




Infosucher
Members
-
Joined
-
Last visited
Everything posted by Infosucher
-
Alles klar, das kenne ich. Dafür gibt es seit September 25 ein Firmware Update. Unter Reddit berichten die User jetzt keine Probleme mehr zu haben. Vielen Dank für den Hinweis. Gruß Infosucher
-
Kannst Du das näher beschreiben? Ich finde dazu nicht wirklich was. Gruß Infosucher
-
Hallo zusammen, ich nutze aktuell Unraid 7.2.0 mit folgender Hardware: UnRaid 7.2.0 | Mainboard: ASUS PRIME B760-PLUS D4 | CPU: Intel Core i7-12700K, 6C+8c/20T | RAM: Crucial Pro DIMM Kit 64GB, DDR4-3200, CL22-22-22 (CP2K32G4DFRA32A) | Array: Parity -> Seagate EXOS X20 20TB| Disk 1-> Western Digital WD80EFPX Red 8TB | Disk 2-> SEAGATE ST14000NE0008 14 TB Ironwolf Pro | Cache-Pool (VM´s & Docker): Samsung 980 PRO NVMe M.2 SSD 1TB (xfs) | Second Pool -> Western Digital WD30EFRX Red 3TB Die Cache NVMe soll jetzt von 1TB (xfs) auf 2TB (Samsung 990 Pro) (xfs) aufgerüstet werden. Dafür soll die alte NVMe Platz machen und wandert anschließend in einen anderen Rechner. Wie gehe ich am Besten vor, damit keine Daten verloren gehen? Zuvor ziehe ich mir erstmal alles was auf dem alten Cache ist, als Backup auf ein anderes NAS, das ist soweit klar. Die Idee ist dann wie folgt: Alle Docker und VM´s stoppen und den Docker sowie VM Dienst im Anschluss auch. Alle Shares, die ausschließlich auf den Cache liegen, als sekundären Speicher das Array, zuweisen. Dann den Mover starten und warten bis alles übertragen wurde. Anschließend als primären Speicher der Shares das Array auswählen und damit den Cache komplett "aushebeln". Damit sollte das System meiner Meinung nach "cachelos" sein. Das Array stoppen und das Cachelaufwerk abwählen. Dann Array nochmal starten und schauen ob es normal hochfährt. Wenn ja, Array wieder stoppen und UnRaid herunterfahren. Alte NVMe ausbauen und die Neue dafür einsetzen. UnRaid starten und bei Cache das neue Laufwerk auswählen. Anschließend das Array starten. Dann in den gewünschten Shares wieder sekundären Speicher (Cache) einstellen und den Mover starten. Anschließend als primären Speicher das Cache auswählen und den sekundären Speicher deaktivieren, fertig? Ja das ist die Frage. Ist das Vorgehen so wirklich korrekt? Vergisst UnRaid das alte Laufwerk oder zeigt es mir einen Fehler an, weil das alte Laufwerk vermisst wird? Muss ich ggfs. noch "Neue Konfiguration" mit "aktiver Zuweisung behalten" laufen lassen? -> Wenn ja, an welcher Stelle in meiner Auflistung? Auch wenn ich von den wichtigsten Daten ein Backup habe, möchte ich mir das Wiederherstellen dennoch sparen. Danke Euch. Gruß Infosucher
-
Hallo zusammen, ich nutze im Docker die postgresql14 für Immich. Ich möchte gerne auf die neueste Version updaten, damit ich die nächsten Jahre erstmal Ruhe habe. Wie genau muss ich denn in Unraid vorgehen, damit mir meine Datenbank nicht verloren geht und ich nahtlos mit Immich weiterarbeiten kann. Ich müsste meine Datenbank unter der jetztigen Version 14 ja sichern und später in Version 17 wieder einspielen. Oder reicht die Angabe des Appdata Ordner von postgresql14 aus? Wahrscheinlich eher nicht. Danke Euch. Gruß Infosucher
-
OK vielen Dank. Ich stelle mir immer die Frage, warum es ein 32 GB Stick sein muss? Mein Stick ist nahezu leer. Reicht das nicht auch locker ein 16 GB Stick? Oder was genau ist der Hintergrund? Gruß Infosucher
-
OK das ist soweit erstmal klar. Welchen Stick genau kannst Du empfehlen, damit ist einfach schon mal eine Reserve parat habe? Und womit sollte ich das Backup zurück spielen? Das habe ich nämlich schon lokal gezogen. Mit dem UnRaid Tool? Und kann ich die FSK Dateien löschen? Gruß Infosucher
-
Hi zusammen, ich habe heute von 7.0.1 auf 7.1.4 geupdatet und bekam im Log vorhin diese Fehlermeldung: Jun 20 12:10:30 Tower kernel: usb 1-10: device descriptor read/64, error -110Zum besseren Verständnis habe ich noch die Diagnosedaten mit angehangen, da eine Zeile alleine in der Regel nicht aussagekräftig genug ist. Als USB Stick verwende ich einen JetFlash Transcend 32GB. Was genau bedeutet die Fehlermeldung bei Unraid und wie kann ich prüfen, ob der Stick ggfs. defekt ist? Danke Euch. Gruß Infosucher PS: Mir fällt gerade auf, dass sich auf dem Stick folgende Dateien befinden: FSCK0000.REC und weiter... Das deutet wohl auf einen Dateisystemfehler auf dem Stick hin. Noch läuft alles ganz normal. Sollte ich den Stick lieber tauschen? Gibt es Unraid intern eine Möglichkeit den Stick zu prüfen und ggfs. Fehler zu beheben, sofern kein Hardwaredefekt vorliegt? tower-diagnostics-20250620-2250.zip
-
Erstmal danke für Deine Hilfe. Ich kam leider erst jetzt wieder dazu weiter zu testen. Ich habe es jetzt wie folgt gelöst: Der Zeitplan in Luckybackup ist denke ich klar. Das klappt auch wunderbar. Danach habe ich in User Scripts folgendes Skript für einen Watchdog erstellt: #!/bin/bash CONTAINER_NAME="luckyBackup" LOG_PATH="/mnt/user/appdata/luckybackup/.luckyBackup/logs" WAIT_TIME=60 # Zeit zwischen Prüfungen (in Sekunden) echo "[WATCHDOG] Starte Überwachung von LuckyBackup-Jobs..." while true; do RUNNING=$(docker exec "$CONTAINER_NAME" pgrep rsync) if [[ -z "$RUNNING" ]]; then echo "[WATCHDOG] Kein rsync-Prozess gefunden. LuckyBackup ist offenbar fertig." echo "[WATCHDOG] Warte 10 Sekunden und prüfe erneut..." sleep 10 RUNNING_AGAIN=$(docker exec "$CONTAINER_NAME" pgrep rsync) if [[ -z "$RUNNING_AGAIN" ]]; then echo "[WATCHDOG] Bestätigt: Alle Jobs beendet. Container wird neugestartet." docker restart "$CONTAINER_NAME" exit 0 fi else echo "[WATCHDOG] LuckyBackup läuft noch... (rsync-Prozess aktiv)" fi sleep "$WAIT_TIME" done Dieses Skript habe ich dann mit den folgenden CRON Optionen unter Custom automatisiert: 0 8 * * 0 Somit wird jeden Sonntag um 8 Uhr geprüft, ob der Backupjob von Luckybackup bereits beendet ist. Das ist er auf jeden Fall, da dieser bereits um 1 Uhr beginnt. Da es nur noch inkrementell läuft, sind die Datenmengen überschaubar und somit auch bis 8 Uhr immer fertig. Der Dockercontainer startet wunderbar automatisch neu und ich kann in der Historie das Backup aus der letzten Nacht sehen. Ich markiere das mal Lösung für mich. Gruß Infosucher
-
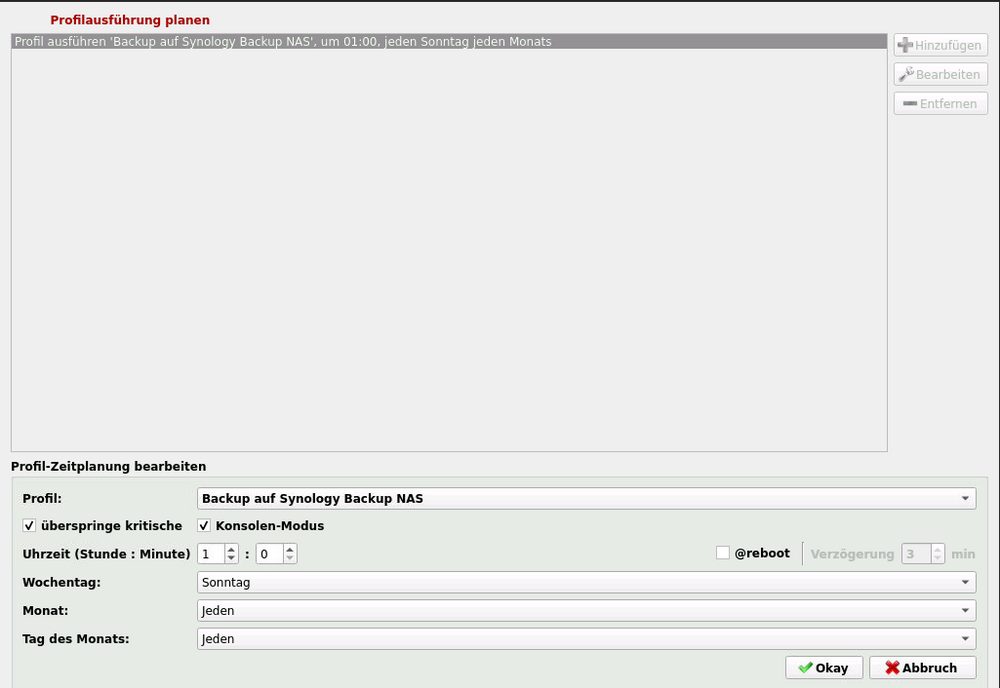
Hallo zusammen, ich möchte gerne ein automatisches Backup eines bestehenden Profils in LuckyBackup einrichten. Dafür habe ich in dem Dockercontainer selbst den Zeitplaner verwendet und das gewünschte Profil wie folgt konfiguriert: Im Anschluss habe ich das ganze in die Cron Datei schreiben lassen und dann manuell ausgeführt. Soweit so gut. Wird der Job jetzt immer wie geplant am Sonntag um 1 Uhr Nachts ausgeführt? Ich meine gelesen zu haben, dass ich das aber nicht sehen kann in der Sicherungsverwaltung, weil der Container nach dem automatischen Backup erst neu gestartet werden muss. Dafür würde ich gerne ein Skript in User Scripts verwenden, was mir leider nicht gelingt. Das Skript sieht wie folgt aus: #!/bin/bash # Name des LuckyBackup Docker-Containers CONTAINER_NAME="luckyBackup" # Backup-Befehl innerhalb des Containers ausführen docker exec "$CONTAINER_NAME" luckybackup --run --profile "Backup auf Synology Backup NAS" export QT_QPA_PLATFORM=offscreen # Überprüfen, ob der Backup-Befehl erfolgreich war if [ $? -eq 0 ]; then echo "Backup erfolgreich durchgeführt. Container wird neu gestartet." # Container neu starten docker restart "$CONTAINER_NAME" else echo "Fehler beim Backup. Container wird nicht neu gestartet." fiDer Container startet zwar jetzt neu, aber der Backupbefehl wird nicht ausgeführt. Mit dem Skript ist das natürlich doppelt gemoppelt, weil ich damit den Zeitplaner von LuckyBackup umgehe. Ich weiß leider nicht, wie ich den Container, nach einem erfolgreichen Backup über den Container eigenen Zeitplaner, zum Neustart bewegen kann. Ich hoffe mir kann jemand helfen. Vielen Dank. MfG Infosucher
-
Das ist ein Problem von Immich selber. Immich verfolgt das Prinzip Taggen und Datum der Aufnahme. Das nervt mich auch total an dem Programm. Eigentlich ist Immich eine super Alternative, aber Unteralben lassen sich leider nicht anlegen. Es gibt auch diverse Beschwerden dazu auf Github und auch Du solltest Dich dieser anschließen. Vielleicht kommen die Entwickler dann doch nochmal dazu, das einzufügen! Denn Subalbums machen mehr als Sinn. Gruß Infosucher
-
Soll das so einfach gehen, ohne eine DynDNS? Gruß Infosucher
-
Ich habe leider ein sehr ähnliches Problem. Ich nutze für Backups Lucky Backup. Und wenn das große Datenmengen auf mein Synology NAS als Backup rüberkopiert, hängt sich Unraid irgendwann einfach auf. Ich weiß leider bis heute nicht warum. Vielleicht haben wir ja beide gemeinsam was auf dem Server laufen, was das verursacht und können so ggfs. andere davor warnen. Gruß Infosucher
-
Wenn ich das mit dem localhost mache, klappt das auch. Das Einzige was mich wundert, ist die hohe Antwortzeit von aktuell 1.591ms. Das war bei dem anderen vorher eingetragenen DNS noch höher. Aber eigentlich sollte ich ja im zweistelligen ms Bereich liegen. Das ist irgendwie nicht der Sinn der Sache. Gruß Infosucher
-
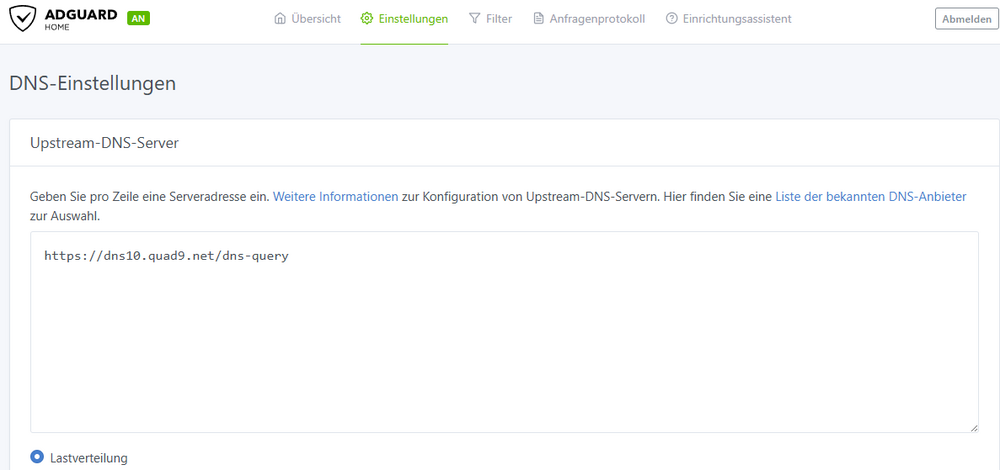
Ah ok unter Upstream ist bei mir das hier eingetragen: Demnach muss ich das noch ändern in 127.0.0.1:8053? Gruß Infosucher
-
Genau den Container nutze ich ja. Ich weiß nur nicht wie ich jetzt den Unbound aktivieren kann. Gruß Infosucher
-
Das ist tatsächlich interessant. Allerdings habe ich den folgenden Link gefunden: https://github.com/Mainfrezzer/adguardhome-unbound/pkgs/container/adguardhome Ich glaube Unbound ist demnach noch nicht aktiv. Aber ich verstehe nicht so ganz wie ich ihn nun aktiviere. DNSSEC ist unter den Einstellungen von Adguard deaktiviert. Wie genau bekomme ich jetzt Unbound zum Laufen?🤔 Gruß Infoscher
-
Ok kleines Update, wenn ich jetzt nur die IP 192.168.1.248 eingebe, dann funktioniert der Zugriff auf die WebGUI direkt. Auch ohne Angabe des Ports. Ich hatte da ein kleines Verständnisproblem. Denn der Port 3000 ist nur für die Einrichtung von AdGuard, danach ist AdGuard auf Port 80 für die WebGUI. Wie genau funktioniert das jetzt aber mit dem integrierten Unbound? Der lässt sich ja nicht gezielt konfigurieren und eine eigene IP vergeben! Auch kann man nur die Weboberfläche von AdGuard öffnen. Unbound läuft einfach im Hintergrund und ich verlasse mich darauf? Gruß Infosucher
-
Danke für deine Mühe. Jetzt habe ich die IP 192.168.1.248 für den Adguard Unbound Container verwendet. Wenn ich dann unter Docker bei Adguard auf WebGUI gehe lädt er die Oberfläche nicht, da er die IP ohne den Port aufruft. Wenn ich dann aber in der Adresszeile den Port 3000 hinter die IP schreibe lädt er die GUI. Versuche ich direkt in der Containerkonfiguration hinter der IP den Port zu schreiben, sagt er mir das ich keine gültige IPv6 Adresse verwende. Ich würde schon gerne wollen das die Funktion WebGUI auch läuft ohne die Adresszeile anzupassen. Gruß Infosucher
-
Danke für die Antwort. Das habe ich auch schon probiert. Dann kann ich die WebGUI nicht öffnen. Er lädt sich dann zu Tode. Gruß Infosucher
-
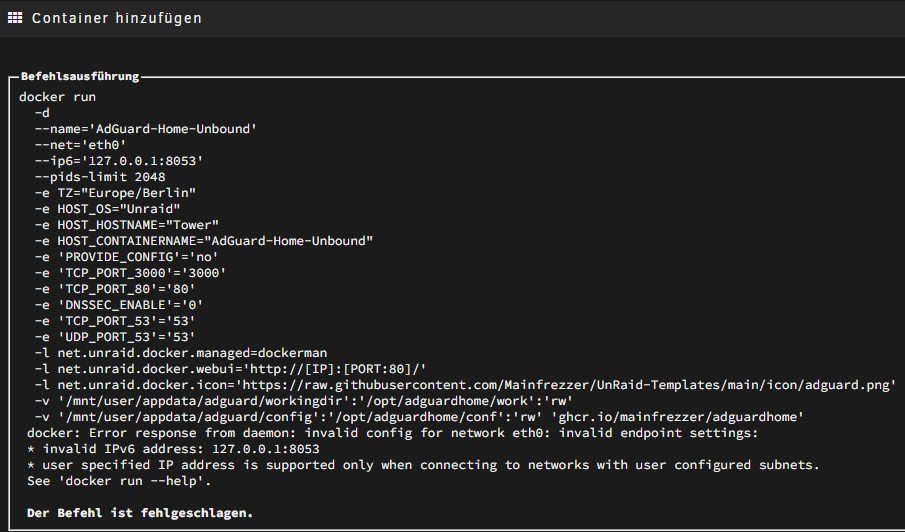
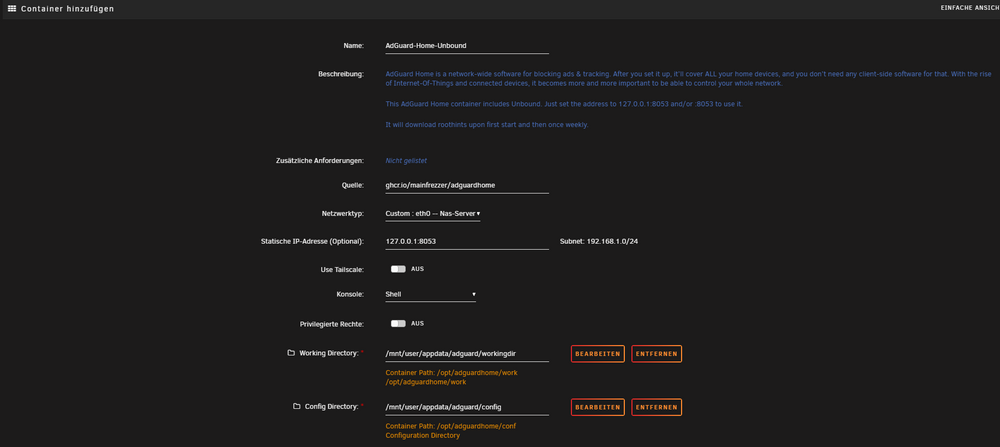
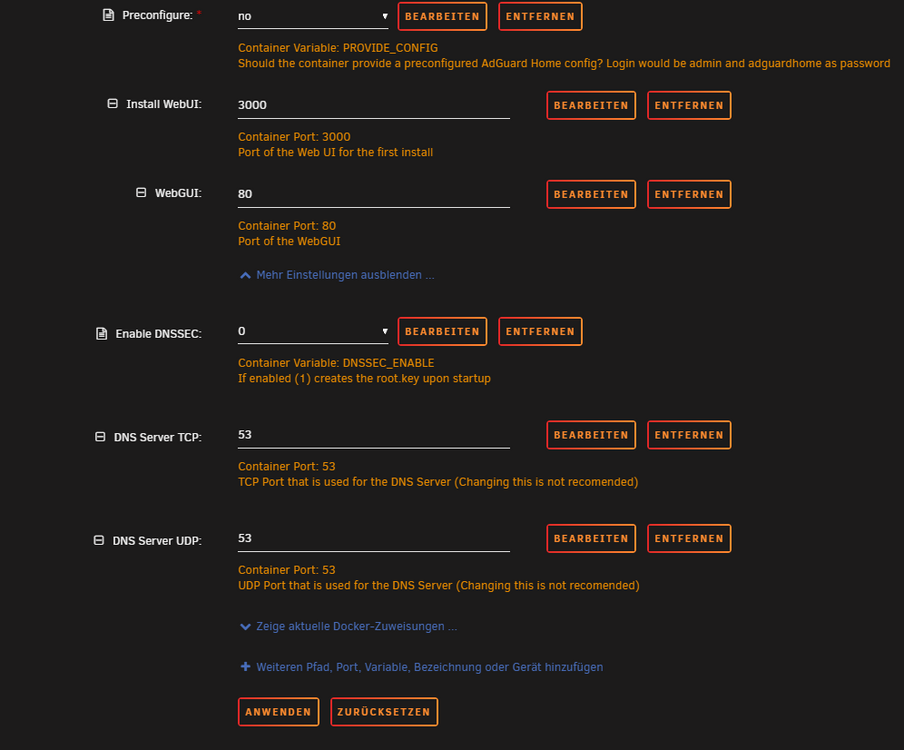
Hallo zusammen, ich habe versucht Pi-Hole und AdGuard zu installieren. Beide schlagen fehl mit der folgenden Fehlermeldung: So wirklich werde ich unten aus der Fehlermeldung nicht schlau. Selbst wenn ich meine statische Unraid IP 192.168.1.250 mit dem Port eingebe, was ja schlussendlich auf das Selbe hinaus läuft, kommt die Fehlermeldung. Meine Fritzbox hat die IP 192.168.1.1. Was genau mache ich da falsch? Hier die Config des Containers: Der Port 3000 ist auch frei. Liegt es an dem Subnet von 192.168.1.0/24? Im Anhang sind noch meine Diagnosefiles. Danke für Eure Hilfe. Gruß Infosucher tower-diagnostics-20250311-1716.zip
-
Hello, I have a quick question. Is the flash backup function exactly the same as when I click on flash backup under my USB stick on flash disk settings? Thanks Infosucher
-
Das hilft vielleicht nicht wirklich weiter, aber ich hatte sehr ähnliche Probleme am Anfang. Habe auch Memtest, sogar für 48h, laufen lassen. Keine Fehler. Schlussendlich war es die 14600er Intel CPU. Diese habe ich in einem anderen Rechner getestet und dieser schmierte sofort ab. Zuvor hatte ich den RAM und das Board getauscht. Nichts hat was gebracht. Erst als die CPU eine andere war, war alles wieder gut. Auch wenn Du eine 12 Gen hast, würde ich das nicht unversucht lassen! Gruß Infosucher
-
Das mache ich ja tatsächlich immer mit dem Tool Appdata Backup. Da wird der Container vorher immer automatisch angehalten und im Anschluss des Backups wieder gestartet. Gruß Infosucher
-
Hallo zusammen, da ich mich gerade etwas in Immich einarbeite, welches die Informationen der Bilder in der Postgre DB speichert, möchte ich natürlich sicher gehen, dass diese Datenbank auch von meinen Backups sauber erschlossen wird und im Notfall wieder hergestellt werden kann. Reicht es hier tatsächlich aus, den postgresql Ordner aus appdata zu sichern um im Bedarfsfall nach einer Neuinstallation des Containers den Ordner wieder in appdata zu kopieren und den Container zu starten? Oder muss ich noch einen Export der Datenbank aus dem Container selbst durchführen? Vielen Dank. Gruß Infosucher
-
Ich habe mich jetzt für Immich entschieden und arbeite mich gerade darin ein. Den Datenordner von Immich habe ich auf den NVMe SSD Cache ausgelagert. Dadurch ist das System im Allgemeinen sehr flott. Ich schaue direkt mal weiter. Vielen Dank. PS: Die Installation der SQL Datenbank war etwas holprig, aber schlussendlich habe ich es doch noch hinbekommen. Gruß Infosucher






