




bebis
Members
-
Joined
-
Last visited
Everything posted by bebis
-
So... at least one of those has got to be hanging on by a thread. I ended up not being able to get it to mount again in r/w, but by doing the following: Disabled the automatic mounting of disks Forcing a restart Running the following: zpool import -F -f -o readonly=on poolname Then starting the array The pool mounts almost immediately since it didn't have to deal with the ZIL, but unraid gui shows an issue with the filesystem that you can safely ignore. Then I was able to copy the data over to my array using rsync with the archival flag and used a terminal session to manually create the share folder on the array so I could just switch the destination for the mover. Now I'm going to take a break from this and then hook up the spare HBA to my desktop and test the disks.
-
I am at my wits end with my raidz2 array. I have 6x8TB hdds attached to a SUPERMICRO SAS825TQ backplane which is connected to my lsi 9500-8i. I originally had no issues with it, then the side table that the 3d printed enclosure was sitting on took the drives right into the concrete. Hard drives don’t like that so I lost 4 out of my 8 drives, I replaced 2 of the lost ones and recreated a raidz2 array out of the 6 remaining drives. Now a week or so later I have issues with applications going unresponsive from getting seemingly locked up with disk io that takes minutes to happen at times. When this happens I am eventually forced to shut the machine down and bring it back up since processes won’t stop since they are waiting on disk io. When it turns back on I end up stuck in the “mounting” step with hundreds of messages in /proc/spl/kstat/zfs/dbmsg I don't get any errors at all in the WebGui and the drives show read activity, but just a few hundred KiB/s. The entire system just stays stuck like that for hours until the zfs pool eventually mounts, typically between 6-12 hours. I don't know how to begin to figure out what the issue is. I have attached the full output of /proc/spl/kstat/zfs/dbmsg Lines like this seem the most concerning to me, but I see errors for sdm and sdl and I just replaced the sdm drive… not sure if these are actual issues or just caused by some other source of latency since requesting smart data from the drive gives me a very normal response. 1752608776 ffff888114bad3c0 zio.c:2302:zio_deadman_impl(): slow zio[10]: zio=ffff8885808da140 timestamp=10191871982502 delta=26961250 queued=0 io=0 path=/dev/sdl1 last=10191888020255 type=2 priority=3 flags=0x700080 stage=0x400000 pipeline=0x4e00000 pipeline-trace=0xa00001 objset=0 object=79 level=0 blkid=2547347 offset=5137725710336 size=4096 error=0 What I have tried hardware wise: Swapped out the lsi9500 for a lsi9207, same issue By doing the above I also swapped all the cables to the backplane I also swapped out the backplane Saw those errors about sdm so after all of the above I swapped that out for one of my spare refurbs. dbmsg output.txt
-
I mean I imagined the proposed "dev/beta" license would have restrictions like only supporting the latest version for x days and the prior version for x days to cover the limited time period that updates would need to be tested ( although that sounds like a PITA to implement ). As someone else mentioned running an unlicensed copy in a VM on trial could be a solution, it would just require a bit of extra work on my end to refresh the trial license to test the updates. I have never used the trial license before, but thought that there was a hard limit imposed by the flash uuid so that may prove to be an unsolvable issue. I am in no way expecting an additional pro license, that is asinine and was not my intended request. The Unraid team has been kicking out killer updates faster and faster. I work in software dev so I understand how much of a monumental effort it is to test this software against the slew of possible configurations. The more people that are testing the RCs, the better. I haven't been able to do so.
-
Being granted a test license to use for a dev env and beta testing would be sweet. I have extra hardware I could run with syncthing to duplicate my main configuration and use for testing. I've wanted to do that but with the cost of an additional pro license I couldn't swing it. I run far too many services friends and family rely on to update early or test RCs.
-
I found this thread on the archwiki. I'll take a look and see if this solves my issue https://wiki.archlinux.org/title/Ryzen#Random_reboots Edit: I applied a +5 curve offset to pump more voltage into the cpu, +1 above what the arch wiki recommended. Hopefully that does the trick. Will report back if I continue to crash. Also based on other mcelog outputs that I have seen either the one I am getting has nothing to do with RAM or it just is not outputting properly since my cpu is not properly recognized. I have seen some outputs from other peoples' memory errors and they contain much more detail. Mine almost exactly matches the one in the arch wiki.
-
I think it is a memory error? But I don't know how to determine which stick is throwing the error. If I can figure that out then I could remove the bad stick and see if I am still crashing I ran the error through mcelog and got this. not sure how to interpret it though root@unraid:~# /usr/sbin/mcelog --ascii < error_text Hardware event. This is not a software error. CPU 15 BANK 5 MISC d012000100000000 ADDR 1479c98cf6ce STATUS bea0000000000108 MCGSTATUS 0 SYND 4d000000 IPID 500b000000000 mcelog: Unknown CPU type vendor 2 family 25 model 1 unraid-diagnostics-20250130-1322.zip
-
Just had another crash with an mce error logged. how do I actually debug this? Jan 30 11:16:41 unraid kernel: mce: [Hardware Error]: Machine check events logged Jan 30 11:16:41 unraid kernel: mce: [Hardware Error]: CPU 15: Machine Check: 0 Bank 5: bea0000000000108 Jan 30 11:16:41 unraid kernel: mce: [Hardware Error]: TSC 0 ADDR 1479c98cf6ce MISC d012000100000000 SYND 4d000000 IPID 500b000000000 Jan 30 11:16:41 unraid kernel: mce: [Hardware Error]: PROCESSOR 2:a20f10 TIME 1738253773 SOCKET 0 APIC f microcode a20102d
-
When you say a single MCE, you mean you received that mcelog error once after a crash/hang and then never saw it again? Or do you mean you received the mcelog error once with no crashes? Trying to figure out if the MCE log error is due to the crash or not since I swear I don't see it otherwise.
-
The issue was previously hanging. After swapping the motherboard and power supply I now have the restarting issue. I can't seem to tie the restarts to a time or process. They seem to happen during times of low load which is usually the middle of the night so I'm not sure if it hangs and eventually reboots or just immediately reboots
-
Alright, I have now swapped out the motherboard and the PSU. I also ran a memtest for 24 hours with no errors. I am still seeing random reboots happening though I have attached diagnostics, I have been noticing this error: Jan 28 15:49:21 unraid root: mcelog: ERROR: AMD Processor family 25: mcelog does not support this processor. Please use the edac_mce_amd module instead. I tried looking around on the forums and the general consensus seemed to be to ignore it... but I feel like this may be a clue. Not sure though. Also attached the latest logs. The crash happened between syslog-previous and syslog. Unfortunately I don't think anything there will be too helpful this is starting to drive me crazy, is it just a ryzen issue with unraid? unraid-diagnostics-20250128-1806.zip
-
I unfortunately don't have the luxury of running it with containers disabled as a number of people rely on the services and I also will lose control of all the lighting in my house. I'll try swapping out the motherboard next. I have another set of memory to try as well. Waiting on the board to come in the mail now. Is there a way to rule out a cpu issue? At this point hardware wise I ruled out the power supply since the system stays up and hangs when there is an issue. I ruled out any of the drives and their connections since that was untouched. The only pieces left are the memory, motherboard, and cpu.
-
I had another crash. This one had the server lasting much longer (~24 hrs) , but still was left hanging with no display out and not logging anything to syslog. The system becomes unresponsive to keyboard inputs, has a blank display out, and the webgui doesn't load. syslog
-
Thank you for the help, I have that enabled now. I have not had a crash since updating to Unraid 7. Hopefully the newer kernel fix my issue. If I have another crash now I'll post the syslog.
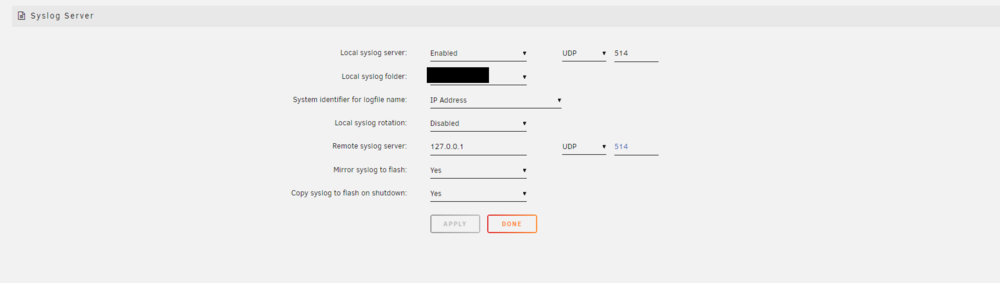
-
I had the syslog server enabled, but as of right now the latest syslog previous was a clean reboot after installing unraid 7. I did not realize that the syslogs containing my crashes would not persist. Is there a way to avoid removing old syslogs from my flash?
-
Earlier today I also brought my motherboard bios current from an older bios from 2022 and made sure all my settings from before persisted for the c-states and such. Experienced another hang and forced reboot that required me to replace the bzfirmware file on the flashdrive to boot properly again. Just updated to unraid 7. I'll see if that resolves anything but I don't have my hopes up.
-
I recently switched my motherboard, cpu, and ram from an x99 system to a 5800x on a X570 AORUS ELITE. The new cpu, board, and ram was previously in my gaming pc and worked fine with no crashes running windows 11. At first everything seemed fine but then I noticed it was offline. I looked at the display out from the server and it was just hanging with no disk usage that I could see/hear. After power cycling it would hang at a hash check for one of the bz files on the flashdrive. Restoring from a flash backup temporarily fixed the issue but after a few hours the same thing would repeat. I found a few other threads discussing crashes with Ryzen so I made the following changes with no success: - Disabled XMP in bios - Disabled global c-states in bios - Set power supply idle current to typical in bios - Added "/usr/local/sbin/zenstates --c6-disable" to /boot/config/go - Enabled syslog writing to flash but observed no errors prior to the system hanging I'm at my wits end, I get no errors, this hardware worked fine before, and I don't know what to do next. unraid-diagnostics-20250109-2047.zip

