





jeffreywhunter
Members
-
Joined
-
Last visited
-
It was an easy fix once I understood it. Just fall back to the appropriate driver. Why anyone would force the latest driver in such an update is a mystery. Honor what's there - or at least give us the option to retain the existing driver...
-
Nvidia Driver Plugin - Upgrade Path Breaks Pascal GPUs (Driver Branch Not Honored) I ran into an issue after upgrading to the latest Nvidia Driver (and at the same time I had upgraded from 7.2.2 to 7.2.3 - not sure which, but one of them caused my Nvidia GPU (Quadro P2000, Pascal) to disappear entirely from the system because it upgraded the driver to 595.x from 580.142 (which is the latest version that supports the P2000). Environment: Unraid: 7.2.3 (kernel 6.12.54) GPU: NVIDIA Quadro P2000 (Pascal, device ID 10de:1c30) Plugin: Nvidia Driver Original working driver: 580.x branch Issue observed after upgrade: Driver was automatically set to 595.58.03 (Production/latest) nvidia-smi failed: “couldn't communicate with the NVIDIA driver” /dev/nvidia* devices were not created dmesg repeatedly showed: GPU detected as P2000 but “supported through 580.xx Legacy drivers” “595.xx driver will ignore” “No NVIDIA GPU found” Result: Docker containers requiring GPU (Plex in this case) failed to start due to missing /dev/nvidia0 System behavior appeared as if GPU was not present Resolution: Manually changed preferred driver version to 580.142 Rebooted GPU immediately restored: /dev/nvidia* present nvidia-smi functional Plex container started normally Root cause (as understood): Plugin upgrade or Unraid upgrade defaulted driver selection to latest/Production branch That branch (595.x) does not support Pascal GPUs properly and ignores them entirely The plugin correctly identifies the recommended driver (580.x), but does not preserve or enforce it across upgrades Request / Suggestion: Would it be possible for the plugin to honor the currently installed/working driver branch across upgrades, especially when: A GPU is already configured and working The plugin can detect a recommended compatible version (e.g., 580.x for Pascal) A newer branch would result in loss of GPU functionality At minimum, one of the following would help: Preserve the existing driver version on upgrade instead of defaulting to latest Automatically constrain upgrades to the compatible branch (e.g., stay within 580.x for Pascal GPUs) Provide a warning before switching to an incompatible branch Optionally block auto-selection of drivers known to ignore the detected GPU Right now, the upgrade path can silently move a working system into a non-functional state for older but still widely used GPUs. At least identify the issue and prevent the upgrade or offer a notification of some sort... Thanks for the work on the recent per-GPU detection enhancements - those made diagnosis much easier. It would be great to extend that logic into upgrade behavior as well.
-
Also on version 7.2.3. I did the unraid-api stop and unraid-api start from the terminal. root@HunterNAS:~# unraid-api stop [PM2] [unraid-api](0) ✓ root@HunterNAS:~# unraid-api start Starting the Unraid API [PM2][WARN] Applications unraid-api not running, starting... [PM2][WARN] App unraid-api has option 'wait_ready' set, waiting for app to be ready... [PM2] App [unraid-api] launched (1 instances) +--- unraid-api namespace : default version : 4.31.1+726ae51e pid : 1287024 pm2 id : 0 status : online mode : fork restarted : 0 uptime : 30s memory usage : 223.4mb error log : /var/log/graphql-api.log watching : no PID file : /var/log/.pm2/pids/unraid-api-0.pid root@HunterNAS:~# I can see the server from the unraid connect server management. But trying to load the server link (https://10-253-0-1.xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.myunraid.net:61234/) just returns "this site can't be reached". Any suggestions?
-
I'm looking for a replacment for Nerdtools, specifically the Screen function. Is there a replacement? I've not been able to find anything on the Apps store.
-
I'm not able to log into my unraid server externally using the Server Routes FQDN WAN. FQDN Lan works in my local network. MyUnraid account logs in and I see the server there. I must be missing something. Thanks!
-
I have an APC BR1500G UPS installed and connected via USB to my Unraid 7.0 server. Everything works. I see UPS in UPSSettings. When I try to run the ACPTEST it fails. I stop the daemon (/etc/rc.d/rc.apcupsd stop), then when I try to run ACPTEST, says command not found. I searched for ACPTEST on the system, but didn't find anything. Is there something I need to install in order to get ACPTEST (used to be in Nerdtools/Nerdpack but that does not support 7.0) to work in UR 7.0+?
-
Perfect thanks! Much improved version!!!
-
I just upgraded to 7.0.0 and was looking to update all my plugins and noticed that Disk Location states "not available" in the Status Column (see pic). Is there a problem I need to fix on my side after the 7.0.0 update?

-
Just wanted to share a successful Plex server setup for anyone running older hardware and considering GPU offload. System Specs: CPU: Intel i5-2600K GPU: NVIDIA Quadro P2000 Motherboard: ASUS P8Z77-V LK RAM: 32GB DDR3 OS: Unraid 6.12.x Docker: Plex Media Server (official image) NVIDIA Driver Plugin: v565.77 (New Feature Branch) Goal: Enable GPU-based hardware transcoding for multiple concurrent Plex streams—including 4K → 1080p—without maxing out the CPU. Key Steps: Installed the NVIDIA driver plugin via the Unraid CA. Passed the P2000 to the Plex container using: bash --runtime=nvidia --device=/dev/nvidia0 --device=/dev/nvidiactl --device=/dev/nvidia-uvm Enabled hardware acceleration in Plex (Settings → Transcoder → Use hardware acceleration when available). Rebuilt container with proper mappings (/config, /transcode, media libraries). Results: Up to 6 simultaneous streams, including 4K content. Hardware transcoding confirmed via nvidia-smi (GPU memory & Plex Transcoder process active). CPU usage stays between 8–32%, even under load. No playback issues. Both local and remote streaming perform great. Takeaway: The Quadro P2000 is still a beast for Plex! Even paired with an older i5-2500K, you can comfortably transcode 4K video and serve multiple users with ease. Great way to breathe new life into older hardware. Happy streaming!
-
I have had success triggering transcoding using Firefox as the browser (it does not support H.264 files I assume). And its working well. I've not found a way to trigger transcoding otherwise.
-
@MowMdown Thanks again for your posts, got me on the right track. I have one last issue with Transcoding. Plex on Firefox uses the transcoder and it works fantastic. Plex on Chrome seems to prefer to use the CPU - in spite of turning "Use hardware acceleration when available" on in Chrome>Settings (chrome://settings/system). I can't force Video Quality in the Plex Player anymore (unless someone knows how to do that!), so my question is: do you know a way in plex to force chrome to use GPU transcoding vs CPU transcoding?
-
Thanks MowMdown! Not sure how I missed that, but not setting up the KEY in addition to the VALUE was a big part of the problem. Additionally, (and this was a real challenge to figure out) there were a lot of permission issues at play. I ran Newperms on /mnt/cache/appdata/PlexMediaServer, /mnt/user/movies, /mnt/user/tv. The final bit, and this was important was making sure that I used the cache drive watch -n 1 "top -b -n1 | head -n 15; echo; nvidia-smi" With MowMdown's suggestions/observations, I finally got Plex Media Server running (mostly) perfectly on Unraid with hardware-accelerated transcoding using my NVIDIA Quadro P2000. Playback is buttery smooth, even with multiple concurrent 4K streams — here's exactly what I did to make it work, in checklist style for anyone else going down this road. 🧰 Hardware GPU: NVIDIA Quadro P2000 (Pascal, well-supported) Unraid Version: 7.0.0 Container: PlexInc/pms-docker Step-by-Step Setup 🖥️ 1. BIOS Configuration Enabled VT-d (IOMMU) in BIOS Disabled CSM (Compatibility Support Module) if present (not always needed) Enabled Resizable BAR if available (optional for newer GPUs) 🎮 2. Install NVIDIA Driver Plugin Go to Apps tab Install "NVIDIA Driver" plugin Reboot Unraid Confirm GPU is detected with: bash nvidia-smi or look in settings>system devices to find the GPU (important validation hardware is right) 🐳 3. Docker Container Setup (Plexinc) These are the critical Docker Container settings: Docker Container Setup Checklist – Plex with NVIDIA GPU (P2000) 📦 Container Basics Repository: plexinc/pms-docker Registry URL: https://hub.docker.com/r/plexinc/pms-docker Icon URL: https://raw.githubusercontent.com/plexinc/pms-docker/master/img/plex-server.png Network Type: Host Privileged: Off Use Tailscale: Off Console Shell: Shell CPU Pinning: (Optional — as needed) 🧠 GPU Hardware Transcoding Extra Parameters:--runtime=nvidia Devices: (Make sure both name and value are filled in) /dev/nvidia0 /dev/nvidiactl /dev/nvidia-uvm /dev/nvidia-uvm-tools Environment Variables: (Make sure name, key, value and default value are filled in) NVIDIA_VISIBLE_DEVICES: key:NVIDIA_VISIBLE_DEVICES, value=all, default value=all NVIDIA_DRIVER_CAPABILITIES= key:NVIDIA_DRIVER_CAPABILITIES, value=all, default value=all 📂 Volume Mappings Container Path Host Path Purpose /transcode /mnt/cache/appdata/PlexTransCode/ Fast SSD-based transcode folder /config /mnt/cache/appdata/PlexMediaServer/ Plex configuration & metadata storage /movies /mnt/user/movies/ Movie library /tv /mnt/user/tv/ TV Shows library /music /mnt/user/music/ Music library /homemovies /mnt/user/homemovies/ Personal/home movies /pictures /mnt/user/pictures/ Photo library 🔑 Environment Variables Key Value Description PLEX_CLAIM claim-XXXXY5xTiXXXXDE_XXX (example) Optional claim token for linking server PLEX_UID 0 Run as root (Unraid default) PLEX_GID 0 Group ID (Unraid default) VERSION latest Container image tag 🔥 NOTE: Using /mnt/cache/... instead of /mnt/user/... fixed several weird bugs with hardware transcoding. Plex can behave unpredictably with FUSE paths. 🔒 4. Permissions – Set Correct Ownership On appdata and media shares: newperms /mnt/cache/appdata/PlexMediaServer newperms /mnt/user/Movies newperms /mnt/user/TV Ensures proper nobody:users ownership and 775/664 permissions. 🎛️ 5. Plex Settings (Inside Plex Web UI) Settings → Transcoder ✅ Hardware Acceleration = Enabled ✅ Transcoder Directory = /transcode (if set above) ⚠️ Optional: Disable “Use HDR tone mapping” unless needed 🧪 6. Confirming GPU Usage In terminal: watch -n 1 nvidia-smi Look for: Plex Transcoder using 500–700MiB GPU Memory GPU-Util: >30% In Plex>Activity>dashboard: Playback shows: Transcode (Video: H264 (Hardware)) - (See MowMdown's first post above) 💡 Bonus Observations Firefox sessions triggered hardware transcode reliably on 4k videos - useful since you can't control from the Plex Player anymore. Chrome sometimes fell back to CPU transcode due to codec or subtitle rendering - THIS IS STILL AN ISSUE - in Chrome, Plex does CPU transcoding...*sigh* I have to work on that next. Plex ran thumbnails and streams simultaneously without skipping or pegging CPU. HELPFUL: Using watch -n 1 "top -b -n1 | head -n 15; echo; nvidia-smi" let me watch real-time both GPU and Processes at the same time. HELPFUL: I used ChatGPT for a lot of the debugging. You can't believe everything, but it was fantastic at providing options and specific commands to use (like Watch). I'm not a Linux GURU so this aspect of AI was VERY helpful. 🧵 TL;DR Summary ✅ BIOS VT-d on ✅ NVIDIA Driver plugin installed ✅ Docker has NVIDIA_VISIBLE_DEVICES & NVIDIA_DRIVER_CAPABILITIES - Key and Value set! ✅ Mapped to /mnt/cache, not /mnt/user ✅ newperms run on all relevant shares ✅ Confirmed hardware transcode with nvidia-smi + Plex dashboard
-
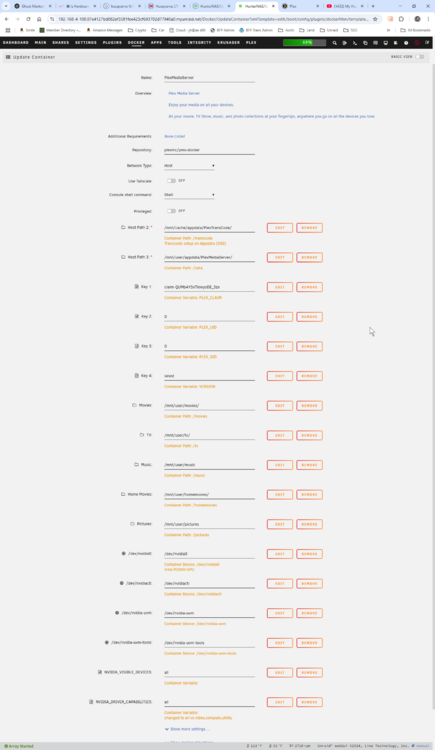
Both are there. Here's the complete Docker config (and screenshot attached). These are all the volume mappings, environment variables, and GPU passthrough settings. 1. PlexMediaServer Docker Configuration (Unraid - plexinc/pms-docker) Setting Value Notes Container Name PlexMediaServer Repository plexinc/pms-docker Official Plex image Network Type Host Privileged Mode Off Console Shell Command Shell Tailscale Off 2. Volume Mappings Host Path Container Path Purpose /mnt/user/appdata/PlexMediaServer/ /data Plex config directory /mnt/cache/appdata/PlexTransCode/ /transcode Transcoder temp directory (SSD) /mnt/user/movies/ /movies Movie library /mnt/user/tv/ /tv TV library /mnt/user/music /music Music library /mnt/user/homemovies/ /homemovies Home videos /mnt/user/pictures /pictures Photo library 3. Environment Variables Variable Value Notes PLEX_CLAIM claim-QUMb4Y5xTiewyoDE_5zx Claim token for initial setup PLEX_UID 0 Runs Plex as root (not ideal) PLEX_GID 0 Same as above VERSION latest Plex version NVIDIA_VISIBLE_DEVICES all Expose all GPUs NVIDIA_DRIVER_CAPABILITIES all Note: typically compute,video,utility recommended 4. GPU Passthrough Devices Host Device Container Device Description /dev/nvidia0 /dev/nvidia0 Quadro P2000 GPU /dev/nvidiactl /dev/nvidiactl NVIDIA Control Interface /dev/nvidia-uvm /dev/nvidia-uvm Unified Video Memory /dev/nvidia-uvm-tools /dev/nvidia-uvm-tools Additional UVM interface Despite all settings appearing correct, GPU hardware transcoding did not function with this configuration, and Plex only showed "Auto" in the Hardware Transcoding Device dropdown. The container lacked NVIDIA runtime libraries internally (nvidia-smi not found).
-
I've been told that the plexinc/pms-docker image does not bundle GPU support libraries by default. Perhaps that is why? Do you know for sure if its included? Is there a way to see if its there?
-
Here's the docker run: Command execution docker run -d --name='PlexMediaServer' --net='host' --pids-limit 2048 -e TZ="America/Chicago" -e HOST_OS="Unraid" -e HOST_HOSTNAME="HunterNAS" -e HOST_CONTAINERNAME="PlexMediaServer" -e 'PLEX_CLAIM'='claim-QUMb4Y5xTiewyoDE_5zx' -e 'PLEX_UID'='0' -e 'PLEX_GID'='0' -e 'VERSION'='latest' -l net.unraid.docker.managed=dockerman -l net.unraid.docker.webui='http://[IP]:[PORT:32400]/web' -l net.unraid.docker.icon='https://raw.githubusercontent.com/plexinc/pms-docker/master/img/plex-server.png' -v '/mnt/cache/appdata/PlexTransCode/':'/transcode':'rw' -v '/mnt/user/appdata/PlexMediaServer/':'/data':'rw' -v '/mnt/user/movies/':'/movies':'rw' -v '/mnt/user/tv/':'/tv':'rw' -v '/mnt/user/music':'/music':'rw' -v '/mnt/user/homemovies/':'/homemovies':'rw' -v '/mnt/user/pictures':'/pictures':'rw' -v '/mnt/user/appdata/PlexMediaServer':'/config':'rw' --device='/dev/nvidia0' --device='/dev/nvidiactl' --device='/dev/nvidia-uvm' --device='/dev/nvidia-uvm-tools' --runtime=nvidia 'plexinc/pms-docker' 74ca07ac98f52c59e5453e3114b926eecf5094d23db512ecd201f1d806c8b29e The command finished successfully!




