





brankko
Members
-
Joined
-
Last visited
Everything posted by brankko
-
What happened here is not enough power from PSU. Let me explain. I started having Disk (read) errors on one of the larger drives. I replaced the drive, got the same thing after some time. I changed the cables... the same... it works for days and then it detects some errors and disables the disk. As I was adding the drives, I kept adding those SATA extender adapters and at some point it was too much for poor PSU. I tried a different PSU and it all worked as a clock. Since I already started building second backup server, I reduced the number of drives in this machine and replaced smaller drives with larger. Now it works with the old PSU as well. It's weird because it's not obvious, but it makes sense. So people, be careful with your power load on a single branch of PSU.
-
MemTest passed with multiple runs. Will check the disks one by one next and replace if failing extended SMART checks outside the Unraid box. I am still confused by segfaults and buggy VM as those are running separately of HDDs (VMs are on NVMe cache disk).
-
I am facing a few seemingly unrelated issues (Unraid 7.0.1) that may be related to hardware problem, but unsure how to test/confirm. List of issues: Segfault in error log Mar 25 17:16:18 Shelf kernel: inotifywait[14789]: segfault at 0 ip 000000000040288b sp 00007ffe20b84f90 error 4 in inotifywait[402000+2000] likely on CPU 5 (core 5, socket 0) Mar 25 17:16:18 Shelf kernel: Code: 00 00 48 89 da 89 ee 48 8d 7c 24 70 e8 fe 0e 00 00 48 8b 54 24 28 48 89 de 89 ef 48 8d 4c 24 70 e8 7a 0f 00 00 48 8b 44 24 70 <48> 83 38 00 0f 84 6f 05 00 00 80 7c 24 4d 00 0f 85 fd 02 00 00 48 Windows VM randomly throwing runtime errors (may be just Windows thing, but it worked fine for months) - screenshot attached. A few drives started reporting SMART errors: Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Extended offline Completed: read failure 90% 814 3971524688 Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Short offline Completed: read failure 10% 65372 1563571408 At the same time, extended SMART tests keep hanging for hours (may be because of segfault error mentioned before). I tried changing cables as that was. easiest to debug but nothing changed. Could be that my LSI card is dying or my CPU is dyng or something, or it's just bad drives (still under warranty) so I kept the system down so I don't lose any data, since NAS part seems to be working right now, but I'm afraid to run the mover until I get the drives resolved to show no SMART errors at least. I will run the MemTest first thing when I get back home, since I don't have JetKVM connected to this machine. but other than that, any idea on how to eliminate candidates and isolate what's wrong is welcome. I will be able to check drives independently via any bootable Linux or even in a different machine one by one, just to be sure. Diagnostics file attached. My configuration is: AMD Ryzen 5600G Gigabyte AB350N-Gaming 24GB DDR4 RAM 4x 8TB, 3x 4TB, 1x 3TB (WD Red Plus) LSI SAS2008 8i HBA card shelf-diagnostics-20250325-1740.zip
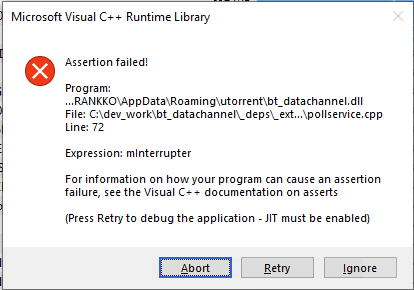
-
Thank you for the second fix specially. It was so annoying.
-
I upgraded one server last night. No issues so far. I use WDC WD80EFZZ and WD40EFZX drives and all of them are spinning down and up as before. Seems that other people with this issue had WD drives, but in my case both timeout and manual spin down works normally. P.S. Drives are connected via LSI M1015 9220-8I card
-
Same issue here. Either empty dashboard (blank page, or only header and top menu) or other pages taking like 2 minutes to load and become unresponsive. Tried deleting `/tmp/disklocation/db.lock` but it didn't help. Removing the plugin resolved it. Reinstalling brought the same issue again. Will have to wait for the update. P.S. I installed it on again on test server with nothing in it and got the same behaviour. Diagnostics attached. discovery-diagnostics-20240306-1036.zip
-
Thanks. I removed the ISOs from the templates for now, as it's not needed anymore. Seems to work fine.
-
Not sure if this is somehow me problem, but when I login to Dashboard I can hear disk(s) being spun up. I can also see them with green/active in the Array widget. A little bit of background After checking the File Activity (plugin) I noticed that ISOs for my (1 active, 2 not running) VMs are being read. and Which is exactly aligned with disks that are woke up and VMs I have on my Dashboard What should I do differently? Should I store my ISOs share on SSD? (does not make much sense since they are only read once for the VM installation) Should I hide "Virtual Machines" widget from Dashboard? (Interestingly, I spun down all the discs and refreshed Dashboard, but this time all of them stayed on 'standby' and not active) Or should I do something else? The main question is why is this happening at the first place? This is not an isolated case, since I noticed that it wakes up a disk or two when I open the Dashboard after a few hours of inactivity (default spin down time is 1h for me)
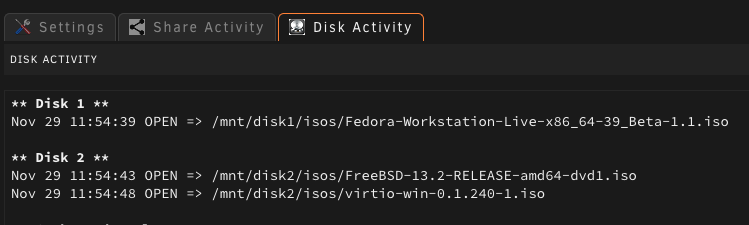

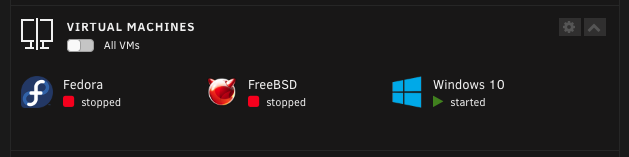
-
This was the first time in 20 years that I had problems with RAM memory. I was running mixed sizes, speeds, brands... new with used sticks... (it was in a various desktop machines). Many of my memory sticks came with *Lifetime warranty so I never had any suspicious for it. Turns out, memtest should not be skipped. For some future builds I may even consider ECC. This caused some erroneous files in docker file, so I had to rebuild a few images and to double check everything. Luckily everything is fine now.
-
I had no time to investigate, as I had to open the case, connect the display and everything so I kept it turned off most of the time not to corrupt any data, but today I finally did everything by the book and run the memtest. One of the recently installed memory sticks is faulty so I removed it. Since 16GB is plenty for my current usage, I'll just keep it as is until the next upgrade (already got 10GbE and HBA cards and waiting for some SSDs so I can try ZFS pool too).
-
Weird thing. I tried rebooting yesterday. Had the same issue. Now it worked. Thanks! Will definitely check the memory sticks, as I moved them recently from the other box.
-
I am currently running Version: 6.12.2 and I am not able to update to 6.12.3. I stopped Docker containers and disabled Docker service. Stopped all VMs. Stopped the Array. There is nothing running. 30+ GB of available RAM memory and plenty of available disk space: root@Shelf:~# df -H Filesystem Size Used Avail Use% Mounted on rootfs 17G 687M 16G 5% / tmpfs 34M 291k 34M 1% /run /dev/sda1 65G 1.1G 64G 2% /boot overlay 17G 687M 16G 5% /lib overlay 17G 687M 16G 5% /usr devtmpfs 8.4M 0 8.4M 0% /dev tmpfs 17G 0 17G 0% /dev/shm tmpfs 135M 406k 134M 1% /var/log When I run the Tools > Update OS, I am getting this: plugin: updating: unRAIDServer.plg plugin: downloading: unRAIDServer-6.12.3-x86_64.zip ... done plugin: downloading: unRAIDServer-6.12.3-x86_64.md5 ... done wrong md5 plugin: run failed: '/bin/bash' returned 1 Executing hook script: post_plugin_checks Any ideas what should I try? EDIT: Should I go with manual update? shelf-diagnostics-20230716-1853.zip
-
Update: It works! # lspci | egrep -i --color 'network|ethernet' 01:00.0 Ethernet controller: Broadcom Inc. and subsidiaries NetXtreme II BCM57810 10 Gigabit Ethernet (rev 10) 01:00.1 Ethernet controller: Broadcom Inc. and subsidiaries NetXtreme II BCM57810 10 Gigabit Ethernet (rev 10) Aufgrund meines Netzwerk-Switches ist es mit 1 Gbps verbunden lshw -class network *-network:0 description: Ethernet interface product: NetXtreme II BCM57810 10 Gigabit Ethernet vendor: Broadcom Inc. and subsidiaries physical id: 0 bus info: pci@0000:01:00.0 logical name: eth0 version: 10 serial: 6c:c2:17:35:c3:08 size: 1Gbit/s capacity: 10Gbit/s width: 64 bits clock: 33MHz capabilities: pm vpd msix pciexpress bus_master cap_list rom ethernet physical tp 100bt 100bt-fd 1000bt-fd 10000bt-fd autonegotiation configuration: autonegotiation=on broadcast=yes driver=bnx2x driverversion=5.19.17-Unraid duplex=full firmware=mbi 7.15.37 bc 7.14.37 phy 1.34 latency=0 link=yes multicast=yes port=twisted pair promiscuous=yes speed=1Gbit/s resources: iomemory:20-1f iomemory:20-1f iomemory:20-1f irq:74 memory:240000000-2407fffff memory:240800000-240ffffff memory:242000000-24200ffff memory:fcf80000-fcffffff memory:242020000-24209ffff memory:242120000-24213ffff
-
Ich habe vor kurzem eine HP 533FLR-T 2-Port 10GbE Netzwerkkarte günstig gekauft (billiger als 20 Euro). Habe auch den PCI-E-Adapter (erhältlich als DIY-Teile oder zusammengebaut über eBay und AliExpress). Im zusammengebauten Zustand sieht es aus wie eine normale PCI-Karte mit Standard-Backplate-Halterung... Aber ich habe immer noch Angst, es in meinen Heimserver zu legen: D Muss aus alten Komponenten einen billigen Prüfstand zusammenbauen, nur um es zu versuchen. Hoffe es funktioniert mit Unraid.







-
@Frank1940 Thanks! This is helpful. I am currently evaluating trial version so I made a lot of exploration changes in my system to figure out how it works and how it would fulfil my needs. That was the reason I restarted my home server frequently. Definitely would do a clean install when I decide to go with full version.
-
I made a manual restart, with stopped array and docker apps. What else could start an automatic parity check?
-
Yes, the first thing I tried is to redo the settings. root@Tower:~# crontab -l # If you don't want the output of a cron job mailed to you, you have to direct # any output to /dev/null. We'll do this here since these jobs should run # properly on a newly installed system. If a script fails, run-parts will # mail a notice to root. # # Run the hourly, daily, weekly, and monthly cron jobs. # Jobs that need different timing may be entered into the crontab as before, # but most really don't need greater granularity than this. If the exact # times of the hourly, daily, weekly, and monthly cron jobs do not suit your # needs, feel free to adjust them. # # Run hourly cron jobs at 47 minutes after the hour: 47 * * * * /usr/bin/run-parts /etc/cron.hourly 1> /dev/null # # Run daily cron jobs at 4:40 every day: 40 4 * * * /usr/bin/run-parts /etc/cron.daily 1> /dev/null # # Run weekly cron jobs at 4:30 on the first day of the week: 30 4 * * 0 /usr/bin/run-parts /etc/cron.weekly 1> /dev/null # # Run monthly cron jobs at 4:20 on the first day of the month: 20 4 1 * * /usr/bin/run-parts /etc/cron.monthly 1> /dev/null and root@Tower:~# cat /etc/cron.d/root # Generated system monitoring schedule: */1 * * * * /usr/local/emhttp/plugins/dynamix/scripts/monitor &> /dev/null # Generated mover schedule: 40 3 * * * /usr/local/sbin/mover &> /dev/null # Generated parity check schedule: 0 3 * * 0 [[ $(date +%e) -le 7 ]] && /usr/local/sbin/mdcmd check &> /dev/null || : # CRON for CA background scanning of applications 44 * * * * php /usr/local/emhttp/plugins/community.applications/scripts/notices.php > /dev/null 2>&1 And here is what I set up in the web ui (screenshot attached)
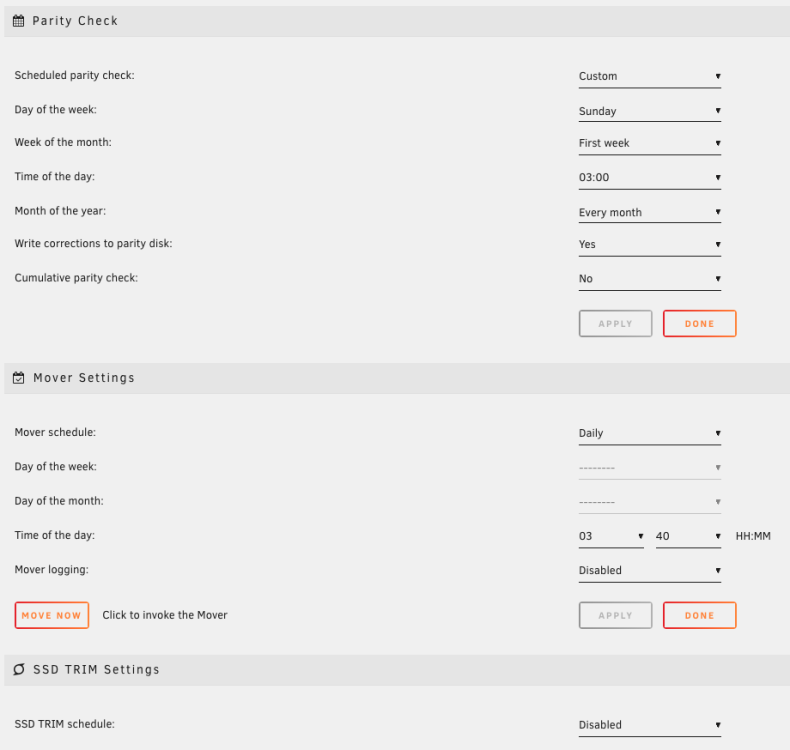
-
Here it is. Attached tower-diagnostics-20221017-1403.zip
-
I'm using version: 6.11.1 and the same issue happening to me too. At the moment Scheduled parity check is completely disabled, but it runs every day anyways. I have tried to set it to weekly and that setting is completely ignored. It runs every day. After reading this thread, I set it to custom date(s) so I can check if that is gonna be applied, but it seems that it's not fully resolved. Or am I missing something?
















