knarf0007
Members
-
Joined
-
Last visited
Everything posted by knarf0007
-
Hi All, the mainboard of my UnRaid Server died today (after 11 years) and I'm currently looking for new components. I want to change mainboard, CPU and RAM only, the case and everything else should remain untouched. My requirements are: Not more than 60-70 W idle with one extra network card (PCIe) and a 8-port SAS (PCIe) card >= 6 SATA ports internal GPU I found the following components that seems to fit to my requirements: Mainboard: ASRock Z690 Extreme Intel Z690 So. 1700 Dual Channel DDR ATX CPU: Intel® Core™ i7-14700T RAM: 64GB Kingston FURY Beast DDR4-3200 DIMM CL16 Dual Kit I honestly ask for your opinion. Thank You very much!!! Best Regards Frank
-
I would also be extremely pleased if someone can create a fitting template for VWsFriend. Thanks!
-
During troubleshooting the unraid-server wasn't connected to the network. After connecting the server to the network, I was totally stunned 8-))))))))) that the GUI is accessible and also usable. Everything looks fine and after replacing the license key, everything is up and running again. I can open a working terminal via SSH. On the local screen I still see this weird screen as shown above and no local terminal. I'm not really sure that everything is fine, but for now, I'm pretty happy!!!
-
I attached the most important parts of the /config folder (removed plugin folders & Key File). Can anyone see something "corrupt"? I don't have another backup of the config 8-(( How difficult is the "recreation" of the config from scratch? Thanks a lot. Frank config_copy.zip
-
I extracted the /config folder from the current USB-Flash drive, created a new flash drive (64GB) and copied the /config to new usb stick. I ended up with a strange kind of error (see the attached picture). I booted with a different UnRaid stick and the server booted correctly. So, it seems that I haven't an hardware issue but an issue with the usb stick and the config data itself. Any idea what to do next? Thanks
-
Hi Everyone, today I experianced a fundamental server crash. After reboot I don't reach the point where I can connect to the server via network. Attached you find a screenshot from the local attached screen. Can you help? What is potentially damaged? Thanks a lot!!! Frank
-
Sorry I have problems to upload the diagnostic file (error: -200)
-
Hi All, this night my zfs-Pool crashed. I had to reboot the server and now the pool can't be mounted (Unmountable: Unsupported or no file system. I attach the diags. May be someone can help. If I try to import the pool from the command line, I get the following result: root@UnRaid-Server:/# zpool import cache_docker_vm cannot import 'cache_docker_vm': I/O error Destroy and re-create the pool from a backup source. I get same result, if I try to import read only: root@UnRaid-Server:~# zpool import -o readonly=on cache_docker_vm cannot import 'cache_docker_vm': I/O error Destroy and re-create the pool from a backup source. What can I do, to at least safe the data? Thanks in advance. Frank unraid-server-diagnostics-20231008-0802.zip
-
Sorry Guys, during the "New Config" procedure a lot of other settings were changed to default values. So did the setting to pause the parity run on some temperature levels. I set the value for "Pause and resume array operations if disks overheat" to no and it seems to work now.
-
I made a mem-test with works out fine. I changed to two new SSDs. Until now, no further problems. I confess, I downgraded from 6.11.0 to 6.10.3.
-
Hi All, I shrinked my array (removed 3 disks) using the "New Configuration" method. In principle all works fine, but the current parity run pauses every few minutes with the error messages, that a few drives are overheated, which they are not (my first alert temperature is 45°C). But anyway I can't remember that a parity run ever stops because of an overheated disk. Any idea? Thanks a lot. Greetings Frank unraid-server-diagnostics-20221008-1016.zip
-
No, I didn't perform any memtests.
-
here some additional information: root@UnRaid-Server:/mnt# btrfs dev stats /mnt/cache_docker_vm [/dev/mapper/sdi1].write_io_errs 0 [/dev/mapper/sdi1].read_io_errs 0 [/dev/mapper/sdi1].flush_io_errs 0 [/dev/mapper/sdi1].corruption_errs 0 [/dev/mapper/sdi1].generation_errs 0 [/dev/mapper/sde1].write_io_errs 0 [/dev/mapper/sde1].read_io_errs 0 [/dev/mapper/sde1].flush_io_errs 0 [/dev/mapper/sde1].corruption_errs 0 [/dev/mapper/sde1].generation_errs 0 root@UnRaid-Server:/mnt# btrfs dev stats /mnt/cache [/dev/mapper/sdj1].write_io_errs 0 [/dev/mapper/sdj1].read_io_errs 0 [/dev/mapper/sdj1].flush_io_errs 0 [/dev/mapper/sdj1].corruption_errs 1298 [/dev/mapper/sdj1].generation_errs 0 [/dev/mapper/sdk1].write_io_errs 0 [/dev/mapper/sdk1].read_io_errs 0 [/dev/mapper/sdk1].flush_io_errs 0 [/dev/mapper/sdk1].corruption_errs 1010 [/dev/mapper/sdk1].generation_errs 0
-
Hi All, It seems that I have a problem with one of my SSDs. What should be the next steps? Thanks. Frank. unraid-server-diagnostics-20220926-1850.zip
-
+1 => 1.) api unraid + all plugins 2.) api VMs 3.)api dockers
-
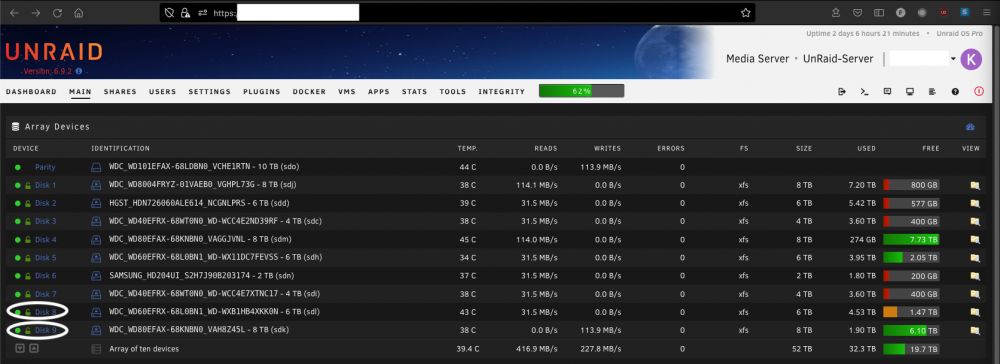
Hi All, currently I'm copying all data from one drive (disk 8 ) to another empty drive (disk 9 ) using unBALANCE. The copy process itself works absolutely fine. What I dont't understand is the fact das all other drives have read activity at the same time. I tried it many times and the read transactions are directely corellated to the use of unBALANCE. I would have expected that I see activity on disk 8, disk 9 and the parity drive only. Do anybody know why that is happend? During a long copy process this behaviour is not desired because all the spinned up drives need a lot of electric power. Thanks in advance. Best Regards, Frank
-
Hi All, sorry I'm back. Something is still wrong. Everytime I try to copy all the data from my docker ssd I get error messages and the copy process stops. I changed the controller for the SSDs (now all on the internal intel controller). But still I get these strange error messages (11:30am). Why I want to copy all data from the Docker SSD? Because I have two single SSDs, one for all Dockers and one for all VMs. I want to create a Cache Pools instead (for redundency reasons) an run dockers an VMs from this Pool. Any Idea? Thanks! Best regards Frank unraid-server-diagnostics-20220213-1145.zip
-
Hi, the rebuild on an other spare disc is now running. So far erverthing works fine. During the drive swap, I checked all cable connections, maybe there was a small error there. Additionally - to be on the safe side - I ordered one of the recommanded LSI SAS Contoller. However, I doubt that the old controller type has a fundamental problem, because it has been working absolutely flawlessly for years, with hard drives and SSDs. But anyway, if I can further reduce the risk of failure of my "beloved" UnRaid server with a controller change, then I'm happy to do so. 😉 Best Regards Frank
-
Sorry, ignore the question how to revive disc 9, I found the procedure. But is it wise to start a rebuild as long I'm not sure, that erverything with the conroller is o.k?
-
I have 4 SSDs in my setup. I switched all of them to the onboard intel SATA Controller. Everything looks fine for the moment. Nevertheless I find these kind of messages in the log. xfs_inode block 0xe91a8fb0 xfs_inode_buf_verify Feb 10 21:28:31 UnRaid-Server kernel: XFS (dm-6): Unmount and run xfs_repair Feb 10 21:28:31 UnRaid-Server kernel: XFS (dm-6): First 128 bytes of corrupted metadata buffer: Feb 10 21:28:31 UnRaid-Server kernel: 00000000: dd ec fd 51 64 2e 70 e1 bd 28 2c 85 d6 fb eb 4c ...Qd.p..(,....L Feb 10 21:28:31 UnRaid-Server kernel: 00000010: 2e 67 21 fe 25 1e 69 f8 ed d0 e2 7c fa 6f 55 ce .g!.%.i....|.oU. Feb 10 21:28:31 UnRaid-Server kernel: 00000020: af ea 17 e8 de eb 9b f1 a1 e6 36 91 25 58 2f 7b ..........6.%X/{ Feb 10 21:28:31 UnRaid-Server kernel: 00000030: 02 5e 02 e4 f8 82 17 3d 2d 3c 6d d6 c5 0e 0c 31 .^.....=-<m....1 Feb 10 21:28:31 UnRaid-Server kernel: 00000040: db 77 59 bb 85 75 f3 81 fe 75 bd 9c fb 2f b8 55 .wY..u...u.../.U Feb 10 21:28:31 UnRaid-Server kernel: 00000050: b9 07 a0 e4 32 7c 77 aa b4 a8 25 24 68 19 9c 6d ....2|w...%$h..m Feb 10 21:28:31 UnRaid-Server kernel: 00000060: 55 79 86 07 a2 49 ff fd 6c d0 87 57 d1 6b 79 61 Uy...I..l..W.kya Feb 10 21:28:31 UnRaid-Server kernel: 00000070: 1b f3 23 a3 b0 0d 1f 4b e7 d6 8f 9a be b2 a8 bd ..#....K........ Feb 10 21:28:31 UnRaid-Server kernel: XFS (dm-6): Metadata corruption detected at xfs_buf_ioend+0x51/0x284 [xfs], xfs_inode block 0xe91a8fb0 xfs_inode_buf_verify Feb 10 21:28:31 UnRaid-Server kernel: XFS (dm-6): Unmount and run xfs_repair Feb 10 21:28:31 UnRaid-Server kernel: XFS (dm-6): First 128 bytes of corrupted metadata buffer: Feb 10 21:28:31 UnRaid-Server kernel: 00000000: dd ec fd 51 64 2e 70 e1 bd 28 2c 85 d6 fb eb 4c ...Qd.p..(,....L Feb 10 21:28:31 UnRaid-Server kernel: 00000010: 2e 67 21 fe 25 1e 69 f8 ed d0 e2 7c fa 6f 55 ce .g!.%.i....|.oU. Feb 10 21:28:31 UnRaid-Server kernel: 00000020: af ea 17 e8 de eb 9b f1 a1 e6 36 91 25 58 2f 7b ..........6.%X/{ Feb 10 21:28:31 UnRaid-Server kernel: 00000030: 02 5e 02 e4 f8 82 17 3d 2d 3c 6d d6 c5 0e 0c 31 .^.....=-<m....1 Feb 10 21:28:31 UnRaid-Server kernel: 00000040: db 77 59 bb 85 75 f3 81 fe 75 bd 9c fb 2f b8 55 .wY..u...u.../.U Feb 10 21:28:31 UnRaid-Server kernel: 00000050: b9 07 a0 e4 32 7c 77 aa b4 a8 25 24 68 19 9c 6d ....2|w...%$h..m Feb 10 21:28:31 UnRaid-Server kernel: 00000060: 55 79 86 07 a2 49 ff fd 6c d0 87 57 d1 6b 79 61 Uy...I..l..W.kya Feb 10 21:28:31 UnRaid-Server kernel: 00000070: 1b f3 23 a3 b0 0d 1f 4b e7 d6 8f 9a be b2 a8 bd ..#....K........ Feb 10 21:28:31 UnRaid-Server kernel: XFS (dm-6): Metadata corruption detected at xfs_buf_ioend+0x51/0x284 [xfs], xfs_inode block 0xe91a8fb0 xfs_inode_buf_verify Feb 10 21:28:31 UnRaid-Server kernel: XFS (dm-6): Unmount and run xfs_repair Feb 10 21:28:31 UnRaid-Server kernel: XFS (dm-6): First 128 bytes of corrupted metadata buffer: Feb 10 21:28:31 UnRaid-Server kernel: 00000000: dd ec fd 51 64 2e 70 e1 bd 28 2c 85 d6 fb eb 4c ...Qd.p..(,....L Feb 10 21:28:31 UnRaid-Server kernel: 00000010: 2e 67 21 fe 25 1e 69 f8 ed d0 e2 7c fa 6f 55 ce .g!.%.i....|.oU. Feb 10 21:28:31 UnRaid-Server kernel: 00000020: af ea 17 e8 de eb 9b f1 a1 e6 36 91 25 58 2f 7b ..........6.%X/{ Feb 10 21:28:31 UnRaid-Server kernel: 00000030: 02 5e 02 e4 f8 82 17 3d 2d 3c 6d d6 c5 0e 0c 31 .^.....=-<m....1 Feb 10 21:28:31 UnRaid-Server kernel: 00000040: db 77 59 bb 85 75 f3 81 fe 75 bd 9c fb 2f b8 55 .wY..u...u.../.U Feb 10 21:28:31 UnRaid-Server kernel: 00000050: b9 07 a0 e4 32 7c 77 aa b4 a8 25 24 68 19 9c 6d ....2|w...%$h..m Feb 10 21:28:31 UnRaid-Server kernel: 00000060: 55 79 86 07 a2 49 ff fd 6c d0 87 57 d1 6b 79 61 Uy...I..l..W.kya Feb 10 21:28:31 UnRaid-Server kernel: 00000070: 1b f3 23 a3 b0 0d 1f 4b e7 d6 8f 9a be b2 a8 bd ..#....K........ I can't see which disc has the problem. Should I stop the array and run a xfs_repair? And what is the way to revive disc 9? Thanks a lot!!! Frank. unraid-server-diagnostics-20220210-2136.zip
-
Hi All, it's getting worse. My attempt to copy some data from my cache_VM drive to a data-disc using the mover ended in a lot of write errors on the data-disc which is now disabled. Is it possible that my 8port SATA extension card is somehow damaged? As a precaution, I stopped the array. Im afraid that I could really loose data now. Best regards Frank unraid-server-diagnostics-20220210-1947.zip
-
Hi All, I have a single Cache SSD drive in my UnRaid setting where all my Docker Applications are running. In the last couple of month ramdomly sector relacations on this drive took place. Last night I tried to transfer all data to a "classical" data disc to save the data. The Mover transfered the data partially and then ended with some error messages: Feb 9 08:40:09 UnRaid-Server kernel: sd 7:0:2:0: [sdj] tag#195 UNKNOWN(0x2003) Result: hostbyte=0x04 driverbyte=0x00 cmd_age=0s Feb 9 08:40:09 UnRaid-Server kernel: sd 7:0:2:0: [sdj] tag#195 CDB: opcode=0x28 28 00 03 25 e7 a0 00 00 20 00 Feb 9 08:40:09 UnRaid-Server kernel: blk_update_request: I/O error, dev sdj, sector 52815776 op 0x0:(READ) flags 0x1000 phys_seg 4 prio class 0 Feb 9 08:40:09 UnRaid-Server kernel: BTRFS error (device dm-11): bdev /dev/mapper/sdj1 errs: wr 37, rd 260090, flush 0, corrupt 0, gen 0 I'm having problem to interpret these errors. Can you help? Thank you very much! Best regards Frank unraid-server-diagnostics-20220209-0854.zip
-
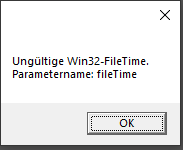
Hi All, I have a problem when I try to access my personel banking data (on an Unraid-Share) with my banking application running on a windows VM. I get the following error message (see picture below). Sorry it's in German, it means that the file don't have a valid Win32-FileTime (parameter name: filetime). If I copy the file from the Unraid share to the VM-Filesystem an back, then I can access the file without any problems. If I save the file again on the Unraid share, the problem is back. The only thing that I changed in the last weeks, is to activate the SMB Settings paramenter "Enhanced macOS interoperability". Any ideas? Thank You! Frank. PS: I checked system time on Unraid and the VM. There are identical.