do I back it up? Edit: nvm, I found it in the Storage Mgnt section. I'm leaving for a week for the holidays and probably won't bother undertaking all this until after I get back. There's nothing system/life-critical on it so I'll shut it down and start everything after the holidays. I'll report back in this thread with results. Thanks again for all your help.
-
Yep, I didn't even notice that until you mentioned it. I thought everything was doing better. Am I going to need to re-format the cache drive?
-
Just another note. The /system dir that was in read-only appears to be correct now. I opened a console and touch'ed an empty file in /mnt/disk1/system/docker and it was created, so it appears the repair may have fixed it, I guess? Docker is running and while my containers aren't there, it seems like progress. Still, I'm gonna wait until I get some feedback before proceeding any further. Thanks for the help with this.
-
Ahh, thank you. I ran a repair on it in maintenance mode overnight but didn't seem to do anything. A filesystem check came back with the same stuff as before. Edit: just occurred to me the diags attached were in maintenance mode. I've restarted the array and replaced the diags, just in case. unraid-diagnostics-20241220-0848.zip
-
Welp, the docker.img file is set to read-only and I can't delete it. I tried from the GUI and console and it said the entire filesystem is in read-only mode, and I haven't a clue how to fix it outside of re-formatting the cache drive. Any other suggestions?
-
Holy......that fixed it. The cache pool is back up and running. Can you tell me what the problem is and how that command fixed it? Diags are post per your request. Edit: may have spoke a little too soon. Docker is running and all the containers that were set to auto-start came back up, but trying to start some manually threw back an execution error. I tried restarting some of the ones that were running and they threw out the same and won't start back up. unraid-diagnostics-20241219-0955.zip
-
Diagnostics are attached. unraid-diagnostics-20241218-1235.zip




