




stottle
Members
-
Joined
-
Last visited
-
The changes to add the add to Community Applications went live this morning. I just pushed a bunch of changes to the image. It now starts with two example notebooks * chat_example.ipynb provides a running chat example * diffusion_example.ipynb provides (wait for it....) a running stable-diffusion example It currently requires an NVIDIA GPU
-
Overview: Support for the JupyterLabNN (Neural Network) docker image from the bstottle repo Application: JupyterLab - https://jupyter.org DockerHub: https://hub.docker.com/r/bstottle42/python_base/ GitHub: https://github.com/bstottle/python_base There are two goals for this container 1) Provide an interactive (via Jupyter notebooks) python environment set up for evaluating AI/ML applications including Large Language Models (LLMs). 2) Provide a common _base_ image for LLM user interfaces like InvokeAI or text-generation-webui that leverage python for the actual processing.
-
I didn't see an answer posted, but per a post in another netdata support thread, the nvidia-smi support was moved from python.d.conf to go.d.conf (and set to "no" instead of "yes"). I was able to get Nvidia visualizations by changing (in go.conf.d) # nvidia_smi: no to nvidia_smi: yes I needed to add the parameter/value NVIDIA_VISIBLE_DEVICES / 'all' to the docker template and append `--runtime=nvidia` to Extra Parameters as well. I used the following to create/edit the config file (from the post linked above):
-
Ok. That does make the folders accessible. But seems only slightly better than mounting from /mnt/cache/<share>.
-
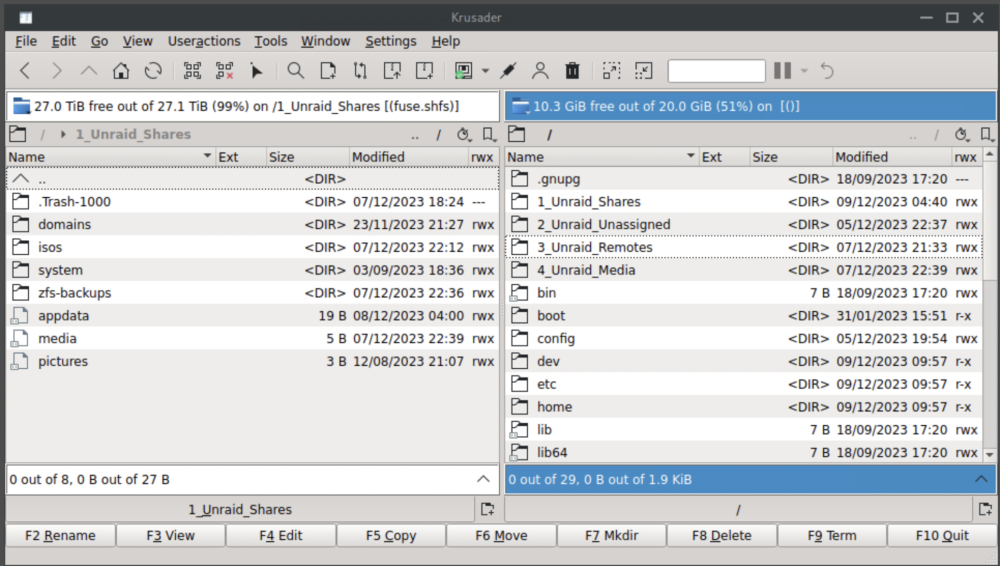
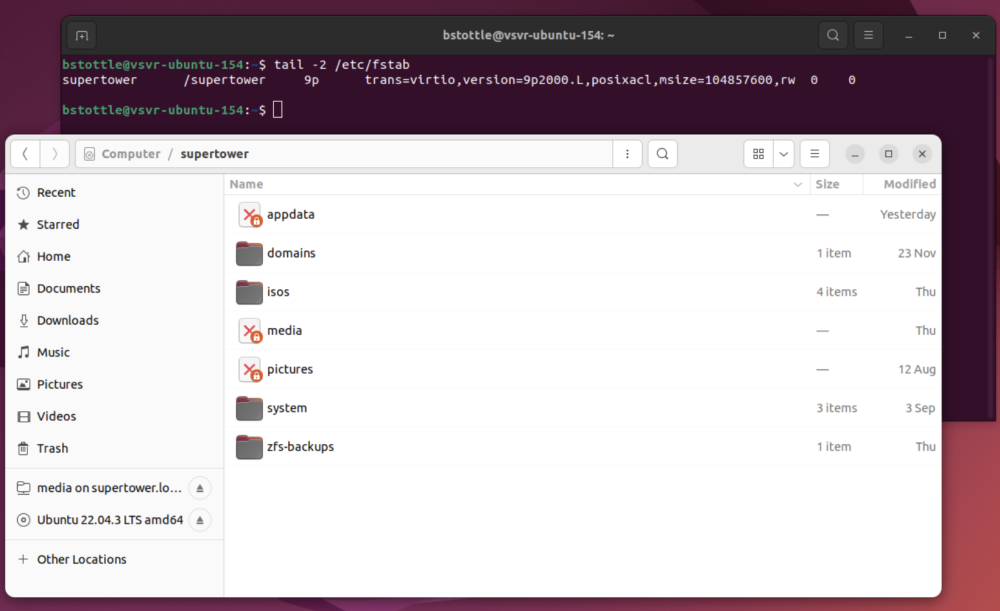
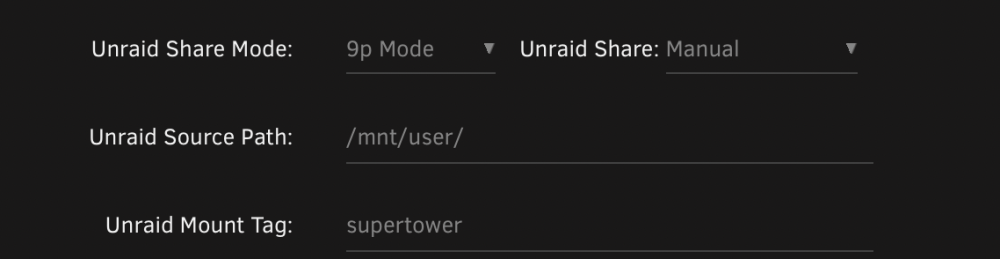
Sorry if my original post wasn't clear. I have 7 shares, and with exclusive shares setting enabled, 3 of them became exclusive shares. Exclusive: appdata, media, pictures Non-exclusive: domains, isos, system, zfs-backup. In the top image (binhex-krusader), the left side of the window shows a folder view of /mnt/user exposed to the docker (all of the shares). The three exclusive shares are shown with a different icon and are not accessible as folders in the docker container. The non-exclusive folders are accessible and behave as expected. For the Ubuntu VM, the situation is similar. I manually expose /mnt/user to the VM, but only the non-exclusive folders show as folders, the exclusive ones have an icon with an "X" and don't work (in the bottom image). I've tried both 9p and virtiofs and had the same results. Note - I don't expect any files to move automatically, I was expecting to be able to use the docker/VM to test if the write speed was improved (via drag-n-drop in the systems) skipping FUSE. Hopefully this is clearer? Are you successfully using exclusive shares? If so, can you describe what you are doing that works?
-
I didn't have an issue getting shares to be recognized as "Exclusive Access". I had trouble with both dockers and the VM being able to use the shares once they were set as exclusive access. Was that not clear from the screenshots?
-
Alrighty. `Permit exclusive shares: No`
-
Is no on else having similar issues? If there is a fix posted somewhere else, can someone share a link?
-
Hi, I've enabled exclusive shares and I have several shares on a ZFS cache pool that show as having exclusive access. Looking at /mnt/user/ in terminal, I do see three folders that are symlinks. From this, I believe my configuration is correct and working, with `appdata` being one of the exclusive access shares. The limited dockers I've tested all seem to start and run. But results are mixed: * `code-server` is able to open exclusive and non-exclusive share folders * `binhex-krusader` set per spaceinvader1's video - only non-exclusive shares are accessible (note the last 3 folders on the left are grayed out) * Ubuntu VM - only non-exclusive shares are accessible via VM mount Here is the section from the VM config: Here is the fstab config and folder view of the mount showing the 3 exclusive folders as unaccessible: It seems like different ways to access the shares are hit or miss. Are these bugs? Something I need to change in the config? Thanks!
-
What operations are safe/non-destructive? Are all operations from this docker safe, as in no damage to existing content? The first topic says "Disk Drives with platters are benchmarked by reading the drive at certain percentages", but "Solid State drives are benchmarked by writing large files to the device and then reading them back". I have two NVMe drives pooled as my cache, which makes me think testing them individually could corrupt the data on the pool. Is it correct to assume benchmarking spinner disks is safe in a running server, but testing _pooled_ solid state drives is not? If only some tests are safe, what about testing controllers? Apologies if this has been answered before - I read the first 4 pages of topics and searched for "safe" and didn't find anything that answered my question. Thanks!
-
Looks like it was a temporary issue that resolved itself. Tried a new USB with clean 6.12.6 and that worked fine. Was installing 6.12.5 (just to check), and tried the original USB drive while that was installing and networking worked with it as well. I had tried resetting various parts of the network yesterday before posting this topic - it hadn't helped. Today without actively changing anything, everything was working. While I'd love to say I knew what root cause was, I'm good with a working system. Thanks for the help!
-
Here are the diagnostics. supertower-diagnostics-20231201-0829.zip
-
I have two Unraid servers (which have been working for a while, until today) - they have different IP addresses and different names. There is another topic with the same title and a solution related to NPM - which I have been messing with, but I don't have the same message in the logs and I'm having issues even if the array is stopped. With one array powered off and the other booted into the gui, but with the array stopped, I see the powered on server on Unraid connect (2nd on shows off). With a display/keyboard/mouse directly connected to the server, I see the GUI. But the device isn't showing on the network and Unraid connect can't connect to it. the ifconfig command shows no init address for bond0, eth0, eth1, and x.x.x.142 for br0. I don't know what ifconfig showed before I was having issues, though. It shows as x.x.x.142 on the network from Google Home (I have Nest mesh wifi) which lists wired and wifi devices connected, but pinging x.x.x.142 returns timeout and I can't connect to the GUI from local web address either. I didn't change any hardware configs, but I was messing with NPM and CloudFlare tunnels while also updating both machines from 6.12.4 to 6.12.5. I was trying to change the NPM config and restart when it failed because the IP was taken, and it looks like for a while the Unraid server changed its IP address from x.x.x.142 to x.x.x.2 (the static address I assigned to NPM) (maybe?). The other server, which isn't running NPM, seemed to have the same connection issues with 6.12.5. Please help!
-
Hi, I've got AdGuard running in a docker container which lets me add a filter to an IP address and give it my domain name (DNS rewrite is another term for this I believe). The intent is to be able to use the same urls from my lan as externally, where the ip address I use would be the IP for the reverse router. The issue is that NginxProxyManager seems to require 8080 for http and 4443 for https, not the default 80/443. This means even if I set a static IP for the docker, urls won't work. If I try to port forward 80/443, that conflicts with the webUI. The solution I've been pondering is creating an additional host IP address, and then port forwarding to that. Pipework seems to be an option, or manually creating an interface alias with ifconfig. Seems like Settings->Network Settings->Routing Table could help as well. Right now I'm using a cloud flare tunnel (wildcard) and not port forwarding, but ideally the ip would be something I could port forward to if desired (which I think means needing a Mac address). Is there a recommended approach? Other alternatives to consider? TIA
-
I've got Seagate SAS drives and an LSI HBA. Sounds like there are variations of Seagate + controllers that don't work, but the UI/log seems to show my drives spinning down. But they almost immediately spin back up. Before I installed this plugin, requesting a spin down of one of the SAS drives appeared to be a no-op (the green circle would not change). After installation (actually setting the spin down to never, rebooting, setting to 1 hr, rebooting, and then installing the plugin) now shows a spinner, then gray for the a drive, but quickly spins back up. The log simply says Aug 13 12:17:40 SuperTower emhttpd: spinning down /dev/sdd Aug 13 12:17:40 SuperTower SAS Assist v2022.08.02: Spinning down device /dev/sdd Aug 13 12:17:57 SuperTower emhttpd: read SMART /dev/sdd I have turned off docker and VMs, and have basically no data on these drives yet so nothing should be trying to access the drive other than Unraid itself. I'm on 6.12.3 if that matters. Any suggestions for fixing this or troubleshooting?




