NominallySavvyTechPerson
Members
-
Joined
-
Last visited
Everything posted by NominallySavvyTechPerson
-
I copied stuff to the array from an unassigned device. I have a cache pool and the mover runs on a schedule and moves from the cache pool to the array. I'd like to be able to kick off the initial copy from the unassigned device and come back to see it has been moved to the array. Currently, I kick off the copy and then come back to a stuck mover that I need to kill. Should I just edit my /boot/config/go file to create a custom mover script in /root/.local/bin/ ?
-
Instead of ``` find "${SHAREPATH%/}" -depth | /usr/local/bin/move $DEBUGGING ``` I think it should be ``` find "${SHAREPATH%/}" -depth \( ! -type p \) | /usr/local/bin/move $DEBUGGING ``` The mover would get stuck a lot and I looked into it today. I found that it gets stuck on named pipes. IIUC it's a special file and not something that can be moved. I updated the mover script to skip the named pipes and now I'm happy. I don't see the mover script in /boot, how can I make this change permanent? Thanks! Relevant part of the mover script below. ``` # Check for objects to move from pools to array for POOL in /boot/config/pools/*.cfg ; do for SHAREPATH in /mnt/$(basename "$POOL" .cfg)/*/ ; do SHARE=$(basename "$SHAREPATH") if grep -qs 'shareUseCache="yes"' "/boot/config/shares/${SHARE}.cfg" ; then find "${SHAREPATH%/}" -depth \( ! -type p \) | /usr/local/bin/move $DEBUGGING fi done done # Check for objects to move from array to pools ls -dvc1 /mnt/disk[0-9]*/*/ | while read SHAREPATH ; do SHARE=$(basename "$SHAREPATH") if grep -qs 'shareUseCache="prefer"' "/boot/config/shares/${SHARE}.cfg" ; then eval $(grep -s shareCachePool "/boot/config/shares/${SHARE}.cfg" | tr -d '\r') if [[ -z "$shareCachePool" ]]; then shareCachePool="cache" fi if [[ -d "/mnt/$shareCachePool" ]]; then find "${SHAREPATH%/}" -depth \( ! -type p \) | /usr/local/bin/move $DEBUGGING fi fi done ```
-
I added the drive to the array and unRAID zeroed out the drive.
-
Thanks!
-
Ok, I think I see. What I should be asking is "can I add a zpool to unraid" which is already asked in that post that I linked to.
-
Oh, maybe I understand now. Unraid looks at each drive and opens the filesystem there and merges them together. If I made a zpool out of two of them, I wouldn't have a filesystem on either of the two drives. Unraid would just ask me if I wanted to format the drives because they don't have any filesystem.
-
Sorry, that went over my head. I found this where someone talks about adding a zpool to the unraid array. I'm not trying to add a zpool to the array... wait, am I? I was thinking that there was a difference between adding a whole zpool of drives as if it were a single slot in unraid (not supported) vs what I want to do where I would fill two slots in unraid with two drives. Then, unknown to unraid, I can make a zpool out of the two drives.
-
IIUC if I want snapshots of a share, I can format one array drive as zfs and limit the share to that drive. If I want more space than that, can I make a zpool out of two zfs drives in my unraid array? That way, I can snapshot the zpool and have a snapshot of the share even though the share is too big to fit on one drive. I wouldn't use RAIDZ and would rely on unraid's parity to give some protection. Is that a good idea? Thanks!
-
Ah, thanks.
-
I have a drive that is all zeroes but does not have the signature. Can I use this plugin to read the drive, verify that it is all zeroes, and then write the signature? I don't see that in the options. All the options either write zeroes or read the signature. I have zeroes but I don't have the signature. I could of course just write all new zeroes but I imagine reading is less wear. Thanks!
-
I read https://docs.unraid.net/legacy/FAQ/shrink-array/ and followed the link for step 8 "Run the clear an array drive script" that took me to the comment that has a download link for the "clear_array_drive" script. I tried running it but got an error. ``` Found a marked and empty drive to clear: Disk 3 ( /mnt/disk3 ) + echo -e '* Disk 3 will be unmounted first.' * Disk 3 will be unmounted first. + echo '* Then zeroes will be written to the entire drive.' * Then zeroes will be written to the entire drive. + echo '* Parity will be preserved throughout.' * Parity will be preserved throughout. + echo '* Clearing while updating Parity takes a VERY long time!' * Clearing while updating Parity takes a VERY long time! + echo '* The progress of the clearing will not be visible until it'\''s done!' * The progress of the clearing will not be visible until it's done! + echo '* When complete, Disk 3 will be ready for removal from array.' * When complete, Disk 3 will be ready for removal from array. + echo -e '* Commands to be executed:\n***** \x1b[36;01m umount /mnt/disk3 \x1b[39;49;00m\n***** \x1b[36;01m dd bs=1M if=/dev/zero of=/dev/md3 \x1b[39;49;00m\n' * Commands to be executed: ***** umount /mnt/disk3 ***** dd bs=1M if=/dev/zero of=/dev/md3 + '[' clear_array_drive == /tmp/user.scripts/ ']' + echo -n 'Press ! to proceed. Any other key aborts, with no changes made. ' Press ! to proceed. Any other key aborts, with no changes made. + ch= + read -n 1 ch !+ echo -e -n '\r \r' + '[' '!' '!=' '!' ']' + logger -tclear_array_drive 'Clear an unRAID array data drive v1.4' + echo -e '\rUnmounting Disk 3 ...' Unmounting Disk 3 ... + logger -tclear_array_drive 'Unmounting Disk 3 (command: umount /mnt/disk3 ) ...' + umount /mnt/disk3 + echo -e 'Clearing Disk 3 ...' Clearing Disk 3 ... + logger -tclear_array_drive 'Clearing Disk 3 (command: dd bs=1M if=/dev/zero of=/dev/md3 ) ...' + dd bs=1M if=/dev/zero of=/dev/md3 dd: error writing '/dev/md3': No space left on device 9+0 records in 8+0 records out 8388608 bytes (8.4 MB, 8.0 MiB) copied, 0.00256501 s, 3.3 GB/s + logger -tclear_array_drive 'Clearing Disk 3 is complete' + echo -e '\nA message saying "error writing ... no space left" is expected, NOT an error.\n' A message saying "error writing ... no space left" is expected, NOT an error. + echo -e 'Unless errors appeared, the drive is now cleared!' Unless errors appeared, the drive is now cleared! + echo -e 'Because the drive is now unmountable, the array should be stopped,' Because the drive is now unmountable, the array should be stopped, + echo -e 'and the drive removed (or reformatted).' and the drive removed (or reformatted). + exit ``` I ran the script with `sh -x` so there's debug output. I see it uses `/dev/mdX` not `/dev/mdXp1`. Is that the issue? Are people using this script? Do I have an old version of the script? Here's the download link for the script from the comment by RobJ https://s3-us-west-2.amazonaws.com/upload.forums.unraid.net/live/monthly_2016_09/clear_an_array_drive_zip.80cc67c667b13547f490de09b702bf4b I also searched this topic for "of=/dev/md" and I didn't see any references that included the "p1".
-
@Frank1940 1. A refurbished drive is heavily used but not failed. I think... I don't know. I imagine that it would be easier for a data center to rotate all their drives before eol rather than wait until they individually fail. I don't actually know where they come from. Where do refurbished drives come from? 2. I imagine the seller checks the smart report to see that it doesn't have any reallocated sectors. I don't actually know what they do. 3. The two sellers that I see talked about most are GoHardDrive and ServerPartDeals. I think they have reputation around respecting the warranty. Idk if they have any rep around screening and testing. 4. 5 year warranty. Only for "Reallocated sector count" or "UDMA CRC error count" in the case of SPD. "Any issues with the drive" in the case of GoHD. The drive that failed badblocks is a drive that I bought new that is now out of warranty. I ran badblocks on it because I was curious what would happen.
-
It's true; I do not understand how hard drives work. It's very confusing. Badblocks does four passes over the drive writing a pattern and reading it back on each pass. I have a drive that had no errors for the first pass writing and reading 0xaa but failed halfway through the second pass writing and reading 0x55. That makes me suspicious that a preclear is not enough.
-
I recently bought some refurbished drives and I wanted to run `badblocks -wsv -b 4096 /dev/disk/by-id/whatever-abc` but I ran it on an array drive on accident. I kicked off badblocks, started a dozen docker services, changed over to the unraid main tab and that's when I saw that I had just run badblocks on the wrong drive. I took the array offline, unassigned the drive, started the array without the drive, and ran `xfs_repair` on the emulated drive. In case you're curious `xfs_repair` seems to have fixed it. ``` bad primary superblock - bad magic number !!! attempting to find secondary superblock... .found candidate secondary superblock... verified secondary superblock... writing modified primary superblock ``` Anyways, does anyone have a safer way to run badblocks? Maybe a script that objects if the drive is in the array or something? The closest I found in the forums was this saying that it's not going to happen in UD. Thanks! Backup you data, haha!
-
There's a lot of stuff in the diagnostics. I haven't used that feature before and I want to review it more thoroughly before I upload it. Thank you for your support! I was really sweating it but I'm confident now that I have not lost any data. I have an offline copy of my important files and I'm waiting on parts to add some drives to build a raidz-2 as a destination for online backups. I'm going to take advantage of snapshots. I'm also running badblocks -wsv on all my drives to build confidence in the drives that I have. I added some refurb drives to my array in haste and now I can take my time rotate those out of the array so that I can do a destructive run of badblocks on each. I'm also adding two new wd red pro as parity because they recently had a "sale" on the 14tb. I don't want too many refurbs.
-
Thank you. I added two 8TB drives and rebuilt the array in maintenance mode without issue. Then I did parity swap to move an 8TB CMR from parity to the array to replace an 8TB SMR array drive and a new 12TB CMR took its place in parity. Then I replaced an 8TB parity SMR with a new 12TB CMR and I'm waiting for that to finish. I'll run xfs_repair through the gui when that's done. Thanks for mentioning it; I didn't know about that feature. Sorry for not posting diagnostics. I've seen that in other troubleshooting threads but I didn't think it mattered for my question. I'll try to remember to do that by default in the future. I'm not posting it now because I didn't downloaded the diagnostics when I first posted and I have rebooted and changed drives since then. I'm happy to post diagnostics if I still need to. Here's the SMART from the drive that unRAID disabled: | # | ATTRIBUTE NAME | FLAG | VALUE | WORST | THRESHOLD | TYPE | UPDATED | FAILED | RAW VALUE | | 1 | Raw read error rate | 0x000f | 068 | 064 | 006 | Pre-fail | Always | Never | 71094922 | | 3 | Spin up time | 0x0003 | 092 | 092 | 000 | Pre-fail | Always | Never | 0 | | 4 | Start stop count | 0x0032 | 099 | 099 | 020 | Old age | Always | Never | 1331 | | 5 | Reallocated sector count | 0x0033 | 100 | 100 | 010 | Pre-fail | Always | Never | 8 | | 7 | Seek error rate | 0x000f | 090 | 061 | 045 | Pre-fail | Always | Never | 992855040 | | 9 | Power on hours | 0x0032 | 059 | 059 | 000 | Old age | Always | Never | 36679h+06m+49.125s | | 10 | Spin retry count | 0x0013 | 100 | 100 | 097 | Pre-fail | Always | Never | 0 | | 12 | Power cycle count | 0x0032 | 100 | 100 | 020 | Old age | Always | Never | 449 | | 183 | Runtime bad block | 0x0032 | 100 | 100 | 000 | Old age | Always | Never | 0 | | 184 | End-to-end error | 0x0032 | 100 | 100 | 099 | Old age | Always | Never | 0 | | 187 | Reported uncorrect | 0x0032 | 093 | 093 | 000 | Old age | Always | Never | 7 | | 188 | Command timeout | 0x0032 | 100 | 098 | 000 | Old age | Always | Never | 1 1 6 | | 189 | High fly writes | 0x003a | 100 | 100 | 000 | Old age | Always | Never | 0 | | 190 | Airflow temperature cel | 0x0022 | 064 | 048 | 040 | Old age | Always | Never | 36 (min/max 35/36) | | 191 | G-sense error rate | 0x0032 | 100 | 100 | 000 | Old age | Always | Never | 0 | | 192 | Power-off retract count | 0x0032 | 100 | 100 | 000 | Old age | Always | Never | 339 | | 193 | Load cycle count | 0x0032 | 082 | 082 | 000 | Old age | Always | Never | 37333 | | 194 | Temperature celsius | 0x0022 | 036 | 052 | 000 | Old age | Always | Never | 36 (0 20 0 0 0) | | 195 | Hardware ECC recovered | 0x001a | 079 | 064 | 000 | Old age | Always | Never | 71094922 | | 197 | Current pending sector | 0x0012 | 100 | 100 | 000 | Old age | Always | Never | 24 | | 198 | Offline uncorrectable | 0x0010 | 100 | 100 | 000 | Old age | Offline | Never | 24 | | 199 | UDMA CRC error count | 0x003e | 200 | 200 | 000 | Old age | Always | Never | 0 | | 240 | Head flying hours | 0x0000 | 100 | 253 | 000 | Old age | Offline | Never | 22351h+58m+29.819s | | 241 | Total lbas written | 0x0000 | 100 | 253 | 000 | Old age | Offline | Never | 68659349241 | | 242 | Total lbas read | 0x0000 | 100 | 253 | 000 | Old age | Offline | Never | 1595474125720 | Can you share good resources on understanding fields like "offline uncorrectable"? The best I have found is https://helpful.knobs-dials.com/index.php/Computer_data_storage_-_Reading_SMART_reports.
-
Wow, ok. I found the button that says "Sync will start Data-Rebuild." Never mind...
-
I can't actually see the names of the screenshot files. Oh well. It's probably doesn't matter.
-
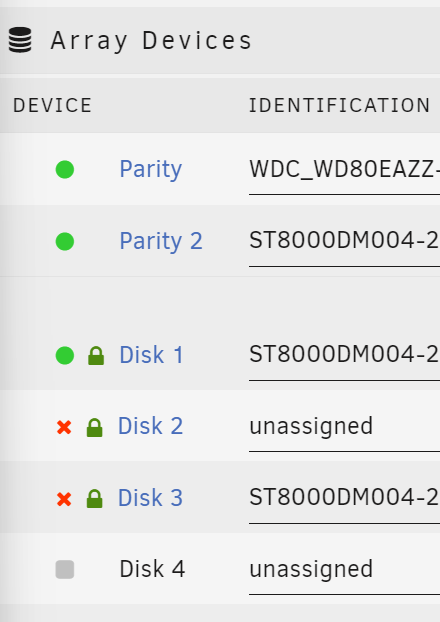
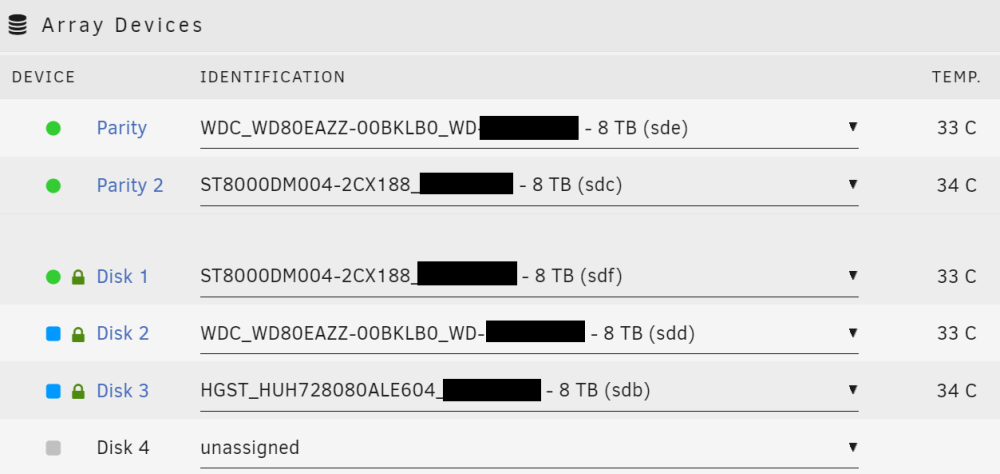
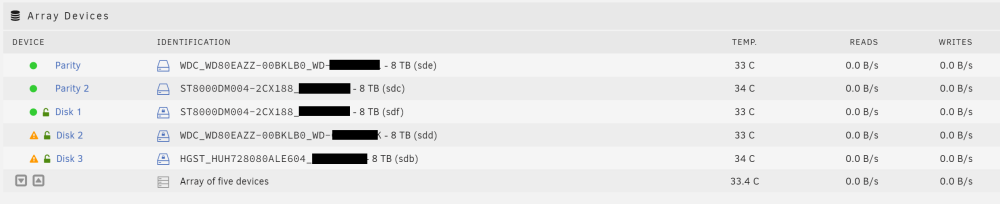
I have two 8tb drives and I'm trying to rebuild the array but I'm having trouble. I added the two drives to the array and I attached a screenshot of what it looks like after adding them (one.png). There's the two blue boxes next to each new drive. At the bottom it says "Stopped. Replacement disk installed." and "Start will start Parity-Sync and/or Data-Rebuild." I checked the box for "Maintenance mode" and clicked START. I attached a screenshot of what that looks like (two.png). I think something is wrong because the values for READS and WRITES are all 0.0B/s. I expect to see drive activity. I expect to see reads on Parity, Parity 2, and Disk 1 and writes on Disk 2 and Disk 3. I attached a screenshot (three.png). Thanks!

-
Right, right. Perfect, thanks! I got confused. Yea, that’s what I want.
-
Sorry; I do only have one 8TB but I'm happy to wait until I have two 8TB if that's a better option. I think it's a better option to rebuild with two 8TB at once because that's less wear on the old SMR Seagate drives. I'm planning to run badblocks -wsv on the new 8TB when I get it before I put it in the array. I'm elated to hear that I'll be able to rebuild both disks at once. I didn't know that was an option. This sounds like the best path forward. Is there an option for unraid to disallow writing to the array during the rebuild? I have disabled docker and commented out any cron jobs but I want to take all available precautions. I'm asking this in advance in case I have an issue during rebuild: Can I ddrescue a "failed" parity/array drive to a new drive and then insert that new drive in place of the "failed" parity/array drive and ask unraid to use the new drive and trust parity? Like, can I do an Indiana Jones swap of a drive? Thank you!
-
I like the idea of adding a healthy 8TB in place of the missing drive and rebuilding the array but I'm nervous about another drive failing during either that rebuild or the subsequent rebuild. Can/should I add two healthy 8TB at once and rebuild the array to eliminate a subsequent rebuild and minimize wear on the old SMR Seagate drives? Does it even work like that? After replacing the missing 8TB disk, can I do the parity swap to install the 12TB parity without swapping that Seagate SMR drive into the array as a data drive? I want to remove all the old SMR drives and I don't trust that I can write to them without having them fail. I found conflicting comments on the internet about whether or not I could use a data drive bigger than parity. Thanks for clarifying that. Thank you for your help!
-
Hey, I have an unraid array with 5 disks: Parity - new 8TB CMR Western Digital Parity 2 - old 8TB SMR Seagate Barracuda Disk 1 - old 8TB SMR Seagate Barracuda Disk 2 - 8TB unassigned (device missing, contents emulated) Disk 3 - old 8TB SMR Seagate Barracuda (device disabled, contents emulated) I have 2 parity and I'm down 2 drives. I don't have Disk 2 and can't put it back in. I want to replace the old Seagate SMR drives and rebuild the array. I have a healthy 8TB and a healthy 12TB; I also ordered another 8TB and another 12TB. No, I don't have a backup. Yes, I will enthusiastically back things up after this. Thank you so much for helping. What should I do? Things I'm considering: A) In the unraid gui: Replace Disk 1 and Disk 2 with new drives and rebuild. Replace Parity 2 with new drive and rebuild. B) Outside of unraid: `dd` or `ddrescue` Parity 2 to a new drive and repeat for Disk 1 and then use unraid gui to replace Disk 2 and Disk 3 and rebuild array? Something else? Also, can I replace the 8TB Disk 2 or 8TB Disk 3 with a 12TB drive? Also, can I replace the 8TB Parity 2 with a 12TB drive? I read about "Parity Swap" where unraid will copy parity onto a bigger drive and move the old smaller parity drive into the array. I'm not sure that's what I want. If I did this for Parity 2 I wouldn't want it in the array. Also, the instructions for it seemed tricky/finicky. I just realized that I'm implying something but haven't communicated it. Namely, I'm concerned about the remaining two old Seagate SMR drives failing. I just read about SMR and all that funny business. I don't want to write to any of the old Seagate SMR drives; I think I shouldn't need to do anything more than a single simple read from the old drive to clone to a new drive. Thanks a million. I'm sweating.