




Astatine
Members
-
Joined
-
Last visited
Everything posted by Astatine
-
Hi @JorgeB here are the diagnostics: tower-diagnostics-20260718-0606.zip
-
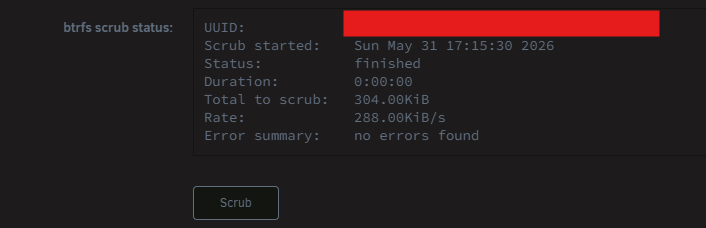
I am getting the same error. Noticed it right after upgrading to v7.3.0 Scrub found no errors for me too Pool status shows pool status:ONLINE - ERRORS The pool only has 1 SSD. It is only used as a place to download stuff to before being moved to the array so I am safe from data perspective but am concerned if it is fixable or do I need to haul ass and get a new SSD.
-
So the power went out & when I tried bringing the array up after it came back, I was doing so from my mobile which offers what basically is the desktop version of the unRAID UI highly zoomed out. I clicked something by mistake & didn't realize that both of my cache SSDs [1 SSD/pool] got unmounted somehow. The server had been running for almost 24 hours since this occurred. Now only I realized the mistake when docker services was up but no containers were there. I did bring the array down & remounted the cache drives & rebooted the server but no luck getting the containers back. Now I can see all the appdata in the cache drive. Also there is a docker.img present in /mnt/user/system/docker directory but the docker container are lost. The containers are gone as Cleanup Appdata plugin list all the appdata folders even the once that I have docker containers for. I have stopped the array for now to avoid further damage. What could be wrong here? And how should I fix this? Really don't want to spin up everyone container freshly. One difference I saw was that the docker.img in the cache drive is timestamped to be earlier than the one sitting in HDD in the array. They are front the same day but differ by multiple hours. Diagnostics attached! tower-diagnostics-20250605-0034.zip
-
Understood. I'll go through the release notes to understand the new way to do bridging. Anyways, what should I do with the potentially corrupt config? My server renamed itself to 'Tower'. ident.cfg file lists name as 'Tower'. I don't know what else might have been reset back to default. Do I need to start with 'New Config'?
-
I previously had issues with docker containers, thread linked. Which was solved by switching to macvlan. If I go back to that, can you suggest how to avoid the DNS issue again? I'll try switching back to ipvlan this evening and see if it makes things better
-
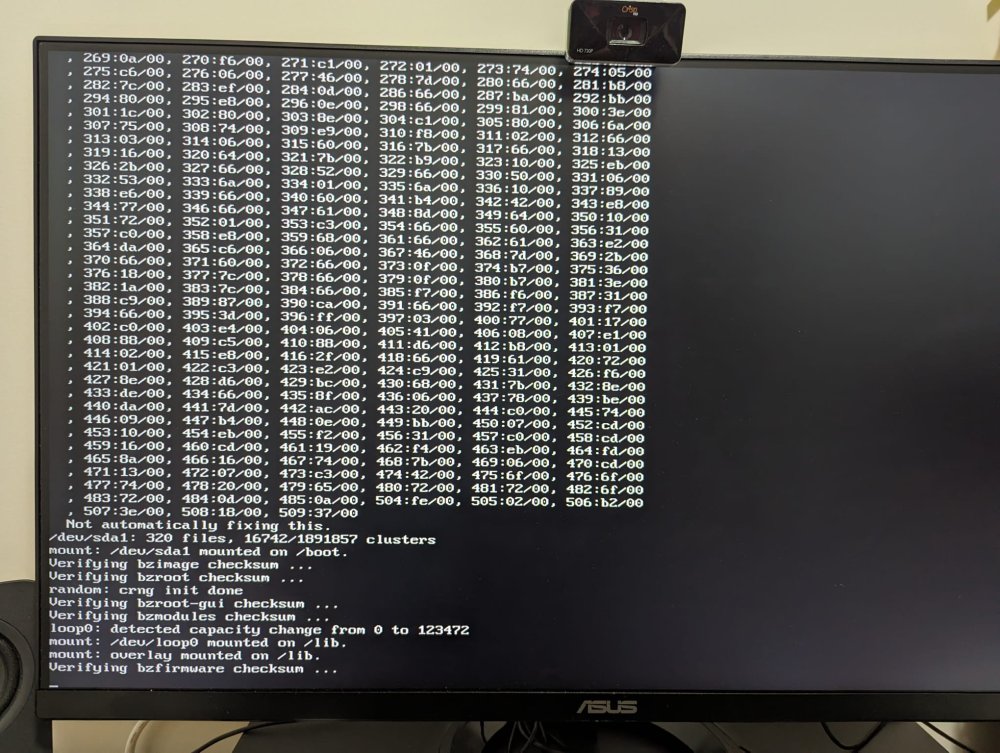
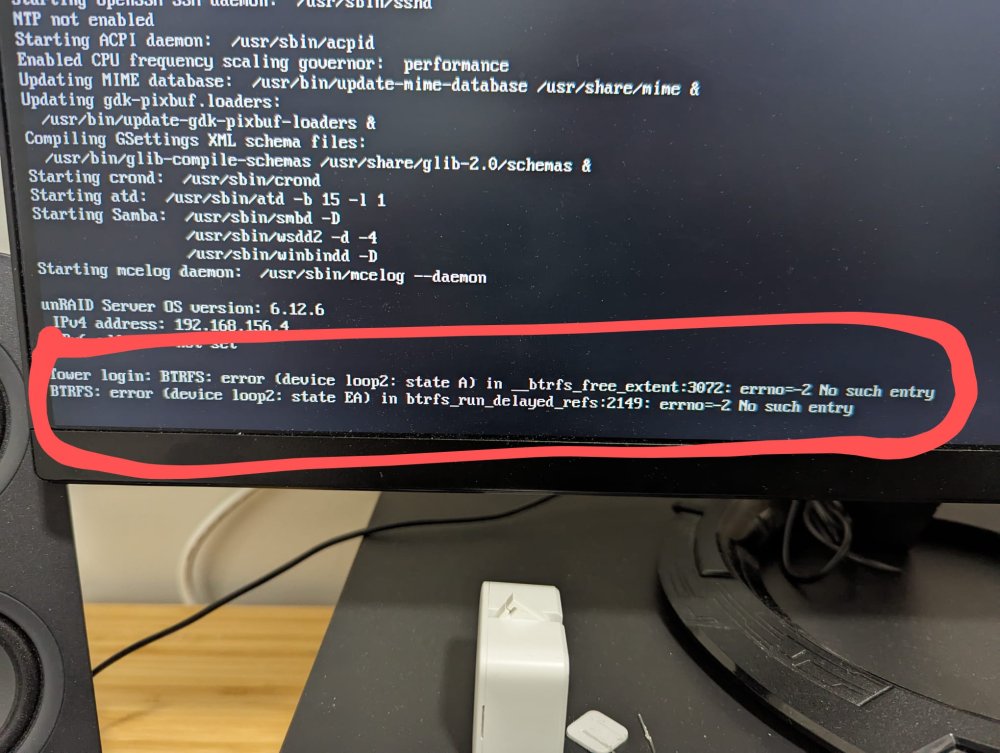
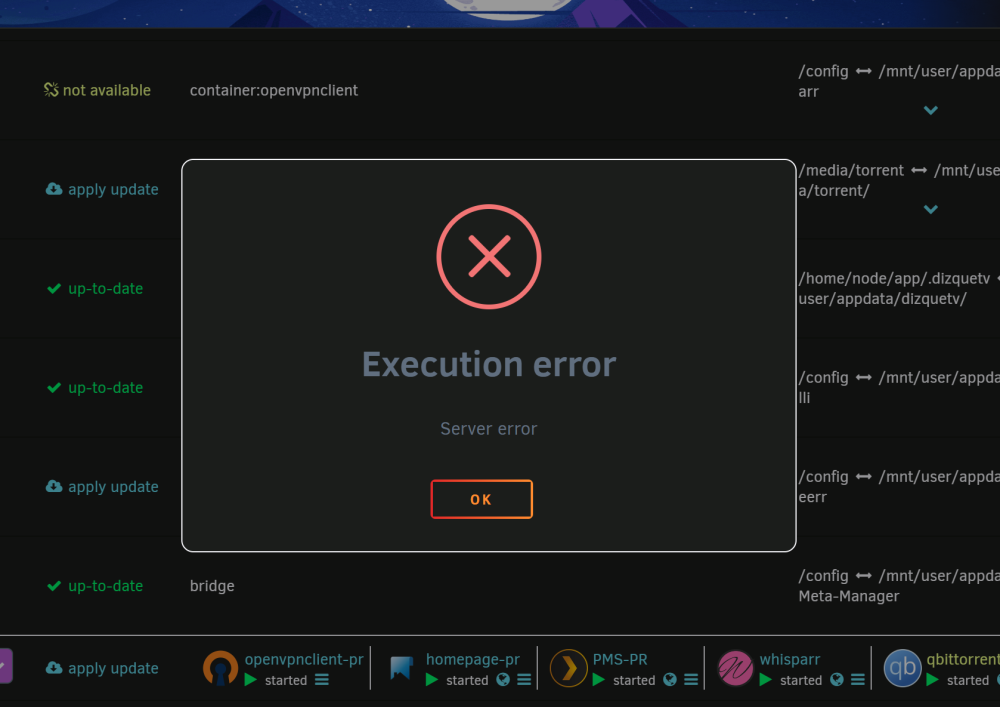
So, I was moving houses and couldn't pay attention to my UNRAID server for quite some time. I have since replaced a corrupt USB drive. Transferred my key to a new USB. It was working properly for some time but soon after that I started noticing that the server would "freeze" as in the docker services would be running but a couldn't access server using the IP. I also noticed that during boot there are these number list (my guess memory block list) which reads so: I don't understand what this is. Then the situation worsened. Now, docker containers would just randomly stop working and when tried to restart them, I would receive popup either saying "403" or "Execution error". I then either had to restart the docker service or the whole server to be able to get them to work. My guess was that the docker file is corrupted. But I couldn't still act to fix that due to life. Then the whole server started freezing. I couldn't access it over the IP, same for docker containers until I restart the machine which resulted in a ton of unclean shutdowns. And as of yesterday, after restart, the docker containers are only working for 5-10 minutes and my unraid machine name went back to "Tower" which according to this could be config issue: Server name changed from "N2" to "Tower" - General Support - Unraid Also, I am no longer able to access the server over https://[IP] but http://[IP] is showing the login screen but after entering the credentials, it doesn't take me in. Just keeps redirecting to login screen. I convinced that something is seriously off in the /config in the USB. Can someone help me track down the issue and fix it? or is it better to start from scratch? If so, when I do 'New Config' and assign the devices to their current purpose, will my data be retained? both array and cache? I understand that new config will definitely rebuild the parity. I try to somehow get the diag. report from the server directly and post it here soon Here are the diagnostics: tower-diagnostics-20240119-1839.zip Also, when I clicked 'Download' on the diagnostics page, I saw the following error on the server cli screen: Please help. It is getting very frustrating to deal with!!!!
-
Ah, I see. I just restarted in Safe Mode without Maintenance and can see the disks. Guess I turned on Maintenance Mode earlier. I didn't find something on Google hence posted. Sorry for the inconvenience.
-
Hi everyone, I am running unRAID 6.12.6 and after a reboot just now, none of the drives are showing up in /mnt I can see the drive in 'Main' tab and cannot even see the "drive explorer" button for the drives. (screenshot of Main tab) But I cannot see any shares or disks mounts in /mnt folder Please help me figure this out as to why I cannot see the none of the disk, cache or otherwise. The SMART report in the report is looking good to me but maybe I am wrong. The diagnostics report is attached to the post: astatine-diagnostics-20231216-2241.zip Thank you in advance!
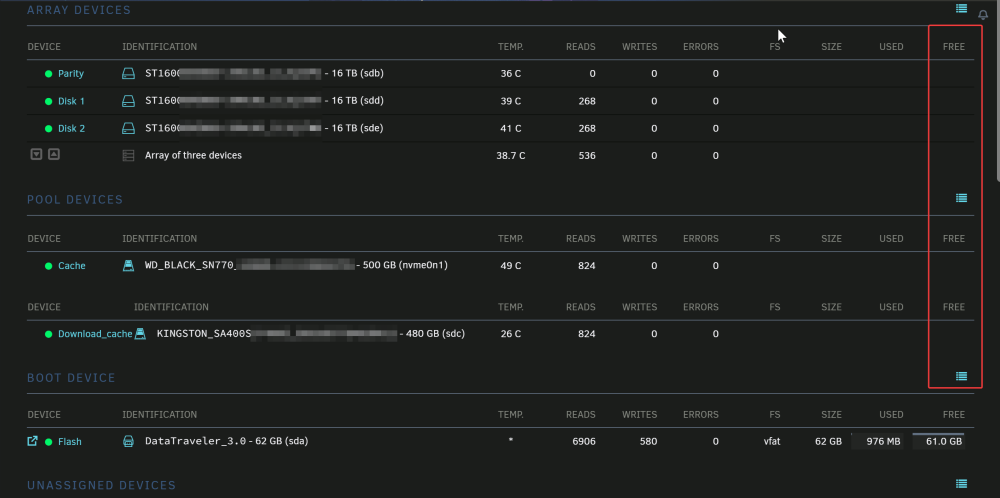
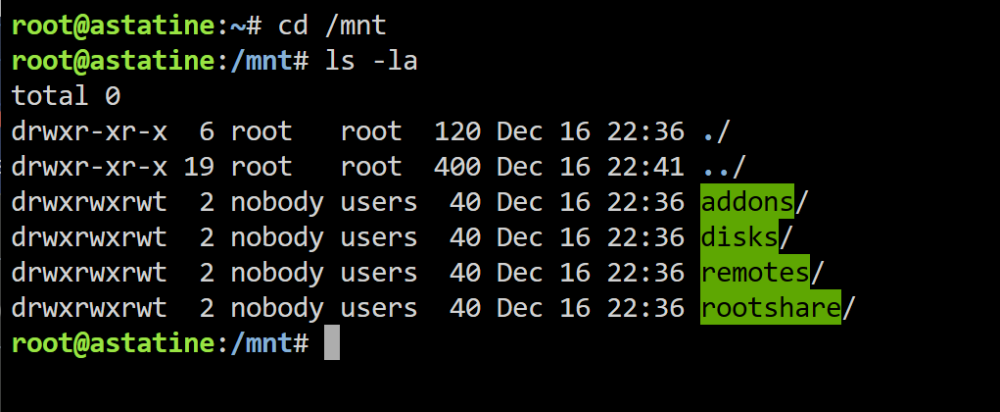
-
Just had a weird this happen to me. I pulled up the UNRAID web UI, everything working as usual. I go Apps tab and the page is upside down. The banner/header was still in the right orientation. I switch between tabs, no effect. I restart the browser and go back to Apps tab and I see a popup asking me 'Yes' or 'No' about continuing the International Bat Appreciation Day celebration. The popup dialog had a link to this webpage: https://nationaltoday.com/international-bat-appreciation-day/ Has anyone else seen this?
-
Well look at that. Changing 'ipvlan' to 'macvlan' to fixed the issue. I kept all the other settings as is. Now, I am more curious as to why ipvlan had that issue and it didn't occur for the first few minutes after reboot.
-
@JorgeB So, I did what you asked and turns out the test unRAID flash drive has 0 issues. And after going through what @autumnwalker mentioned above, I feel like it's a known issue with how docker handles networking and hasn't been fixed yet. I'll test this theory before anything else.
-
@autumnwalker Yes, I am using ipvlan + host access to custom networks because I want the prowlarr, jackett containers on Host IP to communicate with some containers that are on a different IP setup using br0 interface. I'll turn off the "host access to custom networks" and see if the issue gets fixed like it did for the folks you mentioned
-
Thanks. I'll get back to you once I've tried it.
-
Well, with all due respect, I find it hard to believe that it is not an unRAID issue. I booted the server to a live ubuntu USB and left it to ping google.com, cloudflare.com & unraid.net for more than a day and the packet loss are as follows: 0% for google.com, 0.00383547% packet loss for unraid.net & 0.00153467% packet loss for cloudflare.com. So, I believe this rules out the possibility of a hardware issue. - Not a router issues as all my other devices are working just fine connecting to the outside world - Not a switch issue as all the other devices connected to the switch are working fine + unRAID server also get connection for 10-15 minutes after reboot and then loses DNS - Not a hardware issue as booting into live ubuntu USB doesn't seem to have the same DNS resolution issue as the unRAID server With this new information on hand, I can confidently say that it is an unRAID issue, whether it originates from the OS or a corrupted config file, that's a different story. ping_cloudflare.txt ping_google.txt ping_unraid.txt
-
I am open to setting up everything from the scratch. How can I have a fresh start without using the limited USB Key resets? I believe all the parity data, appdata, etc. will just remain the same in the new install so long as I assign the correct drive back to the same purpose. As for docker container install, I am willing to do it again and point the new containers to old appdata to bring server back to my latest state. Is there a way to accomplish the above?
-
Yeah, totally agreed. Time sync issue seems to have occurred due to loss of connection and not the other way around. However, I there something else that comes to mind in how to diagnose the real issue? I'm going to try booting into a live ubuntu install later in the evening and observe if something similar happens in that too. In the meantime, I was also wondering if there is way to do a fresh install of unRAID while keeping my config and settings intact. That way, if there is a corrupt file somewhere, it would be fixed. Thoughts?
-
Great idea. Gonna do this ASAP. Thanks!!!
-
So, I was looking online and found that sometimes the 'Clock Unsync' issue is caused because the BIOS time is incorrect. So, I checked that and lo & behold, the time is correct. As expected the time is in UTC and it correct. Which means we can rule out a faulty CMOS battery, right @MAM59? Anyways, good thing after my recent reboot, I am no longer seeing any clock out of sync errors. However, internet connection remains
-
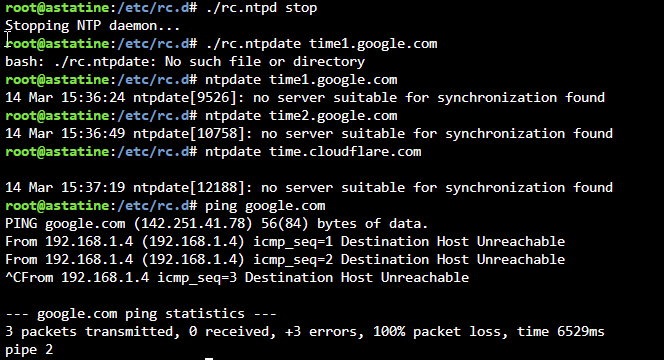
@JorgeBOkay, so waited about an hour after booting into safe mode. The server had lost connection. I guess we can rule out a bad plugin from the things causing the issue @MAM59I rebooted and used the following commands to resync ntp /etc/rc.d/rc.ntpd stop ntpdate time.cloudflare.com /etc/rc.d/rc.ntpd restart Right after restarting the service. I checked the logs and found this Mar 14 16:33:36 astatine ntpd[1153]: ntpd exiting on signal 1 (Hangup) Mar 14 16:33:36 astatine ntpd[1153]: 127.127.1.0 local addr 127.0.0.1 -> <null> Mar 14 16:33:36 astatine ntpd[1153]: 216.239.35.0 local addr 192.168.1.4 -> <null> Mar 14 16:33:36 astatine ntpd[1153]: 216.239.35.4 local addr 192.168.1.4 -> <null> Mar 14 16:33:36 astatine ntpd[1153]: 216.239.35.8 local addr 192.168.1.4 -> <null> Mar 14 16:33:36 astatine ntpd[1153]: 216.239.35.12 local addr 192.168.1.4 -> <null> Mar 14 16:35:02 astatine ntpd[18956]: ntpd [email protected] Fri Jun 3 04:17:10 UTC 2022 (1): Starting Mar 14 16:35:02 astatine ntpd[18956]: Command line: /usr/sbin/ntpd -g -u ntp:ntp Mar 14 16:35:02 astatine ntpd[18956]: ---------------------------------------------------- Mar 14 16:35:02 astatine ntpd[18956]: ntp-4 is maintained by Network Time Foundation, Mar 14 16:35:02 astatine ntpd[18956]: Inc. (NTF), a non-profit 501(c)(3) public-benefit Mar 14 16:35:02 astatine ntpd[18956]: corporation. Support and training for ntp-4 are Mar 14 16:35:02 astatine ntpd[18956]: available at https://www.nwtime.org/support Mar 14 16:35:02 astatine ntpd[18956]: ---------------------------------------------------- Mar 14 16:35:02 astatine ntpd[18960]: proto: precision = 0.034 usec (-25) Mar 14 16:35:02 astatine ntpd[18960]: basedate set to 2022-05-22 Mar 14 16:35:02 astatine ntpd[18960]: gps base set to 2022-05-22 (week 2211) Mar 14 16:35:02 astatine ntpd[18960]: Listen normally on 0 lo 127.0.0.1:123 Mar 14 16:35:02 astatine ntpd[18960]: Listen normally on 1 br0 192.168.1.4:123 Mar 14 16:35:02 astatine ntpd[18960]: Listen normally on 2 lo [::1]:123 Mar 14 16:35:02 astatine ntpd[18960]: Listening on routing socket on fd #19 for interface updates Mar 14 16:35:02 astatine ntpd[18960]: kernel reports TIME_ERROR: 0x41: Clock Unsynchronized Mar 14 16:35:02 astatine ntpd[18960]: kernel reports TIME_ERROR: 0x41: Clock Unsynchronized kernel reports TIME_ERROR: 0x41: Clock Unsynchronized
-
Okay. I'm checking what JorgeB suggested. Booted in safe mode. I'll observe the server for a while in safe mode and after ntpdate. Just bear with my stupid questions. I just want to understand as much as I can in case something like this happens in the future.
-
I tried this. I believe the ntp errors are coming because the npt daemon isn't able to connect with remote "clock" due to DNS issue
-
@JorgeB@itimpi So, I gave up on the server last night and left it on its own. Turns out a couple hours after the network reset yesterday, the server behavior changed. Now the server is connecting on and off. And I am getting new errors in the log(s). I have attached the latest diagnostics to this post. Here's a snippet of the new error(s) that I am seeing. Mar 13 11:52:22 astatine avahi-daemon[23598]: Joining mDNS multicast group on interface vethf5a568d.IPv6 with address fe80::c86c:29ff:fead:e306. Mar 13 11:52:22 astatine avahi-daemon[23598]: New relevant interface vethf5a568d.IPv6 for mDNS. Mar 13 11:52:22 astatine avahi-daemon[23598]: Registering new address record for fe80::c86c:29ff:fead:e306 on vethf5a568d.*. Mar 13 11:52:22 astatine avahi-daemon[23598]: Joining mDNS multicast group on interface veth25e0c9f.IPv6 with address fe80::44e7:81ff:fe1d:5a72. Mar 13 11:52:22 astatine avahi-daemon[23598]: New relevant interface veth25e0c9f.IPv6 for mDNS. Mar 13 11:52:22 astatine avahi-daemon[23598]: Registering new address record for fe80::44e7:81ff:fe1d:5a72 on veth25e0c9f.*. Mar 13 11:52:23 astatine avahi-daemon[23598]: Joining mDNS multicast group on interface veth21f1006.IPv6 with address fe80::307a:a5ff:fe6a:307e. Mar 13 11:52:23 astatine avahi-daemon[23598]: New relevant interface veth21f1006.IPv6 for mDNS. Mar 13 11:52:23 astatine avahi-daemon[23598]: Registering new address record for fe80::307a:a5ff:fe6a:307e on veth21f1006.*. Mar 13 11:52:23 astatine avahi-daemon[23598]: Joining mDNS multicast group on interface veth3e1bea2.IPv6 with address fe80::409b:19ff:febd:db3e. Mar 13 11:52:23 astatine avahi-daemon[23598]: New relevant interface veth3e1bea2.IPv6 for mDNS. Mar 13 11:52:23 astatine avahi-daemon[23598]: Registering new address record for fe80::409b:19ff:febd:db3e on veth3e1bea2.*. Mar 13 17:25:47 astatine nginx: 2023/03/13 17:25:47 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 13 17:25:47 astatine nginx: 2023/03/13 17:25:47 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 13 17:25:47 astatine nginx: 2023/03/13 17:25:47 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 13 17:42:32 astatine ntpd[7970]: no peer for too long, server running free now Mar 13 18:17:31 astatine ntpd[7970]: no peer for too long, server running free now Mar 13 18:24:29 astatine webGUI: Successful login user root from <tailscale ip of my phone> Checkout the log at timestamp: Mar 13 20:07:29 Mar 13 18:27:07 astatine avahi-daemon[23598]: Joining mDNS multicast group on interface veth641d21e.IPv6 with address fe80::78a8:91ff:fee9:b4be. Mar 13 18:27:07 astatine avahi-daemon[23598]: New relevant interface veth641d21e.IPv6 for mDNS. Mar 13 18:27:07 astatine avahi-daemon[23598]: Registering new address record for fe80::78a8:91ff:fee9:b4be on veth641d21e.*. Mar 13 20:07:29 astatine ntpd[7970]: receive: Unexpected origin timestamp 0xe7ba3941.9078c3b0 does not match aorg 0000000000.00000000 from [email protected] xmt 0xe7ba3940.e57b3745 Mar 14 00:59:48 astatine nginx: 2023/03/14 00:59:48 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 14 00:59:48 astatine nginx: 2023/03/14 00:59:48 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 14 00:59:48 astatine nginx: 2023/03/14 00:59:48 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 14 02:00:01 astatine root: mover: started Mar 14 02:00:03 astatine root: mover: finished Mar 14 02:22:58 astatine nginx: 2023/03/14 02:22:58 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 14 03:53:35 astatine nginx: 2023/03/14 03:53:35 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 14 03:53:35 astatine nginx: 2023/03/14 03:53:35 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 14 03:53:35 astatine nginx: 2023/03/14 03:53:35 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 14 04:23:08 astatine ntpd[7970]: no peer for too long, server running free now Mar 14 05:29:33 astatine nginx: 2023/03/14 05:29:33 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 14 05:29:33 astatine nginx: 2023/03/14 05:29:33 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 14 05:29:33 astatine nginx: 2023/03/14 05:29:33 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 14 06:18:35 astatine nginx: 2023/03/14 06:18:35 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 14 07:59:39 astatine ntpd[7970]: no peer for too long, server running free now Mar 14 09:02:32 astatine ntpd[7970]: no peer for too long, server running free now Mar 14 09:31:20 astatine ntpd[7970]: no peer for too long, server running free now Mar 14 10:23:03 astatine nginx: 2023/03/14 10:23:03 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 14 10:23:03 astatine nginx: 2023/03/14 10:23:03 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 14 10:23:03 astatine nginx: 2023/03/14 10:23:03 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 14 10:23:03 astatine nginx: 2023/03/14 10:23:03 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 14 10:23:03 astatine nginx: 2023/03/14 10:23:03 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 14 10:23:03 astatine nginx: 2023/03/14 10:23:03 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 14 10:23:04 astatine nginx: 2023/03/14 10:23:04 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 14 10:23:04 astatine nginx: 2023/03/14 10:23:04 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 14 10:23:04 astatine nginx: 2023/03/14 10:23:04 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 14 10:23:05 astatine nginx: 2023/03/14 10:23:05 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 14 10:23:06 astatine nginx: 2023/03/14 10:23:06 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen. Mar 14 10:23:07 astatine nginx: 2023/03/14 10:23:07 [error] 3949#3949: nchan: A message from the past has just been published. Unless the system time has been adjusted, this should never happen.
-
I am not using a custom router/modem. I have a Bell connection and use the router/modem provided by them. It's a Bell Home Hub 4000
-
v6.11.5
-
Already done that. No luck. It works fine for 10-15 minutes after saving the changes and then back to square one. No connection. Pings failing.






