




whwunraid
Members
-
Joined
-
Last visited
-
One server for backup and one for media server, VMs & various applications.
-
The update to 7.1.3 fixed my issue -- thanks to all!!
-
The docker.img file currently has a modified date of 05/23/25... I've had this install of Emby since about 9/2021.
-
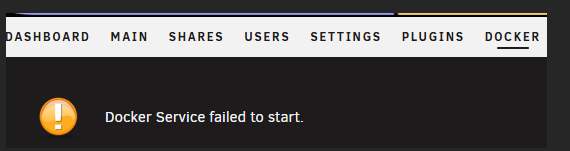
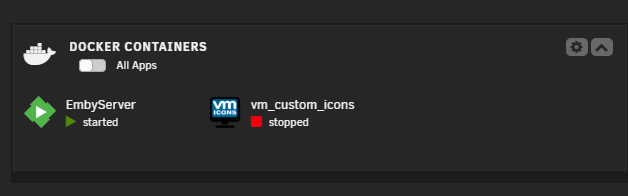
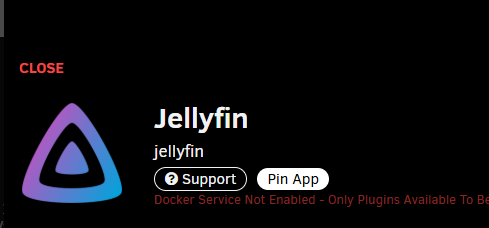
Here is the Docker Tab (service not running): Dashboard (Emby container running): App installer (no Install button):
-
root@Helios:~# docker info Client: Version: 27.5.1 Context: default Debug Mode: false Plugins: buildx: Docker Buildx (Docker Inc.) Version: v0.20.1 Path: /usr/libexec/docker/cli-plugins/docker-buildx Server: Containers: 2 Running: 1 Paused: 0 Stopped: 1 Images: 3 Server Version: 27.5.1 Storage Driver: btrfs Btrfs: Logging Driver: json-file Cgroup Driver: cgroupfs Cgroup Version: 2 Plugins: Volume: local Network: bridge host ipvlan macvlan null overlay Log: awslogs fluentd gcplogs gelf journald json-file local splunk syslog Swarm: inactive Runtimes: io.containerd.runc.v2 nvidia runc Default Runtime: runc Init Binary: docker-init containerd version: bcc810d6b9066471b0b6fa75f557a15a1cbf31bb runc version: v1.2.4-0-g6c52b3f init version: de40ad0 Security Options: seccomp Profile: builtin cgroupns Kernel Version: 6.12.24-Unraid Operating System: Unraid OS 7.1 x86_64 OSType: linux Architecture: x86_64 CPUs: 24 Total Memory: 62.73GiB Name: Helios ID: 97e824be-2dd6-4cf1-a2e6-aab87bd1c721 Docker Root Dir: /var/lib/docker Debug Mode: false Experimental: false Insecure Registries: 127.0.0.0/8 Live Restore Enabled: false Product License: Community Engine WARNING: No swap limit support
-
Here ya go, I pulled in the unzipped folder by mistake. helios-diagnostics-20250517-1433.zip
-
Update: went to install a docker image and the installs are disabled.
-
Hey All - I updated to 7.1.2 (from 7.0) and now unRaid reports (in the Docker Tab) that the Docker Service did not start... but it did, the one container I have in there (Emby) runs just as it aways did. Attached diagnostics, but this seems more of a bug than an issue...? Let me know what ya think, Thanks
-
Yes I got familiar with the route command and used it to set br0 and ip as the default route. Thanks for the input!
-
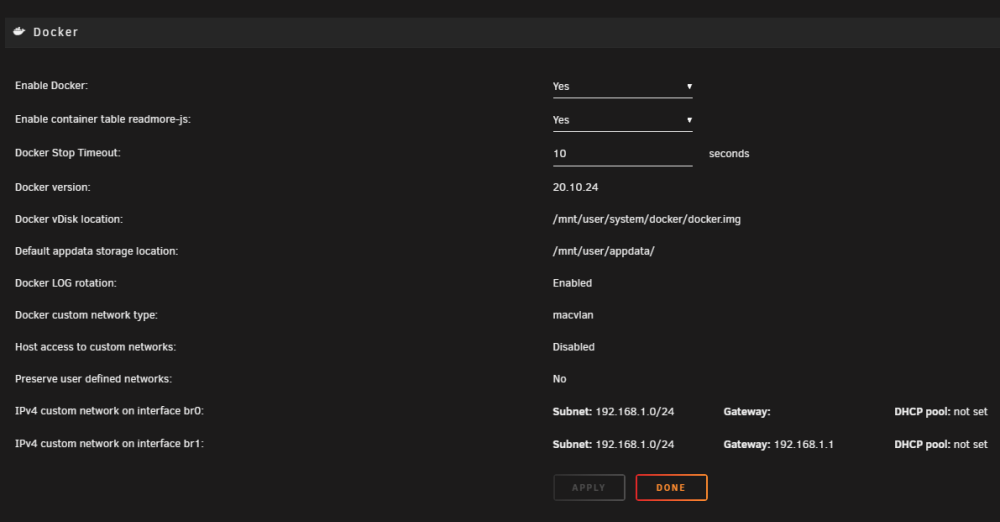
I Installed a 10G ethernet card in my server and have it up and running. I can get to docker web GUIs via internal network as usual, VM can get on internet and resolve DNS names to address. Dockers are not able to resolve DNS apparently now as both Emby and Calibre are throwing connection errors to external hosts. I have disabled the original 1G nic in Network Settings (or so I thought, see pic). Log is showing an error of "Tower root: Fix Common Problems: Error: Multiple NICs on the same IPv4 network". Did not think something like this would be an issue if one is disabled? On the Docker settings page the new br0: is not showing a Gateway address, not sure how to rectify this. See attached screen shots... thanks in advance for your assistance.
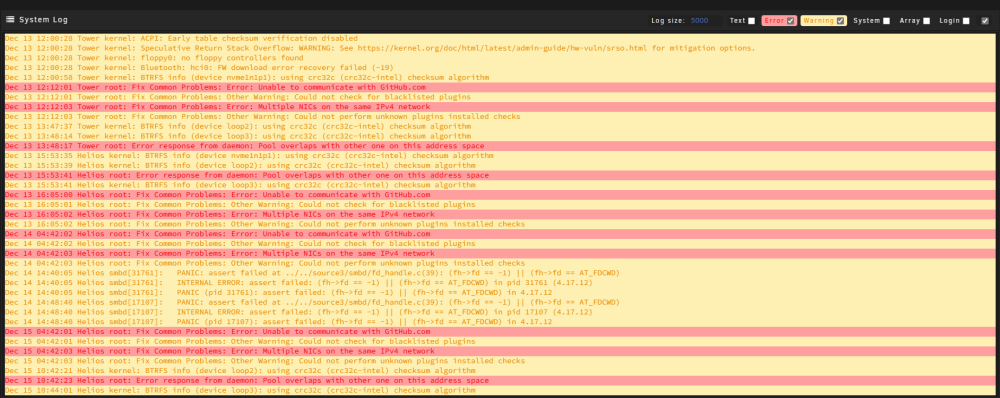
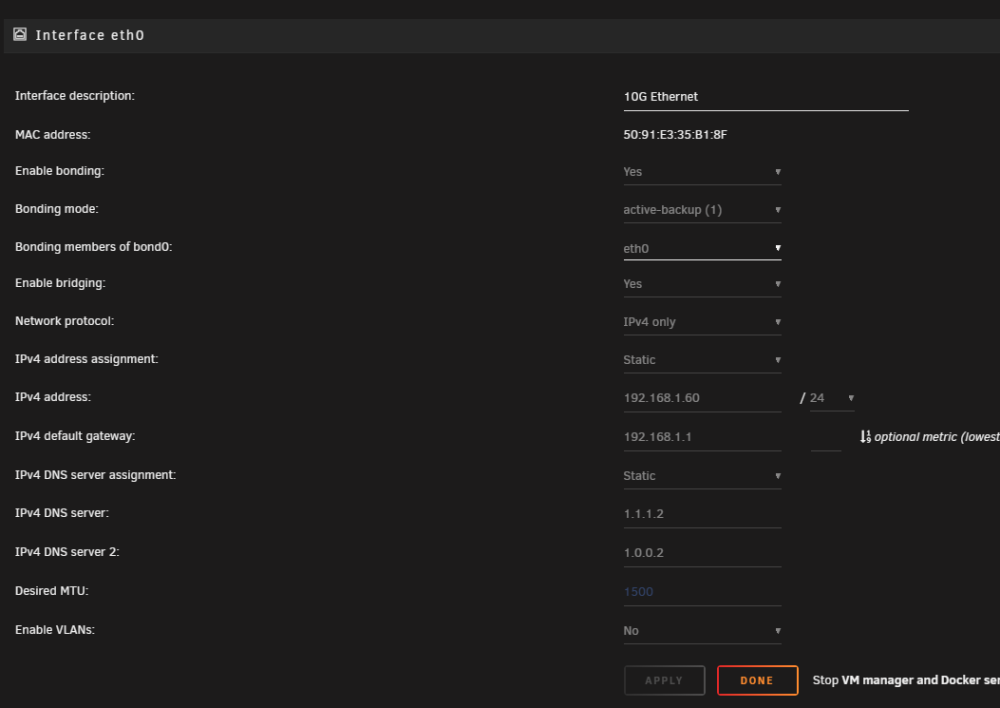
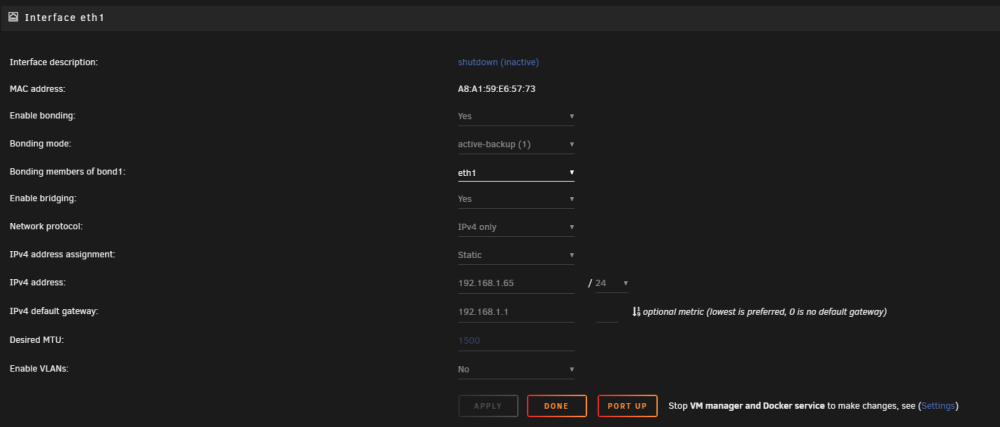
-
OK it was me, I did not complete all the items in Config Tab... LOL. TY for the help.
-
Will try both later today... TY
-
Yes I have used "force scan" 3x and have the same issue. It does spin up the drives and do the scan as it should. The drop downs just do not function. I am using Edge browser and have tried in std mode and private mode, makes no difference.
-
Hello just installed the app and trying to configure, when I choose the TRAYID drop down in the TRAY ALLOCATIONS tab there are no numbers to choose from nor can I type one in. I do have an add-blocker installed but it is turned off for my unRaid server IP address. Any help would be appreciated.
-
This would seem simple enough to get around from an OS level if someone wanted to take the time to set it up. Maybe a feature request as I am sure this wastes serious amounts of time for many of our users. Thanks for your help... PS... The documentation for unRaid would be way more helpful with information like this in the appropriate sections. Making the assumption that the documentation makes itself fully transparent to users unfamiliar with the low level details of how a system operates is short sighted. Also might make less traffic on the forums. 😉








