




growlith
Members
-
Joined
-
Last visited
Everything posted by growlith
-
Sounds good to me! Feel free to use anything that I have written, although it's not great python code. I think the useful parts are figuring out what Steam API endpoint to use to check against as well as how to manage other containers from a container.
-
@Cyd Thanks for the help with -automanagedmods the other day. For anyone running a modded Ark server/cluster, I have created a companion container to run alongside and automate the whole checking if mods update and triggering resets. It scans a given mounted /mods folder and queries Steam API to see if a mod has updated. If one has, it broadcasts warnings in the servers and then restarts them. If you have a cluster, it will restart the primary (server setup with -automanagedmods) server and stop all of the others. Once that server has updated your mods and is running, it will start back up the other ones that were running (leaving stopped ones untouched). Feel free to use it. integrate the concept, or modify it however you want. https://github.com/jalbertcory/ArkDockerModUpdater
-
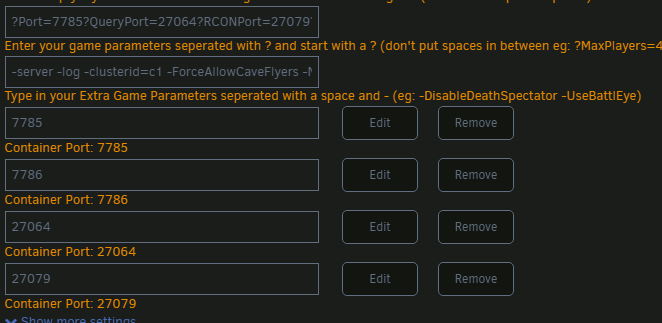
You need to make sure that you tell Ark what ports you are using eg. `?Port=7785?QueryPort=27064` and it's not just that you need to remove and re-add them, the port inside the container needs to be the same port exposed externally. This is because ARK reports it's ports back to steam and you can't change the container port without adding a new port mapping. So from a fresh setup, you should remove the query port and add a 27016<>27016 mapping. In addition, there is no command line argument for the second UDP port (following 7777), it's always the first UDP port +1. So when you tell Ark ?Port=7785 you are also saying UDP2 port is 7786. Then ?QueryPort=27064 is obvious what it does. If you want RCON (do you need this?), then there is more you have to do such as adding ?RCONPort=27075?RCONEnabled=True?ServerAdminPassword=<yourpass> to the commandline.
-
There are probably some template XML changes as well right? This would only add the modIds to the game params. I imagine there is a volume mapping needed to double mount the streamcmd so that Ark can find it in it's expected locations. If you tell me what mappings you use, I can double check that things work if that helps.
-
I have verified that I placed this flag into Extra Game Parameters. I went ahead and captured the output from when I edit the Docker: root@localhost:# /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name='ARK-TheIsland' --net='bridge' -e TZ="America/Chicago" -e HOST_OS="Unraid" -e 'GAME_ID'='376030' -e 'USERNAME'='' -e 'VALIDATE'='' -e 'PASSWRD'='' -e 'MAP'='TheIsland' -e 'SERVER_NAME'='Call-The-Island' -e 'SRV_PWD'='' -e 'SRV_ADMIN_PWD'='ARKAdmin' -e 'GAME_PARAMS'='?Port=7777 ?QueryPort=27015 ?RCONEnabled=True ?RCONPort=27016 ?bAllowUnlimitedRespecs=true ?FastDecayUnsnappedCoreStructures=true' -e 'GAME_PARAMS_EXTRA'='-server -log -exclusivejoin -automanagedmods -NoBattlEye -clusterid=call1 -ClusterDirOverride=/serverdata/clusterfiles' -e 'UID'='99' -e 'GID'='100' -p '7777:7777/udp' -p '7778:7778/udp' -p '27015:27015/udp' -p '27016:27016/tcp' -v '/mnt/user/appdata/steamcmd':'/serverdata/steamcmd':'rw' -v '/mnt/user/appdata/ark-se/island':'/serverdata/serverfiles':'rw' -v '/mnt/usr/appdata/ark-se/cluster':'/serverdata/clusterfiles':'rw' --restart=unless-stopped 'ich777/steamcmd:arkse' 30e4fd7cbd207015fc8a7ac69096a52b41cd6befba92f8fe5c4ba03e2a84b864 Whenever I include the -automanagedmods flag, I get this error looping in my log until I stop the Docker image. Removing only the -automanagedmods flag allows the server to start and run as expected, except it does not check/update the installed mods. I am having the same issue with the -automanagedmods flag. Seg fault upon starting the server. I do not have any spaces in my game parameter string. Any ideas of things that I might try? This is what my start command looks like from Unraid. /usr/local/emhttp/plugins/dynamix.docker.manager/scripts/docker run -d --name='ARKSurvivalEvolved' --net='bridge' -e TZ="America/New_York" -e HOST_OS="Unraid" -e 'GAME_ID'='376030' -e 'USERNAME'='' -e 'VALIDATE'='' -e 'PASSWRD'='' -e 'MAP'='Ragnarok' -e 'SERVER_NAME'='rag' -e 'SRV_PWD'='somepassword' -e 'SRV_ADMIN_PWD'='otherpassword' -e 'GAME_PARAMS'='?AllowFlyerCarryPvE=true?AllowFlyingStaminaRecovery=true?AllowCaveBuildingPVE=true?OverrideOfficialDifficulty=5.0?ForceAllowCaveFlyers=true?AllowAnyoneBabyImprintCuddle=true' -e 'GAME_PARAMS_EXTRA'='-automanagedmods -server -log' -e 'UID'='99' -e 'GID'='100' -p '7777:7777/udp' -p '7778:7778/udp' -p '27015:27015/udp' -p '27020:27020/tcp' -v '/mnt/user/appdata/steamcmd':'/serverdata/steamcmd':'rw' -v '/mnt/cache/appdata/ark-se':'/serverdata/serverfiles':'rw' --restart=unless-stopped 'ich777/steamcmd:arkse'
-
This is broken for me as well. The container seems to run for a few hours fine, then it thrashes in a boot loop taking tons of cpu with the constant restarting. I believe it's an issue with the application itself.
-
Were you able to get this to work with Google DNS? I have 25 subdomains and a wildcard cert seems like it would make more sense at this point. I get to the acme-challenge step and it says that it cannot find a text record. I setup the service account, the dns api, the managed zone. Not sure what I am missing.
-
I am also having the same problem with this plugin (invalid argument). For now I just upgraded my ram to take care of hitting the old cap occasionally.


