




scud133b
Members
-
Joined
-
Last visited
-
Writing in here to confirm that this finished successfully! After 7.0 came out, I began the process using a tedious combination of CLI and Unraid GUI to make this work. In short, you have to: Create the RaidZ pool in the CLI in order to use the degraded method, as described in the OP. After everything is created, data is copied and confirmed safely, then you export the pool from the CLI to make it available for the Unraid GUI. Create a new pool in the Unraid GUI, assign all the disks to this pool, and then confirm that your pool file system is auto. This will cause it pick up the existing ZFS pool you created earlier (and not try to make a new file system). Kudos to @JorgeB for that guidance. If you decide to drop your array entirely in Unraid 7, then you'll have to make sure the Array section is empty of drives and execute a New Config in the Tools menu to be able to fully start Unraid again. Most likely the user share mover settings will be all messed up after doing this. I had to go one-by-one through each Share and re-assign them to the new ZFS pool. I also made them exclusive shares pointing to the ZFS pool, which will help the ZFS pool performance substantially by bypassing FUSE.
-
@SpaceInvaderOne any chance you have a video planned for migrating from the array to a ZFS pool for Unraid 7? I've already watched your videos on changing to ZFS within the array but with Unraid 7 coming out, I suspect there will be other people who want to move off the array completely.
-
**NOTE: THIS PLAN OPERATES IN DEGRADED AND UNPROTECTED STATES. I HAVE MULTIPLE BACKUPS AND I AM COMFORTABLE TAKING THIS RISK. DON'T JUST BLINDLY FOLLOW THIS APPROACH IF YOUR SITUATION IS DIFFERENT.** Thanks to some Black Friday deals and in anticipation of Unraid 7, I picked up some more hard drives to be ready to migrate my array to a ZFS pool. I'm doing this for better performance and better data protection versus XFS and FUSE, and to get full ZFS functionality we have to use a separate pool and not the Unraid array. Current config: 3 disks in Unraid Array (1 parity + 2 data) Future config: 6 disks in RaidZ2 pool (2 protection + 4 data) THE PLAN Inspired by: [zfs-discuss] Can I create ZPOOL with missing disks? and Creating a degraded pool and Setting up new 4 disks RAIDz1 pool; build degraded Create RaidZ2 ZFS pool with four real drives and two fake drives (guide here: Setting up new 4 disks RAIDz1 pool; build degraded) 1. Pull parity drive from Array. Unraid Array is now degraded. 2. Create two sparse file "fake drives" to make ZFS think it has six disks available. These will later be replaced by the real disks from the Array. 3. Create a six-disk RaidZ2 pool using the four real disks (three new disks plus the parity we pulled) and the two fake disks. Copy data from Array to ZFS Pool 4. Offline and delete the two "fake" sparse drives so they don't interfere with our data transfer. ZFS pool is now degraded but still operational. 5. Copy the data from the Array (Disk B and Disk C) to the ZFS pool. 6. Scrub ZFS pool to confirm no errors. Restore ZFS Pool to full operation 6. Remove Disk B and Disk C from Unraid Array. 7. Use ZFS replace to switch the two fake drives with the two real drives. 8. Allow ZFS to resilver / repair until it returns to normal status. QUESTION: aside from the obvious lack of protection due to the degraded state, are there any other considerations here? Do these steps make sense? Am I missing something?
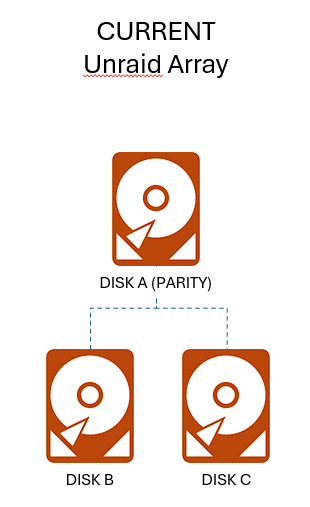
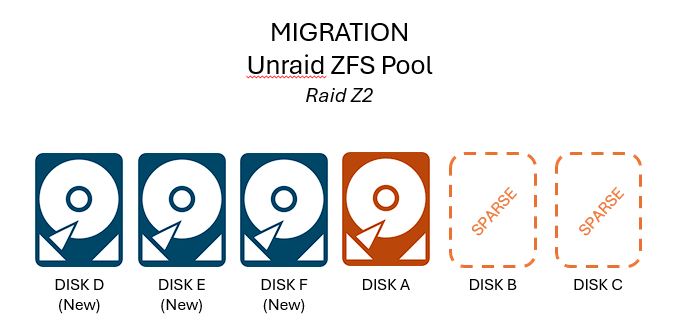
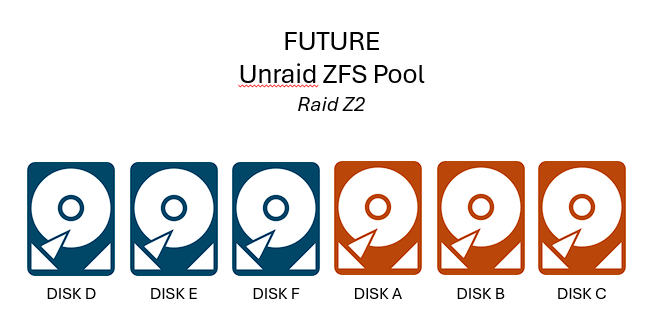
-
Confirming that this worked for me with a Smart-UPS X 1500. At some point in the past I updated it to firmware UPS 15.0 (ID20) -- not sure if that's relevant.
-
Oh yes but unless it's automatic, it's not happening! My last manual backup was in 2020
-
Failed on reboot. Pulled the drive and ran diskcheck on a windows machine. Windows showed errors as soon as I plugged it in. Let the checker run and it seemed to clear it up. Drive is back in the server and we just booted successfully. So hopefully that's it! But I will be using the My Servers auto backup now in case this drive does give out.
-
Got the dreaded message today 🤕 Is it safe for me to try a reboot? I noticed the wiki also suggests pulling the drive and running a disk check on a PC. Diagnostics attached. Edit 2: I also have the following error with my logs maxed out (??): Fatal error: Allowed memory size of 134217728 bytes exhausted (tried to allocate 2097160 bytes) in /usr/local/emhttp/plugins/dynamix/include/Syslog.php on line 18 Edit: Last manual backup I have is from 2020 and here's what I see in My Servers: citadel-diagnostics-20230323-2107.zip
-
REDIS_PASSWORD has been added in the latest update. I believe you'll have to manually add the environment variable in Unraid at the moment, but the app supports it now.
-
PR created because I have the same need
-
So it appears that formatting to remove type 1 protection wasn't enough -- but also changing to 4K sectors appears to have made it work. Not sure if they are both necessary in any particular order but it wasn't until the 4K change that I was able to see the full size of the drive. Now it is assigned in Unraid and rebuilding parity. The thread linked in the previous post does have a lot more detail about this whole process, but in summary it appears you can prep these specific Oracle/Sun HGST drives for use with Unraid using the sg_format commands together: sg_format --format --fmtpinfo=0 --size=4096 /dev/sXX --format will erase the entire disk --fmtpinfo=0 will remove Type 1 Protection --size=4096 will set sector size to 4K (instead of 512 or 520) [NOTE: your disk needs to physically support this change; an older drive might not] /dev/sXX should be changed to your drive's device name
-
So I ran sg_format as indicated in that post, for my device at /dev/sdb: sg_format --format --fmtpinfo=0 /dev/sdb Completed, here is the detail showing protection is set to 0: root@citadel:~# sg_format /dev/sdb HGST H7280A520SUN8.0T PD51 peripheral_type: disk [0x0] << supports protection information>> Unit serial number: 001551P1RTYV 2EK1RTYV LU name: 5000cca23bac41f4 Mode Sense (block descriptor) data, prior to changes: <<< longlba flag set (64 bit lba) >>> Number of blocks=15362376264 [0x393ab4248] Block size=512 [0x200] Read Capacity (16) results: Protection: prot_en=0, p_type=0, p_i_exponent=0 Logical block provisioning: lbpme=0, lbprz=0 Logical blocks per physical block exponent=3 Lowest aligned logical block address=0 Number of logical blocks=15362376264 Logical block size=512 bytes No changes made. To format use '--format'. To resize use '--resize' It completed this evening and the device is still showing as only 7.9 TB instead of 8.0 TB. Now I'm worried that because this is a Sun white-labeled drive, maybe it has some proprietary stuff on it that prevents it from having access to the full 8 TB or something. Any other ideas to try? EDIT: I came across this thread: https://forums.serverbuilds.net/t/fixing-sun-oracle-hgst-8tb-drives-reporting-7-86tb/7018 which suggests to reformat the drive with 4k block size instead of 512. Apparently it's a common issue for these Orace/Sun white-labeled drives. So tonight I'm going to kick off the 4k block size reformat and will report back tomorrow: sg_format --format --size=4096 /dev/sXX
-
Thanks, in progress now. I'll report back with results.
-
Diagnostics attached. I have attempted a full power cycle so unfortunately this won't show us what happened right after the preclear operation. citadel-diagnostics-20211218-1407.zip
-
It's a SAS drive so not shucked. When I try to run that command for HPA: hdparm -N /dev/sdb I get this result: /dev/sdb: SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 34 00 0a 00 00 00 00 00 00 00 00 00 00 01 0a 00 00 00 00 00 00 00 00 00 00 I noticed running this command on other drives does show HPA is enabled, although they all report bad/missing sense data (maybe b/c SAS?)
-
Just ran a full preclear cycle on a replacement disk (HGST He8 SAS 8TB - SUN branded) and it is showing in the GUI as 7.9 TB capacity instead of 8 TB. Of course, that means this new disk can't be a direct replacement for the old disk because Unraid thinks it is too small. It's the same model of disk and the same rated size as the drive it replaces. Anything I can do to rescan or clear that disk (or something else) to make sure Unraid sees the full capacity?






