ridewithjoe
Members
-
Joined
-
Last visited
Everything posted by ridewithjoe
-
I seem to remember there was the ability to configure the order of when docker containers would start. I cannot seem to remember where that is configured in 7.2.2
-
Running into an issue with swag on startup. seeing this error (redacted my domains and other private info) : [docker run] -d --name='SWAG' --net='br2.80' --ip='10.168.80.50' --pids-limit 2048 --privileged=true -e TZ="America/New_York" -e HOST_OS="Unraid" -e HOST_HOSTNAME="XXXXXX" -e HOST_CONTAINERNAME="SWAG" -e 'TCP_PORT_80'='80' -e 'TCP_PORT_443'='443' -e '[EMAIL'='XXXXXXXX]' -e 'URL'='XXXX.XXX' -e 'SUBDOMAINS'='XXXXXX,XXXXXX,XXXXXX' -e 'ONLY_SUBDOMAINS'='true' -e 'VALIDATION'='dns' -e 'DNSPLUGIN'='cloudflare' -e 'EXTRA_DOMAINS'='' -e 'STAGING'='false' -e 'DUCKDNSTOKEN'='' -e 'PROPAGATION'='30' -e 'MAXMINDDB_LICENSE_KEY'='XXXXXXXXXXXX' -e 'DOCKER_MODS'='linuxserver/mods:swag-maxmind' -e 'MAXMINDDB_USER_ID'='XXXXXXX' -e 'PUID'='99' -e 'PGID'='100' -l net.unraid.docker.managed=dockerman -l net.unraid.docker.webui='[IP]:[PORT:443]' -l net.unraid.docker.icon='linuxserver-ls-logo.png' -v '/mnt/user/appdata/joeproxy_2':'/config':'rw' -v '/mnt/user/remotelogs/XXXXXX/':'/var/log/':'rw' --cap-add=NET_ADMIN 'lscr.io/linuxserver/swag' Log output: Using Let's Encrypt as the cert provider SUBDOMAINS entered, processing Sub-domains processed are: XXXXXXXX E-mail address entered: [XXXXXXXX] dns validation via cloudflare plugin is selected Generating new certificate certbot: error: unrecognized arguments: --dns--propagation-seconds=30 ERROR: Cert does not exist! Please see the validation error above. Make sure you entered correct credentials into the /config/dns-conf/cloudflare.ini file. Running CERTBOT by itself works: root:/mnt/cache/appdata/cloudflare-ddns-config# docker exec -it XXXXXXX certbot certonly \ --dns-cloudflare \ --dns-cloudflare-credentials /config/dns-conf/cloudflare.ini \ --dns-cloudflare-propagation-seconds 30 \ -d XXXXXXXX \ --email [XXXXXXXX] \ --agree-tos \ --non-interactive Saving debug log to /var/log/letsencrypt/letsencrypt.log Account registered. Requesting a certificate for XXXXXXXX Waiting 30 seconds for DNS changes to propagate Successfully received certificate. Certificate is saved at: /etc/letsencrypt/live/XXXXXXXX/fullchain.pem Key is saved at: /etc/letsencrypt/live/XXXXXXXXX/privkey.pem This certificate expires on 2025-10-19. These files will be updated when the certificate renews. NEXT STEPS: - The certificate will need to be renewed before it expires. Certbot can automatically renew the certificate in the background, but you may need to take steps to enable that functionality. See https://certbot.org/renewal-setup for instructions. - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Comments: This tells me that my cloudflare.ini keys are correct and the file permissions are working. I'm at a loss on what could be happening. It has been working fine for a few years. I can confirm the same error occurs when using ZeroSSL.
-
Running into an issue with swag on startup. seeing this error (redacted my domains and other private info) : Docker run: docker run -d --name='SWAG' --net='br2.80' --ip='10.168.80.50' --pids-limit 2048 --privileged=true -e TZ="America/New_York" -e HOST_OS="Unraid" -e HOST_HOSTNAME="XXXXXX" -e HOST_CONTAINERNAME="SWAG" -e 'TCP_PORT_80'='80' -e 'TCP_PORT_443'='443' -e 'EMAIL'='XXXXXXXX' -e 'URL'='st6.com' -e 'SUBDOMAINS'='XXXXXX,XXXXXX,XXXXXX' -e 'ONLY_SUBDOMAINS'='true' -e 'VALIDATION'='dns' -e 'DNSPLUGIN'='cloudflare' -e 'EXTRA_DOMAINS'='' -e 'STAGING'='false' -e 'DUCKDNSTOKEN'='' -e 'PROPAGATION'='30' -e 'MAXMINDDB_LICENSE_KEY'='XXXXXXXXXXXX' -e 'DOCKER_MODS'='linuxserver/mods:swag-maxmind' -e 'MAXMINDDB_USER_ID'='1190058' -e 'PUID'='99' -e 'PGID'='100' -l net.unraid.docker.managed=dockerman -l net.unraid.docker.webui='https://[IP]:[PORT:443]' -l net.unraid.docker.icon='https://raw.githubusercontent.com/linuxserver/docker-templates/master/linuxserver.io/img/linuxserver-ls-logo.png' -v '/mnt/user/appdata/joeproxy_2':'/config':'rw' -v '/mnt/user/remotelogs/XXXXXX/':'/var/log/':'rw' --cap-add=NET_ADMIN 'lscr.io/linuxserver/swag' Log output: Using Let's Encrypt as the cert provider SUBDOMAINS entered, processing Sub-domains processed are: XXXXXXXX E-mail address entered: XXXXXXXX dns validation via cloudflare plugin is selected Generating new certificate ERROR: Cert does not exist! Please see the validation error above. Make sure you entered correct credentials into the /config/dns-conf/cloudflare.ini file. Running CERTBOT by itself works: root@XXXXXX:/mnt/cache/appdata/cloudflare-ddns-config# docker exec -it XXXXXXX certbot certonly \ --dns-cloudflare \ --dns-cloudflare-credentials /config/dns-conf/cloudflare.ini \ --dns-cloudflare-propagation-seconds 30 \ -d joeflix.st6.com \ --email XXXXXXXX \ --agree-tos \ --non-interactive Saving debug log to /var/log/letsencrypt/letsencrypt.log Account registered. Requesting a certificate for XXXXXXXX Waiting 30 seconds for DNS changes to propagate Successfully received certificate. Certificate is saved at: /etc/letsencrypt/live/XXXXXXXX/fullchain.pem Key is saved at: /etc/letsencrypt/live/XXXXXXXXX/privkey.pem This certificate expires on 2025-10-19. These files will be updated when the certificate renews. NEXT STEPS: - The certificate will need to be renewed before it expires. Certbot can automatically renew the certificate in the background, but you may need to take steps to enable that functionality. See https://certbot.org/renewal-setup for instructions. - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - If you like Certbot, please consider supporting our work by: * Donating to ISRG / Let's Encrypt: https://letsencrypt.org/donate * Donating to EFF: https://eff.org/donate-le - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - This tells me that my cloudflare.ini keys are correct and the file permissions are working. I'm at a loss on what could be happening. It has been working fine for a few years.
-
I ran an upgrade to day from 7.1.3 to 7.1.4 and my docker containers failed to start. It appears my VLAN interfaces on br2 are not available any longer. I rolled back and have the same issue. Not sure what went wrong. Tried removing and redefining but that hasn't worked either. nasvm-diagnostics-20250624_0745.zip
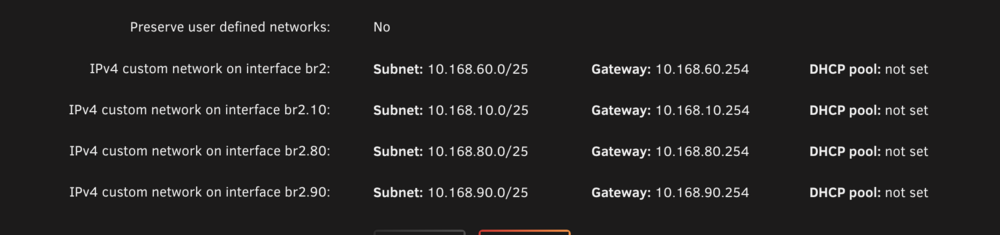
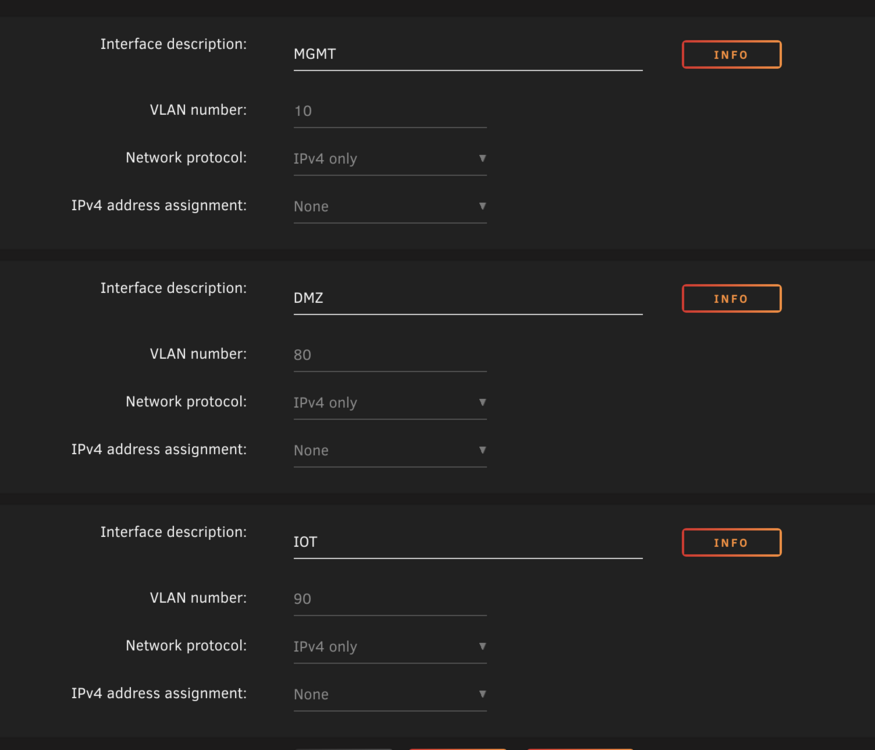
-
Lost entire docker custom vlan definitions after upgrading. Downgrading did not fix the issue. Custom defined VLAN no longer appear in docker network droodown nasvm-diagnostics-20250624_0745.zip
-
UPDATE: I restored the backup of my USB and was able to boot into UNRAID without the error and everything is working. I would be interested in know what caused the issue. I plan on replacing the USB drive just to be safe.
-
I just updated from 7.1.2 to 7.1.3 and rebooted. everything seems fine but seeing this banner "Your flash drive is corrupted or offline. Post your diagnostics in the forum for help." I pulled the drive and did a scandisk and it's fine and the system reboots fine but reporting this error still and docker doesn't appear to want to start. I have attached diagnostics but am assuming there is some issue with the drive that may indicate it needs replaced. nasvm-diagnostics-20250605-2021.zip
-
Sometime last night docker dropped and now fails to start. Cold restart of the server hasn't helped. Not seeing much in the syslog other than it failed to start. Any thoughts? nasvm-diagnostics-20250424-0856.zip
-
That was the better solution….while both solutions work, simply removing the IP on the interface and defining the network and gateway in the docker settings.
-
My expectation was that it would pick it up as well but it doesn’t… let me try removing the IP on the interface…. I don’t need an IP on it specifically. That would be a better fix.
-
Yes exactly except in my case br2 is not editable

-
This resolved the issue…. I find it odd that you cannot define the getaway in the UNRAID GUI. You can see that it is not defined but there is no capability to edit it.
-
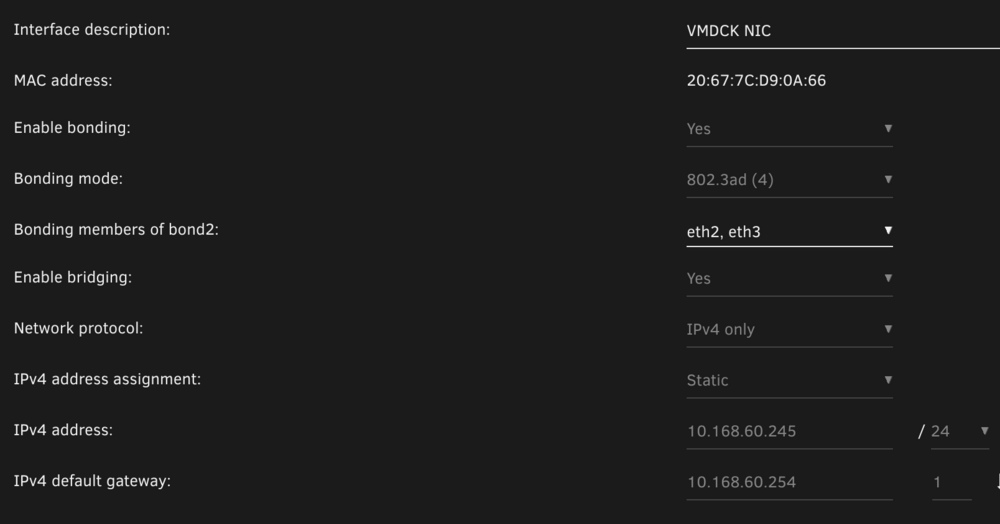
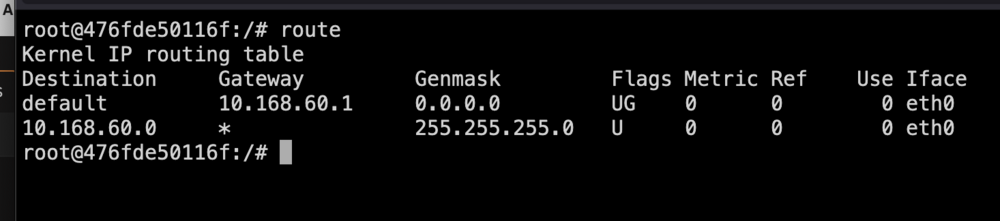
I know by default that br0 is where docker is bridging... I'm using a custom config. I have 4 network interfaces.... configured into two 802.11ad bonds. bond0 and bond2. bond0 is the admin interface for unraid on a management vlan. bond2 is the interface that is a trunk interface for multiple vlans. Some dockers are on br2.80 br2 - is on vlan 60 the native vlan for the trunk. Additional vlans are: br2.10 br2.80 The bond2 interface is assigned an ip of 10.168.60.245/24 with a gateway of 10.168.60.254 I have several docker containers running on br2.80 and they are running fine. They show the proper gateway however the containers on vlan 60 should be showing the same host interface default gateway of 10.168.60.254 however they are getting a gateway of 10.168.60.1. The docker network doesn't seem to pickup the default gateway of that host interface but the sub interface is getting the gateway I have assigned. in the custom network just fine. There should be a simple way to assign a custom default gateway for a container. The output of 'docker network inspect br2': [ { "Name": "br2", "Id": "17ca4604ab87ae68e47df153062a8bbdb7e45466e5f95e1099a8d4efffb4714c", "Created": "2024-10-20T18:18:34.938423495-04:00", "Scope": "local", "Driver": "ipvlan", "EnableIPv6": false, "IPAM": { "Driver": "default", "Options": {}, "Config": [ { "Subnet": "10.168.60.0/24", "AuxiliaryAddresses": { "server": "10.168.60.245" } } ] }, "Internal": false, "Attachable": false, "Ingress": false, "ConfigFrom": { "Network": "" }, "ConfigOnly": false, "Containers": {}, "Options": { "parent": "br2" }, "Labels": {} } ] The output of 'docker network inspect br2.80': [ { "Name": "br2.80", "Id": "f22dcc51a4a813565fcc3385354c2c34e28a73f836151fe6ba25c62cc6ddb91a", "Created": "2024-10-20T18:18:35.256187663-04:00", "Scope": "local", "Driver": "ipvlan", "EnableIPv6": false, "IPAM": { "Driver": "default", "Options": {}, "Config": [ { "Subnet": "10.168.80.0/24", "Gateway": "10.168.80.254" } ] }, "Internal": false, "Attachable": false, "Ingress": false, "ConfigFrom": { "Network": "" }, "ConfigOnly": false, "Containers": { "7a7642e1c24a2409ef5aa31c8293c9c2b14c66bfae19c6247de32d1b3632bfdb": { "Name": "bhdelugevpn", "EndpointID": "a7db7f8ae3ae19cc49566e306ab334a400a4f5f15ea5fc2ef434b76a8ac4f417", "MacAddress": "", "IPv4Address": "10.168.80.1/24", "IPv6Address": "" }, "f51bea5753b086b0af16d303a6c1773715b1b8b0ef91a599749b1a510b88eb8c": { "Name": "plex", "EndpointID": "ebc4596d489b6242b007adb4f92ca75526046750300dfc26dc367b254269703f", "MacAddress": "", "IPv4Address": "10.168.80.10/24", "IPv6Address": "" } }, "Options": { "parent": "br2.80" }, "Labels": {} } ]
-
I have done this.... that is not the issue... the issue i that the container is not using the default gateway that is assigned to br2. The other custom networks are operating properly. I know my setup is a bit different. I am deliberately configuring a trunk interface with VLANs so that I can set certain docker containers to run on specific network subnets. nasvm-diagnostics-20241020-2105.zip
-
I have a installed a second NIC in my server on a VLAN to segment docker traffic. I have bridging enabled (br2). The issue I'm seeing is that the docker container that gets attached to br2 is not picking up the gateway of the host interface.

-
I see the same thing when the VPN is enabled. When it’s disabled the speeds are much faster. It appears the vpn provider is limiting the bandwidth.
-
i was hoping it would be that simple. i didn’t want to reboot first in case it cleared something i needed for further troubleshooting. nevertheless it’s recovered after a reboot.
-
I’m in the process of moving data off my array drives and reformatting to zfs. so far it’s been successful. the latest drive (10) when i restored the array, all the shares have vanished. I’ve not seen this before and not sure if something went horribly wrong. i pulled drags and stopped the array, not knowing how to proceed nasvm-diagnostics-20240831-0940.zip
-
I think that is at least part of what I’m experiencing. Is this an issue that is being worked on and potentially resolvable or just something we need to live with due to the way zfs works?
-
I think it has to do with my effort to upgrade my drives to zfs. It’s induced some thing that I will have to manage differently. Right now copying data from drives to upgrade them to zfs and copy data back seems to be destabilizing everything.
-
I have a situation where my unraid server is appearing to hang when I try stopping the array. I've noticed that disk to disk file copies take a lot longer than they should and performance is just not what I've experienced typically. I need to narrow it down but not really sure where to begin. I have attached diags of it currently. It's been trying to stop the array for several hours now. nasvm-diagnostics-20240820-1532.zip
-
Thank you for the guidance. I removed the second cable in the event that is causing an issue. After rebooting everything I am now rebuilding the drives. I see a lot of these in the logs: Jul 7 14:29:39 nasvm inotifywait[25822]: Failed to watch /mnt/disk13; upper limit on inotify watches reached! Jul 7 14:29:39 nasvm inotifywait[25822]: Please increase the amount of inotify watches allowed per user via `/proc/sys/fs/inotify/max_user_watches'. I have increased that value in the past when I've seen these... it's now at 80000.... I don;t want to keep increasing it if something else is causing the errors.
-
I tried again and the new config worked.... I completed the recommended steps and attached is the latest diagnostic. nasvm-diagnostics-20240707-1021.zip
-
Set new config as suggested…however I don’t see “parity is already valid” as an option.
-
I had an issue in my dual parity array. I had two drives drop out for some reason. I was rebuilding them and they hit about 50% and the server appeared to hang for about 12 hours. The gui worked but nothing really was updating. I could see errors in syslog indicating errors connecting to the unraid API. I was able to ssh and issue a reboot but again everything was hung so I had little else I could do but powercycle the server.... now the array shows a 3rd drive that dropped out but the other two never finished rebuilding.... what is the best way to recover from this state. I've attached diags but I don't thing they will help much due to the need to power cycle. nasvm-diagnostics-20240707-0706.zip