




robertoal
Members
-
Joined
-
Last visited
Everything posted by robertoal
-
Internal (if you have a home network) you should use http: enabling https is more hassle. From the internet you want https, for this use the NginxProxyManager docker. (reverse proxy)
-
You sir are a king! Thank you VERY much. It works like a charm! @Abigel If you change the portmapping from standard you have to manually add the port into browser: x.x.x.x:NEW_PORT Or: If you go to edit docker, and turn on advanced view in the top right corner you can change the WebUI text box to: http://[IP]:[PORT:80]/ (change the 80 with the non ssl port, or: https://[IP]:[PORT:443] (change the 443 with the ssl port) This enables the right click go to webui again.
-
Absolutely sure! Can you please advise me on this? I have some bad experiences with changing rights of the nextcloud folder.. The last times I tried stuff like this nextcloud gave me the 'rights' error and after that the internal server error lol. So the rights at this moment are in the docker container: drwxrwx--- 1 www-data root 246 Mar 29 13:31 data From the unraid terminal: drwxrwx--- 1 sshd root 246 Mar 29 13:31 data/ If I get this correctly: the root folder on unraid itself (data in this case) does not inherit the rights given IN the docker container? So: if I add the users: 'nobody' and 'users' which is the same as the other shares: drwxrwxrwx 1 nobody users 0 Mar 14 15:23 SHARE_NAME/ It should work? Or do I need to change the rights in the docker container as well?
-
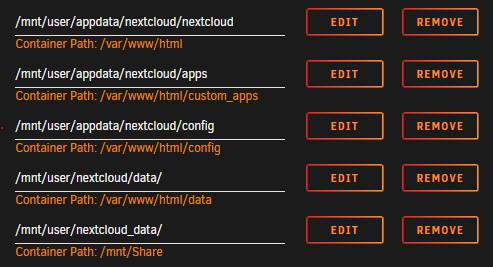
Yes it is x64, and it should work but it doesn't (I did install the apps from the start) no matter now: it works with the external onlyoffice docker. My path are set as follows: I have acces to /mnt/user/nextcloud. (and can create folders/files, so the share is working) I don't have acces to /mnt/user/nextcloud/data -> the error is: I do not have permission to acces the folder.
-
@knex666 I had, as mentioned some time ago, the exact same problem; solved it with an external onlyoffice docker. Reinstalling for me did nothing! Very strange is it not? Have a follow op question: I can't acces the mounted data folder from a windows machine (the mounted folder is a share on the unraid server). I thought this had to do with: ExtraParams: --user 99:100 --sysctl net.ipv4.ip_unprivileged_port_start=0 PostArgs: && docker exec -u 0 NAME_OF_THIS_CONTAINER /bin/sh -c 'echo "umask 000" >> /etc/apache2/envvars' So I added these to the specific textboxes, but no dice unfortanatly. Can you help me debug this problem? I really appreciate the time you invest in this thread!!
-
Hi there, I'm positive i'm running your image! But it just didn't work from the start.. now idea what's going on. But: does work now though. Good idea about mounting the php.ini! will do this. Lastly: now getting talk to work reliably! Thanks for your help.
-
THank you for this quick reply! With me the onlyoffice didn't work out of the box? Which addres should I use in the nextcloud: onlyoffice settings then? Finally: Where can I change the php settings? Memory is limited now to 512... Very much appreciated all the work you put into this!!! edit: I think i found it by: php --ini in the console: /usr/local/etc/php/conf.d/memory-limit.ini Changed it there and seems to work so far!
-
Found out some limitations.. When not using bridge, but an specific IP addres for the docker i get this MariaDB error: Failed to connect to the database: An exception occurred in driver: SQLSTATE[HY000] [2002] No such file or directory Solution: just use bridge ande forwarde the port like stated on the first page, but use port 80 for container port instead of 8080. There seems to be problem to docker to docker communication when using a specific IP addres (any docker to any docker, not just nextcloud) When trying to edit the config.php file from a samba share in windows the file appears to be empty. It isnt: just ssh to the unraid box and edit it there. Question: What is the right port for the internal openoffice installation? I now use an extra docker for this..
-
Did you follow the steps i provided? That should solve your error!
-
Update.. I followed this post: http://networkrockstar.ca/2013/09/speeding-up-crashplan-backups/ And performance increased to 23mbit! for how long we will have to see. Edit: Rock steady 30mbit up!
-
Thanks Squid! I tried to follow the steps noted here: http://support.code42.com/CrashPlan/4/Troubleshooting/Code42_App_Does_Not_Run/Code42_App_Does_Not_Run_On_64-Bit_System Which was linked in the post you mentioned. (Reinstalling CrashPlan) But I get a permission error when running: sudo ./uninstall.sh -i /usr/local/crashplan sudo it does not recognize as a command, but SU does. Still nothing though. Anyone any idea how to get root privelages? @Michel - If I found out... sure!
-
Thanks for this link, trying the solution as we speak. To run a shell in a docker: 1. Open telnet/ssh client and connect to unraid. 2. list dockers with: docker ps 3. Get the corosponding ID of the CrashPlan docker 4. command: docker exec -it DOCKERID bash then run the command as they noted in the link: apt-get update && apt-get install python-xdg This does get rid of the error in the log although mine still crashes. So now following the step a few post further.
-
Reporting an error too: I get the 'unable to connect to the backup engine' error. Clicking on yes restarts the docker and brings up Crashplan. But: upload is extremely slow (max 5 mbit. but most of the time 2,5 mbit. My upload max is 30mbit). Second problem: it does not want to save settings! Dont now if this is related. My CPU (atom D520) does pose something of a bottleneck, but without any dockers running and compression and encryption disabled (manually in XML) it only uses about 50 procent of all 4 cores. So I don;t think this could be the upload limiting factor? Thanks in advance for any help!
-
I would agree but. I triple checked every setting. My settings are: IP: 192.168.2.253 Subnetmask: 255.255.255.0 Gateway 192.168.2.254 (Router..) DNS: 192.168.2.254 (Router..) With DHCP on everything, except off course the ip looks the same? (Ip DHCP > 192.168.2.110) Am I not seeing something here? Thank you for your reply.
-
Same issue here. Got a new modem from isp which has a fixed static ip (can't change it hate when they disable options like that) So I used to be on subnet 192.168.1.xxx Now it is 192.168.2.xxx Static ip will give me a ping to the router, but no world wide web unfortunately.. even after a restart. Will try the dhcp route and lock it with the router but this is crap. Is this a bug in unraid? Or am I (we) doing something wrong? Sent from my A0001 using Tapatalk
