




sonofdbn
Members
-
Joined
-
Last visited
Everything posted by sonofdbn
-
I have the same problem of deleted files not showing up in the Recycle Bin with the 02/10 update. Might have happened with recent versions, but only noticed it now. Had been working fine, although unfortunately I don't know what the last working version was.
-
OK, after a bit of reading and thinking, which I should probably have done first, things are more complicated than I thought. I thought that transcoding was just transcoding, but it seems that transcoding 4K is much more demanding. Having seen all the dire warnings about NOT transcoding 4K, I'd still like to be able to do it. I had thought there was no problem, as family members watched various things with no complaints, but it turns out that they were watching mainly DVD rips and maybe occasionally 1080p files on devices like Amazon tablets, and possibly rarely (never?) watching 4K media. I had previously tried watching 4K media on a lower-res device and there was terrible stuttering, which I had attributed to a) the device and b) bad wi-fi. Anyway, while there are recommendations to avoid the problems of 4K transcoding by keeping lower-res versions, I don't particularly want to spend time re-encoding files and managing different versions. So hardware-wise, what's needed to transcode 4K movies? There's a lot of different and conflicting information out there, and some of it is not very recent, so I don't know if the technology is more capable now. Even pointers to reliable sources would be very helpful.
-
Thanks for the replies. I'll keep this information in mind when I decide on the next build.
-
I'm considering my next unRAID server. On my current unRAID I have a Xeon D-1541 (doesn't have Quick Sync), no GPU and run Plex. I don't think I have more than 2-3 Plex streams that need transcoding simultaneously and there don't seem to have been any problems. I'm wondering whether I need to get an Intel CPU with Quick Sync for the next server for future-proofing (I'm very unlikely to be increasing the number of Plex streams). I think the other option for transcoding is to get a graphics card, but I don't think the expense is warranted. The reason I don't just go with Intel is that I have a slightly sentimental and illogical desire to try AMD for the next server. I'm looking only at "normal" PC parts, no server-level CPUs - no Xeon, no Threadripper. For the AMD CPU I'd be looking at something in the current generation with lots of cores. So is Quick Sync necessary for transcoding just a few streams?
-
Thanks so much! Got Nextcloud working again. What I did after reading the Swag support thread and after stopping Swag: 1. Went to my Swag folder in /mnt/appdata 2. Went to the nginx sub-folder 3. Renamed ssl.conf to ssl.conf.old and nginx.conf to nginx.conf.old (in case something went wrong) 4. Made a copy of ssl.conf.sample and named the new file ssl.conf 5. Made a copy of nginx.conf.sample and named the new file nginx.conf. 6. Restarted Swag. NOTE: I didn't have any customisations in the ssl.conf and nginx.conf files. (I can't claim any credit for this - all taken from the Swag support thread)
-
OK, thanks for that info @dius. Now, I'm very hazy about exactly what it does, but I use Swag (previously Letsencrypt) in conjunction with Nextcloud. The Swag logs seem to be constantly writing this line: nginx: [emerg] "stream" directive is not allowed here in /etc/nginx/conf.d/stream.conf:3 Maybe that points to something that's relevant to the problem.
-
@dius I'm having the same problem. Nextcloud was working fine, today after updating recently my Windows client can't access Nextcloud (which I access via a domain). No errors that I could see in the log but there were these lines: **** The following active confs have different version dates than the samples that are shipped. **** **** This may be due to user customization or an update to the samples. **** **** You should compare the following files to the samples in the same folder and update them. **** **** Use the link at the top of the file to view the changelog. **** /config/nginx/nginx.conf /config/nginx/site-confs/default.conf cont-init: info: /etc/cont-init.d/85-version-checks exited 0 I don't know much about nginx but I think it's the application that allows the accessing via the domain. So maybe there's a problem here?
-
Thanks for the quick reply. I run my server on a UPS because of occasional lightning power outages, and it's worked well. But over the last few months I've had unclean shutdowns. At first I thought it might be lack of battery capacity, but after shutting down the server (cleanly I thought) and then restarting after a holiday, I got the unclean shutdown message. Today there was a power outage and the UPS kicked in and should have shut down the server cleanly, but again on restarting I got the unclean shutdown message and the parity check started. I'm on UNRAID 6.9.2, and there's usually one VM running and a few dockers. There's one unassigned device. I've attached the diagnostics file generated at the time of the shutdown. Hope someone can give some suggestions about how to fix the unclean shutdowns. tower-diagnostics-20221216-1714.zip
-
Normally if I need to create a diagnostics zip file, I can go to Tools in the GUI and there's an option box to "Anonymise diagnostics". But in the case of an unclean shutdown, the file gets created automatically, so there's no option to anonymise. Should it be anonymised, and if so, how? Or is there a folder from the zip file that could be uploaded to the forum safely (e.g., just the logs folder)?
-
I think space was indeed the problem. My Disk 1 was very full, so I deleted some stuff. Didn't touch Nextcloud, but next time I looked, everything was working. Thanks very much for the help.
-
Thanks for the suggestions. I checked, but everything looks OK. (Sure, some storage said 100% use, but it was a rounding issue - when you have an 8TB disk you can still have 34GB free even though usage is 100% allowing for overhead). But I was encouraged to check further, and wonder if it's not a permissions problem. Using WinSCP (I'm not a Linux person) I was that the owner of the folders in my Nextcloud data was "nobody" - seems quite common and expected, so no issues there. But the rights of the folders vary: either A) rwxr-xrwx (0757) or B) rwxr-x--- (0750). These are the folders on Unraid that are synced with folders on my Windows PC. Don't know why they would be different, and, if one is "better" than another. Or are these different permissions expected? I seem to have inconsistent results when I test the syncing. I thought at first that new files were not syncing to 0750 folders, but were syncing to 0757 folders, but this seems not to be the case. But it's getting late here; I'll test a bit more tomorrow.
-
My Nextcloud (24.0.4.1) container has been running fine for a while, but just recently it's been unable to sync new PC files to the server. This happened when I copied a couple of small files (2MB-4MB) to a synced folder on my Win 10 PC. The new files are not being synced (I get the small red x icon in the lower left of the file icon). In the error logs, I get continuous messages like this: 2022/08/19 15:01:05 [error] 183#183: *825 FastCGI sent in stderr: "PHP message: PHP Notice: fwrite(): write of 1798 bytes failed with errno=28 No space left on device in /config/www/nextcloud/lib/private/Log/File.php on line 89" while reading response header from upstream, client: 172.18.0.3, server: _, request: "GET /index.php/css/user_status/62ab-0e7b-user-status-menu.css?v=41545bc493ea402b7a9b19b640ab406b-6b0fbc6d-2 HTTP/1.1", upstream: "fastcgi://127.0.0.1:9000", host: "the hostname I use" The line 89 mentioned above reads: fwrite($handle, $entry."\n"); Here's that line 89 in context in this extract from File.php (8th line down): public function write(string $app, $message, int $level) { $entry = $this->logDetailsAsJSON($app, $message, $level); $handle = @fopen($this->logFile, 'a'); if ($this->logFileMode > 0 && is_file($this->logFile) && (fileperms($this->logFile) & 0777) != $this->logFileMode) { @chmod($this->logFile, $this->logFileMode); } if ($handle) { fwrite($handle, $entry."\n"); fclose($handle); } else { // Fall back to error_log error_log($entry); } if (php_sapi_name() === 'cli-server') { if (!\is_string($message)) { $message = json_encode($message); } error_log($message, 4); } } I have no experience in this, so please bear with me. From the error message it seems that something has run out of space, but I have no idea where. My Unraid dashboard Memory section tells me that only 65% of the docker image is used and Log is showing only 1%. My array has plenty of free space, cache disk (where the container appdata sits) has 50GB free space. Googling hasn't produced anything that seems to help/work. I really don't think I changed anything - other than updating containers and plugins on my Unraid machine. Any advice or suggestions would be greatly appreciated.
-
I'm on 6.9.2 and have 8 disk in the array (almost all 8TB) and two parity disks (both 8TB). Given case size, motherboard, HBA card, SSD cache and one SSD unassigned device, I'm maxed out as far as storage devices are concerned. My longer term goal is to increase capacity by increasing the standard disk size to whatever the new sweet spot is - maybe 14TB? So the problem is that first I need to buy 2 14 TB drives to replace the parity drives, and then a third 14 TB drive for data before I get any increased storage capacity. I had a similar problem moving from 4TB to 8TB, so it's not a new thing, and given the long rebuild times with larger disk sizes, I do feel that dual parity is needed. In reality, the important things are backed up, so it's not a mission critical issue, but it would just be a huge pain to rebuild from scratch. Is there any alternative? Or is there an Unraid roadmap of where parity is going? (Apologies for not keeping up on this.) It seems that with ever-increasing hdd sizes but minimal improvement in r/w speeds, the rebuild times will just get MUCH longer and dual parity becomes even more important.
-
I've managed to install a Win XP SP3 VM on my Unraid box (6.9.2), without too much trouble. The machine is pc-i440fx-5.1 (with SeaBIOS). I'm running two Logical CPUs and using 2GB RAM. But after installation when I check Device Manager I see some devices with the yellow exclamation mark indicating that the drivers have not been installed. So I've tried using Windows to update the drivers, searching on the virtual cd-rom, which is virtio-win-0.1.217.iso, and on the virtual floppy, which is viostor-31-03-2010-floppy.img. For some devices, like the Ethernet controller, the driver installs without a problem. But for some PCI devices and the Balloon driver (not sure what that is) there is a list of possible drivers. I believe Win XP SP3 is 32-bit, so I assume I should pick the xp/x86 ones but in the Uraid Wiki where it talks about loading drivers during installation it says to not use the x86 folder, and use the amd64 folder instead. Is this irrelevant for installing drivers after installation? Or is this because the Wiki is covering only 64-bit Windows OS's? Regardless, I've tried various drivers from and the messages I get are either that it's the wrong driver or that the installed file is newer than the one I've selected. When I've selected the older file, it installs and the yellow exclamation mark goes away, but the VM doesn't seem stable. If I leave it running, it ends up with a black screen, and I have to do a hard stop from the VM tab in Unraid. After that the VM won't boot at all. How do I get the correct drivers?
-
During my scanning, there's a bunch of popup messages on the lower right listing things like "Processing media for album...." or the occasional "Scanner error" when there's a problem (for me, usually a weird video file).
-
In the last few days I've had a problem with my speeds coming down substantially. I usually get around 25 MiB/s in total, but now I usually get around 6-8 MiB/s. What is odd is that if I restart the container, I get back to full speed initially, but then it comes down again. I use PIA (and Wireguard) and have tried different endpoints, with the same result. What I have noticed in the log files is that I get this line repeated every 15 minutes. 2022-05-05 20:20:48,836 DEBG 'start-script' stdout output: [info] Successfully assigned and bound incoming port 'nnnnn' I don't recall seeing this happening before, and wonder if this has anything to do with the slowing down. Or is this a PIA issue or something else? Edit: So after analysing what I could, it seems that the speed differences are probably a result of the vagaries of torrents. When I look at longer periods of total traffic, it's hard to discern any real pattern. So looks like nothing to worry about, although I'm still not sure whether the repeated log entry is expected behaviour.
-
So I understand from this that it's not a good idea to buy a Sandisk USB flashdrive to use with unRAID. But if I already have a Sandisk flashdrive and try it with unRAID and am able to license and boot unRAID with it, am I OK? (I have an unused unRAID key and a few Sandisk flashdrives sitting around, so this is not purely hypothetical.) Or is there still a risk that there will be a licensing issue down the road? And if I try to license the flashdrive and it fails to register or boot, does this invalidate my key?
-
Upgraded to the latest FCP (2022.01.16), and got an error message "Docker application Docker application binhex-rtorrentvpn has volumes being passed that are mounted by Unassigned Devices, but they are not mounted with the slave option has volumes being passed that are mounted by Unassigned Devices, but they are not mounted with the slave option". So I went to the settings for binhex-rtorrentvpn and fixed that, but after running Rescan under FCP I get the same message. Not sure what I should be doing. Also, haven't changed the docker app settings for a while, so not sure why this error is being picked up now - perhaps it's a new check? [Edit: My bad. Forgot that I had two volumes mounted, and had only fixed one of them. After fixing the other one it all looks good now.]
-
Thanks. I had already done some Googling and couldn't find anything that explains enough down at my level. Bottom line is: will there be any problems with 6.10 if I just leave things as they are?
-
"Use SSL/TLS" was set to "Auto". "Local TLD" setting was indeed "local". I followed the instructions, but I end up with an unsecure connection to the server. In Chrome I get a warning "This server could not prove that it is tower.local; its security certificate is not trusted by your computer's operating system. This may be caused by a misconfiguration or an attacker intercepting your connection." If I look at the Certificate I see this: "This CA Root certificate is not trusted. To enable trust, install this certificate in the Trusted Root Certification Authorities store." I realise that actually in the past I always had an insecure connection (I don't access the Web GUI other than from the local network). If I set "Use SSL/TLS" back to "Auto" I don't get a warning in the browser - but it's still an insecure connection. Just didn't think about it at the time. Sorry if it's not quite on-topic, but how do I set up a secure connection? I can't provision the Certificate as I get a "DNS rebinding protection enabled" error. I'm running the Pi-hole container, so I wonder if there's something I need to do there.
-
I'm on FCP 2022.01.06 and I started getting this error message labelled "Invalid Certificate 1": "Your Tower_unraid_bundle.pem certificate is for 'Tower' but your system's hostname is 'Tower.local'. Either adjust the system name and local TLD to match the certificate, or get a certificate that matches your settings." I haven't received this error before and haven't done anything with certificates for years, so I suspect this is the result of a new check that FCP is doing. Should I be doing something to fix this, and if so what? I don't know much about certificates and don't want to bork the system.
-
@Trozmagon How long was this shorter cable? I assume you mean the SFF-8088 to SFF-8088 external cable?
-
I recently started using the plug-in again and had the warning re "Cannot start session..." I'm also on 6.9.2. Here's a screenshot: I thought that with these settings my parity check would start early this morning (17th) at 1 am and pause at 9 am, but although it did start, it's now around 12 noon here and it's still running. Not sure if this is a result of the warning or an incorrect setting.
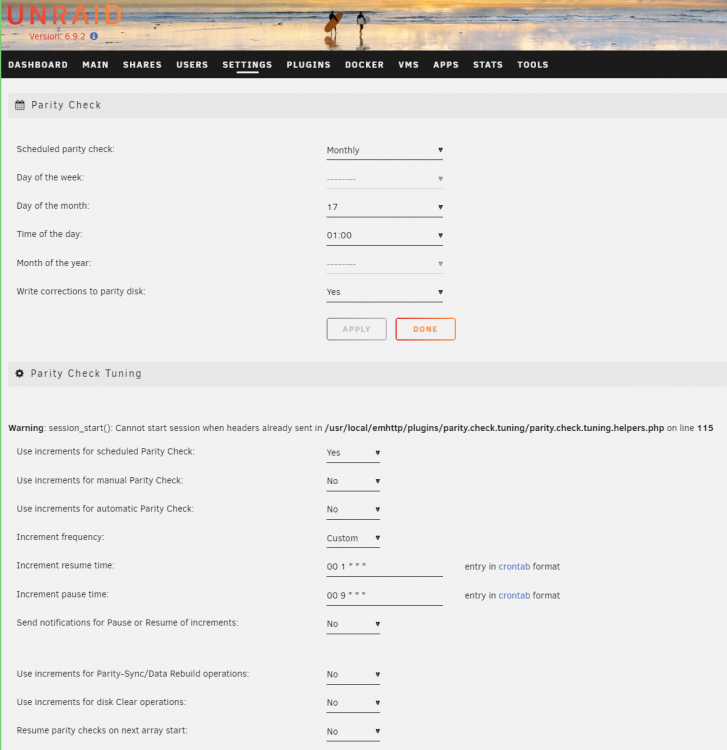
-
Just saw this post. No problems with the RM650x. In fact, I got another one for my then new PC build and one for my daughter's PC a few years ago, and all three run fine. (Also meant that I got to use the unused cables for my unRAID server 😉.)
-
I'm getting lots of entries in the access.log file: nnn.nnn.n.nnn - admin [02/May/2021:23:24:56 +0800] "POST /plugins/httprpc/action.php HTTP/1.1" 200 892 "http://nnn.nnn.n.nn:9080/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36" nnn.nnn.n.nnn - admin [02/May/2021:23:24:56 +0800] "POST /plugins/httprpc/action.php HTTP/1.1" 200 55 "http://nnn.nnn.n.nn:9080/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36" nnn.nnn.n.nnn - admin [02/May/2021:23:24:56 +0800] "GET /plugins/cpuload/action.php?_=1619845697880 HTTP/1.1" 200 14 "http://nnn.nnn.n.nn:9080/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36" nnn.nnn.n.nnn - admin [02/May/2021:23:24:58 +0800] "GET /plugins/diskspace/action.php?_=1619845697881 HTTP/1.1" 200 41 "http://nnn.nnn.n.nn:9080/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36" nnn.nnn.n.nnn - admin [02/May/2021:23:25:00 +0800] "POST /plugins/httprpc/action.php HTTP/1.1" 200 815 "http://nnn.nnn.n.nn:9080/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36" nnn.nnn.n.nnn - admin [02/May/2021:23:25:00 +0800] "POST /plugins/httprpc/action.php HTTP/1.1" 200 55 "http://nnn.nnn.n.nn:9080/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36" nnn.nnn.n.nnn - admin [02/May/2021:23:25:00 +0800] "GET /plugins/cpuload/action.php?_=1619845697882 HTTP/1.1" 200 14 "http://nnn.nnn.n.nn:9080/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36" nnn.nnn.n.nnn - admin [02/May/2021:23:25:04 +0800] "POST /plugins/httprpc/action.php HTTP/1.1" 200 704 "http://nnn.nnn.n.nn:9080/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36" nnn.nnn.n.nnn - admin [02/May/2021:23:25:04 +0800] "POST /plugins/httprpc/action.php HTTP/1.1" 200 55 "http://nnn.nnn.n.nn:9080/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36" nnn.nnn.n.nnn - admin [02/May/2021:23:25:04 +0800] "GET /plugins/cpuload/action.php?_=1619845697883 HTTP/1.1" 200 14 "http://nnn.nnn.n.nn:9080/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36" nnn.nnn.n.nnn - admin [02/May/2021:23:25:08 +0800] "POST /plugins/httprpc/action.php HTTP/1.1" 200 838 "http://nnn.nnn.n.nn:9080/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36" nnn.nnn.n.nnn - admin [02/May/2021:23:25:08 +0800] "POST /plugins/httprpc/action.php HTTP/1.1" 200 55 "http://nnn.nnn.n.nn:9080/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36" nnn.nnn.n.nnn - admin [02/May/2021:23:25:08 +0800] "GET /plugins/cpuload/action.php?_=1619845697884 HTTP/1.1" 200 14 "http://nnn.nnn.n.nn:9080/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36" This gets repeated constantly and I fill up a 10MB log file roughly every day. Is there something wrong with my setup or can I do something to fix this?


