





snowboardjoe
Members
-
Joined
-
Last visited
Everything posted by snowboardjoe
-
I looked more into this today, but still unable to get it running again. The docker.log reports: time="2019-04-15T13:58:23-05:00" level=info msg="shim reaped" id=79a57e2ec068e23e5876a15802ec53bca5e21b02ecb518862be57b1d734a32aa time="2019-04-15T13:58:23.298963594-05:00" level=info msg="ignoring event" module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete" time="2019-04-15T13:58:23.316022846-05:00" level=warning msg="Failed to delete conntrack state for 172.17.0.13: invalid argument" time="2019-04-15T13:58:24-05:00" level=info msg="shim docker-containerd-shim started" address="/containerd-shim/moby/79a57e2ec068e23e5876a15802ec53bca5e21b02ecb518862be57b1d734a32aa/shim.sock" debug=false pid=27205 The log for the container itself is empty. Not sure what else to look at. Installed deludge and that's running, but would like to go back to Transmission if possible.
-
This docker is no longer working for me. Unable to debug it too. It keeps going through the process of grabbing all of the OPVN files from NordVPN and running that through sed to format all of them. It dies after a few minutes and restart all over again. Any suggestions to figure out what is happening here, or has this been abandoned?
-
The secure connection setting only applies to attaching to the local client running on your unRAID host. Has it ever completed a backup? Does CP on the server end show it's getting a connection?
-
Keep in mind this is not an unRAID problem. This is a bug with Crucial and they have not resolved it yet. This error is reported by multiple platforms and not limited to just unRAID. I'm actually considering abandoning these devices and going with Samsung. In the meantime, disabling attribute 197 works around the problem and silences the false positives. You still have attributes being watched to keep track of reallocated sectors (you're not totally blind to a drive going bad).
-
Not sure what would cause that. Maybe delete the app and try again? Maybe a typo in the URL?
-
In general, write performance is not fantastic. Data transfer speeds still depend on your configuration (share configuration, using cache, speed of cache, etc.) and there is database activity to process each file (lots of tiny files will result in more overhead vs. a few large files). I haven't measured the performance overall of writing to my NC app, but it's definitely slower compared to simply copying the data from my local system to a share over the network (also 1Gb network here).
-
Deleting the container alone does not modify the contents of /mnt/user/appdata/mariadb. It only removes the images from docker.img. Most containers when reinstalled will either create new configuration files if they are not present. If you manually manipulated the data in /mnt/user/appdata/mariadb, then all bets are off depending on what you modified. If you want to destroy what's there, you would remove all contents within /mnt/user/appdata/mariadb while the container is stopped. There is no need to remove and add the container back. As for Nextcloud, the config should be located in /mnt/user/appdata/nextcloud. Where you place your data is up to you and you define that in the container configuration. For example, in my case, all of my data is located in /mnt/user/nextcloud which maps to /data within the container when it's running (referenced as Host Path 2 in my configuration).
-
Yep! That's how it works. You can even install a CP client on another system and restore that way too once you're logged into it with your account. Web is super easy, so multiple options available.
-
I doubt he's getting that error anymore since he's able to retrieve good data from all of his drives again. That script should expect to see all of that data and just served as an indicator to a deeper problem that he fixed.
-
Yeah, because some things changes with the path, the plugin will have you set that back up again as the mapping has been lost (there was a discussion about this earlier in this same thread). Glad you found the problem and happy to help. Go get some sleep!
-
How did you "jack" with your MariaDB container? Did you modify your /mnt/user/appdata/mariadb structure? Your configuration for Nextcloud and your data should already be in two different filesystems and/or directories. So, your data should remain untouched. If I were to start over and no other application is storing data in MariaDB): Stop Nextcloud Stop MariaDB Destroy all configuration and data for MariaDB. Destory all configuration for NextCloud. Start MariaDB and let it initialize. Start Nextcloud and let it initialize. Restore and custom configurations to Nextcloud (save a copy of your config.php?). Setup Nextcloud and point to your existing data and run a scan of what's there. I've borked my Nextcloud before when I was setting things up by losing the admin password. I was able to modify the DB to get that back and get back on track again without needed to restore anything.
-
Beware that's a different configuration for the cache pool. In that screenshot, the cache devices are in concatenated--not mirrored. I don't know how that effects the results, though, it at all. That could also be an older version of unRAID there. I would click on that disk from the main screen and check to make sure all SMART attributes are present and compare to other drives. Start with temperature data. If you're not getting a value there, then something is wrong. We should probably take this over to another thread too and not hijack the Disk Location plugin thread.
-
The data for both drives should always be present: Should run some SMART tests on that one drive. Could be a power cycle makes it right again too.

-
Not as expected, but not in a bad way. It appears the data from the disk is linked to the slot. What that data no longer exists, it goes away. The new data comes up and needs to be assigned to the slots. This is likely how it was intended and makes sense.
-
Your second cache drive is not in a normal state. The biggest indicator from your main unRAID screen is lack of temperature information (that should only be blank when a disk is spun down). I would investigate that problem further and verify the second cache disk is fully functioning. Because of the missing information, the plugin is going to fail for that disk.
-
Nice plugin! Was just looking for something like this. The best feature is the locate function. Was able to identify everything quickly. I will be replacing my cache drives tomorrow. I assume as long as nothing else changes, it will reflect the data in those slots. Just what I needed.
-
It should not make any difference in how it operates with the cache setting. It should be set to Only for performance though and allow the other disk(s) storing data to spin down. Worst case, the application would be sluggish or pause waiting on a data drive to spin up and provide the data it needs.
-
What command are you running? It should look something like this: sudo -u abc php /config/www/nextcloud/occ files:scan --all
-
Go to unRAID dashboard. Go to Docker. Select CrashPlanPRO. Scroll to bottom and expand "Show more settings...". Locate Maximum Memory setting (the default is 1024M). If you've got plenty of RAM to spare, I would bump up to 2048M. Click Apply at bottom and container will be restarted with new settings.
-
The amount of RAM allocated to that docker is not enough for what the application needs. Change the Maximum Memory setting in the docker config for CrashPlan provided you have enough free RAM for it (but keep it reasonable as you can always increase it later as needed).
-
Well, son of a b..., there it is. I had no idea that was an area that scrolls. Feel like an idiot too. Thanks!
-
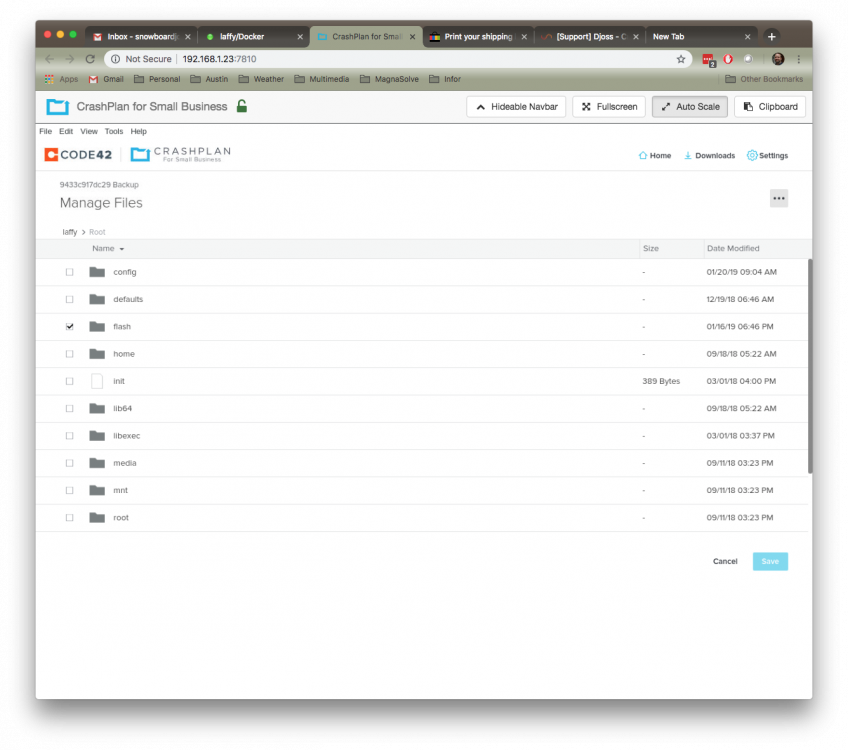
Attached here. I've also opened a support request with Code42. The flash is present, but my storage directory is not present (yet, it is backed up nightly without any issue and verified). Very strange to see this inconsistency. Can't add/remove/modify backups of any share right now.
-
I haven't looked at my CP config in awhile (nothing has changed in structure in ages). Was just doing some verification today and noticed I can't manage my media files anymore. CP still shows I have 13TB backed up which is on the low side. All I see are the local configuration files and the flash drive. Container config shows /shares is mapped to /mnt/user. However, there is no /shares directory from the WebUI. Not sure how long it's been in this state. I logged into console and I see my mappings there, but not in the WebUI. Suggestions on where to look on why my mappings aren't showing up in the WebUI? Just seems like an incomplete list and does not match what I see from console (some system items are there, but random). EDIT: Did some more checking. Clicked on Restore and I see up to date information there including all of my media files (last updated last night). So, this is really weird why I can't manage this from the WebUI to add and remove things.
-
Ahh, sounds like the environment is not getting passed and/or paths not getting setup. Try using the console connection for the container.
-
I've not run into this problem. I get incoming connections from peers just fine. At the same time, I've also verified all traffic is being tunneled through NordVPN (they only see my VPN IP). Due to the nature of how these programs work, how else would you store them? The applications must know what the passwords are to submit the services you're subscribed to. If you encrypt it, the application has no method to extract it to submit the credential to the service on every startup of the container. Best thing to do is to make sure such files are only readable for the application that needs it.




