




tkenn1s
Members
-
Joined
-
Last visited
-
Same issue here. Dug through the github repo and it looks like the problem was added as part of commit fd16657. For a really quick fix, modify /usr/local/emhttp/plugins/community.applications/include/helpers.php, changing dontCache = false to dontCache = true on line 30. *** 27,33 **** ######################################## # Sanitize output from plugin function # ######################################## ! function ca_plugin($method, $plugin_file = '',$dontCache = false) { global $caPaths; static $attributeCache = []; static $PLUGIN_METHODS = ['dump', 'changes', 'alert', 'validate', 'check', 'checkall', 'update', 'remove', 'install', 'attributes']; --- 27,33 ---- ######################################## # Sanitize output from plugin function # ######################################## ! function ca_plugin($method, $plugin_file = '',$dontCache = true) { global $caPaths; static $attributeCache = []; static $PLUGIN_METHODS = ['dump', 'changes', 'alert', 'validate', 'check', 'checkall', 'update', 'remove', 'install', 'attributes']; I have no idea what this could break, so use at your own risk.
-
@pOpYRaid Do you have the recycle bin active? It appears there are two issues. The initial error appears to be due to Bug 15527; this was fixed in 4.20.0 and backported to 4.19.6. 4.20.1 introduced a new issue, Bug 15659; which I'm guessing is triggered by the recycle plugin workaround. Unfortunately I don't have a spare server to verify with the 7.0 beta.
-
As another data point; this does not seem to affect all nvidia GPUs. I'm running the plugin on 6.11.5 w/ a Quadro P2200 and there are no such logs in syslog.
-
Apologies if this is not the right topic to post; please let me know if there's a better place to do so. I've been unable to change the docker icon from the unraid web UI; see bug: I was able to work around this issue by: modifying the `<Icon>` tag in the original template [eg. within `/boot/config/plugins/dockerMan/templates/`] and not the user template removing images from both `/var/local/emhttp/plugins/dynamix.docker.manager/images/` and `/var/lib/docker/unraid/images/` refreshing the main docker page
-
I've been trying [unsuccessfully] to change the icon for a couple different containers. However I tried to change them [modifying the URL in the template, removing & reinstalling the template, removing images from the emhttp directory, ...], it always downloaded the original icon. After poking around in /usr/local/emhttp/plugins/dynamix.docker.manager, I figured out that it was downloading the icon from the original docker template and not the icon from the user template; which meant it would never pick up a different icon. The error comes from the getIcon() method: public function getIcon($Repository,$contName,$tmpIconUrl='') { global $docroot, $dockerManPaths; $imgUrl = $this->getTemplateValue($Repository, 'Icon','all',$contName); ^^^ 'all' here loads all of the templates [both original and user] and, depending upon their sort order, the original template might override the user template. Which, in my case, it is. I was able to get this to work as I wanted by using 'user' instead of 'all'. But, it's unclear if that's the correct solution.
-
Just to clarify ... I wasn't "doing it wrong". I understand that the directories are mapped. That wasn't the issue. What I needed access to were the _tools_ [ie. par2, etc...]. Those aren't natively available on unraid, but are installed within the container.
-
How are backup notifications sent? And, what format are they in? I'd like to track backup completion using something like Healthchecks. I could write a script to do this, but it'd be better if CA Backup could do it natively.
-
I'm seeing my card always reporting as power level P0 with 6.9.0-rc2. However, when I was using the nvidia-plugin from LinuxServer.io, it would always go back to P8 when idle. It looks like even trying to force power save mode with `nvidia-smi -pm 1` doesn't switch the card to P8. How do I get my card into P8 mode since it should be spending most of its time idle? # nvidia-smi -pm 1 Enabled persistence mode for GPU 00000000:03:00.0. All done. # nvidia-smi Sat Feb 27 16:31:38 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 455.45.01 Driver Version: 455.45.01 CUDA Version: 11.1 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Quadro P2200 On | 00000000:03:00.0 Off | N/A | | 57% 44C P0 20W / 75W | 0MiB / 5058MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+
-
One more feature request. FR: When I move to the next page, it keeps me at the bottom of the page. It would be nice if it repositions you at the top.
-
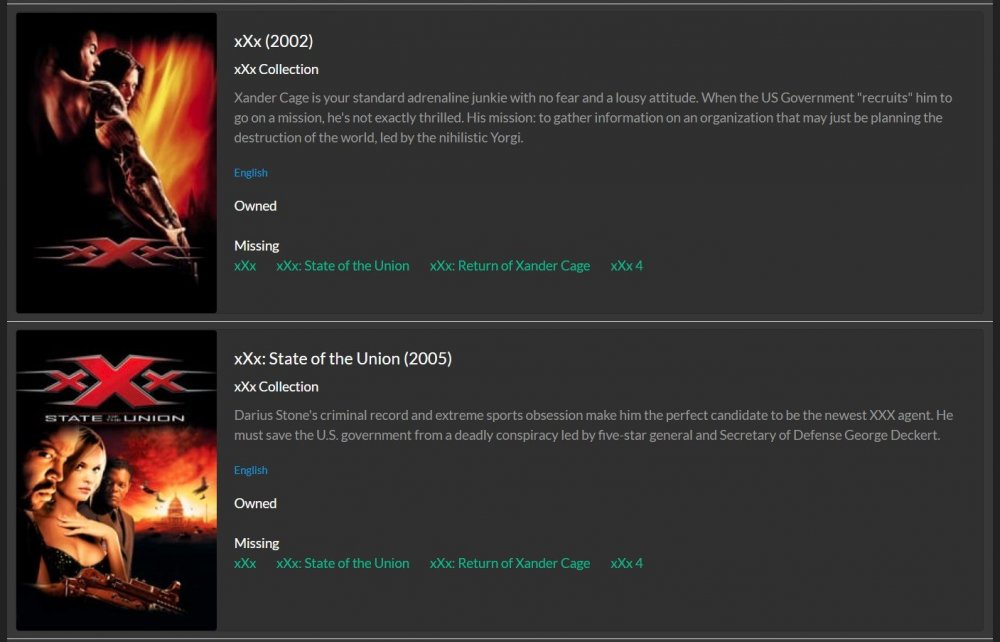
@housewrecker Thank you for GAPS. This is awesome. Do you have an official place where I can make feature requests or report bugs? FR: I would love to be able to mark items as "do not want" [eg. there are lots of sequels that were complete flops and I don't particularly care to waste storage for them] FR: It would be nice to be able to see that a scan is in progress. I started a search for my library and navigated away to another tab. When I went back to 'missing', it just showed me there was nothing available [and did not show a scan was already in progress]. I assumed it was still working in the background and after a few hours I saw recommendations. Bug: I really like the links to tmdb for other movies / what I have. However, they all just point to 'https://www.themoviedb.org/movie/' and not any particular movie. Bug: I'm getting suggestions and the "owned" item is blank [see screenshot attached]. I do have "xXx: Return of Xander Cage", which shows in "Missing", but also doesn't give me a recommendation card for.
-
Thanks for the write up Maglin. Followed your instructions and everything flashed perfectly on two Perc H310's . Was back up-and-running in only a few minutes.
-
Thanks for the instructions on flashing the H310. Worked like a champ. However, there was one small glitch. At least for me, the changes to config.sys in the toolset prevented MegaRec from working [I got a "not enough extended memory" error when running it]. I went back to the stock rufus config.sys and MegaRec worked perfectly.
-
BTW; as a temporary workaround, you can get sabnzbd running again by manually editing sabnzbd/config/admin/sabnzbd.ini and disabling HTTPS. Look for the line containing "enable_https" and change the value from '0' to '1'.
-
Removed server certs and I'm getting the same error as unevent. sabnzbd won't start any more.
-
I did some more digging. I setup a host directory to persist data, etc... and I noticed logs/server.log. Looking there, I see: [2015-08-10 22:36:58,183] <db-server> ERROR system - [exec] error, rc=14, output=all output going to: /usr/lib/unifi/logs/mongod.log [2015-08-10 22:36:58,184] <db-server> INFO db - DbServer stopped From there, I logged into the UniFi docker and looked at the mongo log file Mon Aug 10 22:41:04.091 [initandlisten] LogFile::synchronousAppend failed with 8192 bytes unwritten out of 8192 bytes; b=0x35d4000 errno:22 Invalid argument Mon Aug 10 22:41:04.091 [initandlisten] Fatal Assertion 13515 0x981b16 0x945c1d 0x962a3f 0x6da3e2 0x6da6eb 0x6dd5c5 0x6d4bd5 0x589a84 0x58b2af 0x56ad05 0x2b070d8b5ec5 0x58210c mongod(_ZN5mongo15printStackTraceERSo+0x26) [0x981b16] mongod(_ZN5mongo13fassertFailedEi+0x4d) [0x945c1d] mongod(_ZN5mongo7LogFile17synchronousAppendEPKvm+0x17f) [0x962a3f] mongod(_ZN5mongo3dur20_preallocateIsFasterEv+0xc2) [0x6da3e2] mongod(_ZN5mongo3dur19preallocateIsFasterEv+0x1b) [0x6da6eb] mongod(_ZN5mongo3dur16preallocateFilesEv+0x105) [0x6dd5c5] mongod(_ZN5mongo3dur7startupEv+0x35) [0x6d4bd5] mongod(_ZN5mongo14_initAndListenEi+0x894) [0x589a84] mongod(_ZN5mongo13initAndListenEi+0xf) [0x58b2af] mongod(main+0x2d5) [0x56ad05] Thinking maybe the problem had something to do with the host filesystem, I removed the link, restarted the docker and lo and behold, I got the UniFi admin page! Question ... How do I set things up so I can actually point to the host filesystem so I can retain state, etc? Is it a problem with permissions?


