




jay2068
Members
-
Joined
-
Last visited
Everything posted by jay2068
-
Oh yeah it's completely okay. In fact I will add it back as a new disk. I'm looking at getting a raid case
-
I did not know that. But yes it's in a very large workstation case that holds 18 disks. I'll do what you suggested.
-
I have spent over 800 dollars trying to fix this issue. And I think it might be software or config related?!?!? Timeline: Disk 11 20TB drive would just throw constant errors on every parity check Purchased new 22TB drive ($500 dollars damn what happened to disk prices!) Replaced 20TB with new 22TB and got constant errors again. Put 20TB in my linux workstation and ran scan. Smart ran clean, file scan ran clean. All files still there and accessable. Random opened files and they all worked. Purchased new $200 IT MODE card LSI 9305-16i IT Mode PCIe SATA Expansion Card, 16-Port 12Gbps PCIe 3.0 Still errors! Purchased brand new cables for all drives Now getting errors on three different drives! Attached the latest diag Please help! thebeast-diagnostics-20260518-0756.zip
-
Yep! It's at 44% this morning.. POC Intel 13th gen. Thanks for your help.
-
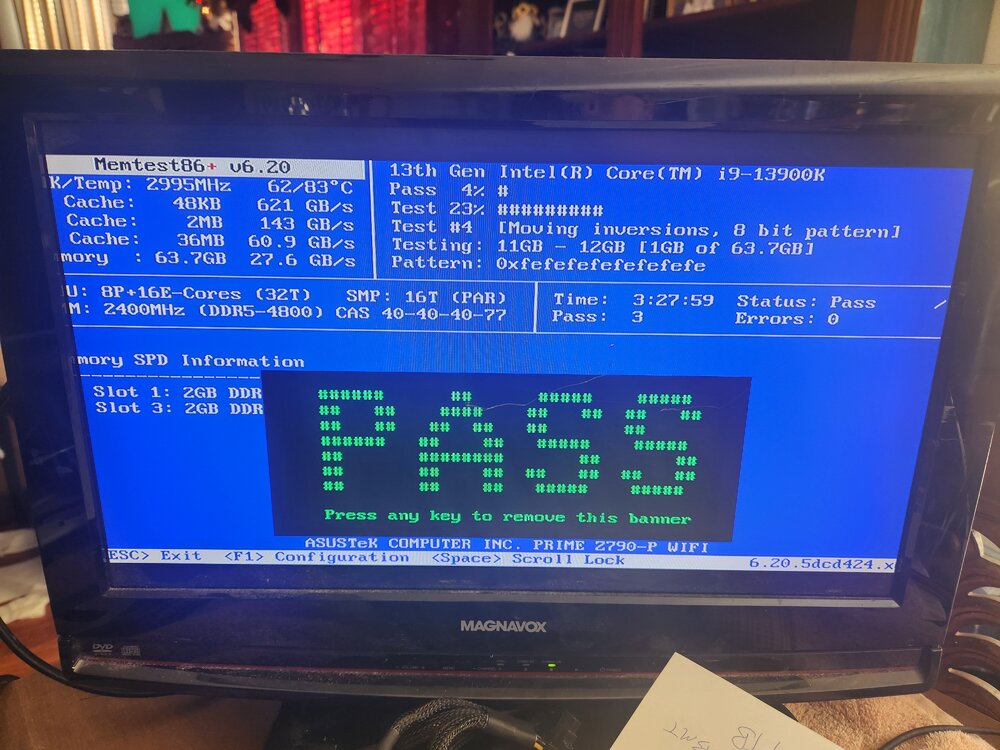
The mem test was a pass. So I'll try replacing my motherboard Do I need to do anything or just swap the guts? Going to Intel Core I9 9900K Coffee Lake on a Gigabyte Z390 Designare-CF with 96 GB memory.
-
Yeah I did the bios patch. I think I'm going to swap out my motherboard with my current desktop unit. As It's older but would be fine for unraid and I get an upgraded desktop
-
Ok Overnight I had it syslog local also. I'll run the memtest today and let you know. I have attached the recent diag file. thebeast-diagnostics-20250303-0741.zip
-
I send my syslog to a graylog instance on my other Unraid server. Does this help? Otherwise I can make it go local. graylog-search-result-relative-2592000.csv
-
Solved: Replaced motherboard with an older Intel Gen 9 from an intel 13 with bug. The Beast is sick! I lost a 20TB drive and purchased a new one. I replaced the drive. When the rebuild started, it stopped at a very low percentage (less than 3%). I tried a few times, and it stopped at lower percentages. After three times I decided to come here for help. I run less than 10 dockers and no VM's. I even tried disabling dockers and it still stopped. Can someone please look over my diags and see what Is going on. I appreciate it! Long live the beast! thebeast-diagnostics-20250301-0902.zip
-
Yeah I thought it was that. But I did do the patch on the CPU. And it seemed more stable after that. I'll turn syslog on. It could still be that issue.
-
I've been dealing with a plex server that is giving me a headache. I built this beast from scratch about a year ago. I had it running many VM's and dockers. I got sick of so many lock ups and hard resets and parity checks. Can someone please help me and look at my logs. I moved most of the dockers and all the VM's to a smaller Unraid file server. I have smart errors on disk 4 and Disk 20. I think these are near EOL and I will be replacing them soon. I don't belive this is causing the issue but I may be wrong. running: ASUSTeK COMPUTER INC. PRIME Z790-P WIFI , Version Rev 1.xx American Megatrends Inc., Version 1661 BIOS dated: Tue 25 Jun 2024 12:00 AM 13th Gen Intel® Core™ i9-13900K @ 5500 MHz 64 GiB DDR5 Unraid 7.0.0 (this happened before on 6. I like to keep it updated) Dockers running always: Plex, Deluge,dockersocket,mariadb,postgresql15,redis Dockers when needed: LocalAI, Steam-headless, Unmanic (Don't use these that much so usually off as I transitioned to second Unraid server) VM's Zero and turned off. Moved everything to different Unraid server. I have some NVME: DomainCache, DomainCacheTWO, PHOTOS,PLEXCACHE,DockerCache,Arraycache. I only use ArrayCahce, Docker Cache as the rest were migrated to the new Unraid server. I have attached my latest diag after a hard rest this morning. I appreciate any help! thebeast-diagnostics-20250201-1645.zip
-
Reviving old thread to tell my solution. I was using 1 GB of memory. Once I changed it to 4 GB it worked fine. YRMV
-
is this it? syslog
-
I already had it on. This is the syslog file from /etc/log syslog
-
I did just recently hear about that. The fix isn't supposed to be released until August sometime. With the Syslog Server does it need to go to an actual Syslog Server outside of Unraid?
-
I have attached my diagnostics. I have no idea why it's becoming unresponsive. Sometimes it runs for a day, a few days or a few hours. I have it set to do a parity check on off hours. The web interface can't be reached, no docker ports become available, and I can't SSH into the server. I have to do another hard reboot. I don't want to continue doing that. Any help is appreciated. Thanks! thebeast-diagnostics-20240726-1126.zip
-
Here are my Diagonstics thebeast-diagnostics-20240718-1043.zip
-
I ran out of space on my boot because of this. Why are they put here? I don't see in the docker config where to set this. There is hundreds of these files. -rw------- 1 root root 418 Jun 13 06:11 unmanic_file_conversion-zzrny-1716838509.cfg -rw------- 1 root root 418 Jun 18 00:55 unmanic_file_conversion-zzsng-1718689869.cfg -rw------- 1 root root 418 Apr 30 15:17 unmanic_file_conversion-zzsye-1714508250.cfg -rw------- 1 root root 418 Jun 2 05:38 unmanic_file_conversion-zzttt-1716838930.cfg -rw------- 1 root root 418 Jun 20 23:35 unmanic_file_conversion-zzxhq-1718689544.cfg -rw------- 1 root root 435 Aug 13 2023 unmanic_file_conversion-zzyhy-1691876357.cfg root@TheBeast:/boot/config/shares
-
Everyhting is back working. I modified the docker network type also.
-
Ok I'll try a reboot and report back.
-
I see btfrs error and it also says it requires a reboot Mar 9 22:31:11 Tower12 kernel: BTRFS critical (device loop2): corrupt leaf: block=30805327872 slot=227 extent bytenr=30800609280 len=16384 invalid generation, have 9837406843266202086 expect (0, 1967407] Mar 9 22:31:11 Tower12 kernel: BTRFS info (device loop2): leaf 30805327872 gen 1967406 total ptrs 249 free space 221 owner 2 Mar 9 22:31:11 Tower12 kernel: item 0 key (30796890112 169 0) itemoff 16250 itemsize 33 Mar 9 22:31:11 Tower12 kernel: extent refs 1 gen 1843974 flags 2 Mar 9 22:31:11 Tower12 kernel: ref#0: tree block backref root 13899 Mar 9 22:31:11 Tower12 kernel: item 1 key (30796906496 169 0) itemoff 16190 itemsize 60 and Mar 9 22:31:11 Tower12 kernel: ref#0: tree block backref root 7 Mar 9 22:31:11 Tower12 kernel: BTRFS error (device loop2): block=30805327872 write time tree block corruption detected Mar 9 22:31:13 Tower12 kernel: BTRFS: error (device loop2) in btrfs_commit_transaction:2377: errno=-5 IO failure (Error while writing out transaction) Mar 9 22:31:13 Tower12 kernel: BTRFS info (device loop2): forced readonly Mar 9 22:31:13 Tower12 kernel: BTRFS warning (device loop2): Skipping commit of aborted transaction. Mar 9 22:31:13 Tower12 kernel: BTRFS: error (device loop2) in cleanup_transaction:1942: errno=-5 IO failure Mar 9 22:31:13 Tower12 kernel: BTRFS warning (device loop2): Skipping commit of aborted transaction. Mar 9 22:31:13 Tower12 kernel: BTRFS: error (device loop2) in cleanup_transaction:1942: errno=-5 IO failure Mar 10 00:20:49 Tower12 kernel: Fixing recursive fault but reboot is needed! I think I should reboot and see where I am at.
-
Attached is the log unraid_syslog.txt
-
I had a failed 3TB seagate drive. I replaced it with a 4TB WD Red. I have done replacments before as I've had my server a long time. Normally it just rebuilds and I'm good to go. This time it said it would take 11 hours. So I stopped all my VM's and dockers to make sure it wasn't doing anything. Well I wake up this morning and I can't get to the web interface and all the dockers are back up (VM's still down). So I stopped all the dockers with: docker kill $(docker ps -q) This command started showing all the container ID's and just stopped after 19 ID's. Hasn't returned to the command line in over an hour. I also ran:/etc/rc.d/rc.php-fpm restart That was to try and restart the web interface. The shutting down failed (I assume because it was already down) but that is also stuck at starting php-fpm for over an hour. I don't know where the restore is at or what I should do. I don't want to reboot if it's still working on rebuild. It's been rebuilding since yesterday at 3 PM Any help is appreciated.
-
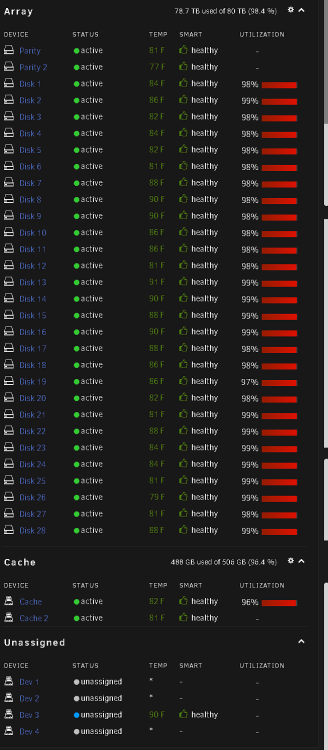
Someone help a poor beggar. I need more space, can you spare a terabyte or two? j/k I need to clean up I think or invest in larger hard drives. I never thought I would get this full!
-
I'll take that as a no



