scud133b
Members
-
Joined
-
Last visited
Everything posted by scud133b
-
Writing in here to confirm that this finished successfully! After 7.0 came out, I began the process using a tedious combination of CLI and Unraid GUI to make this work. In short, you have to: Create the RaidZ pool in the CLI in order to use the degraded method, as described in the OP. After everything is created, data is copied and confirmed safely, then you export the pool from the CLI to make it available for the Unraid GUI. Create a new pool in the Unraid GUI, assign all the disks to this pool, and then confirm that your pool file system is auto. This will cause it pick up the existing ZFS pool you created earlier (and not try to make a new file system). Kudos to @JorgeB for that guidance. If you decide to drop your array entirely in Unraid 7, then you'll have to make sure the Array section is empty of drives and execute a New Config in the Tools menu to be able to fully start Unraid again. Most likely the user share mover settings will be all messed up after doing this. I had to go one-by-one through each Share and re-assign them to the new ZFS pool. I also made them exclusive shares pointing to the ZFS pool, which will help the ZFS pool performance substantially by bypassing FUSE.
-
@SpaceInvaderOne any chance you have a video planned for migrating from the array to a ZFS pool for Unraid 7? I've already watched your videos on changing to ZFS within the array but with Unraid 7 coming out, I suspect there will be other people who want to move off the array completely.
-
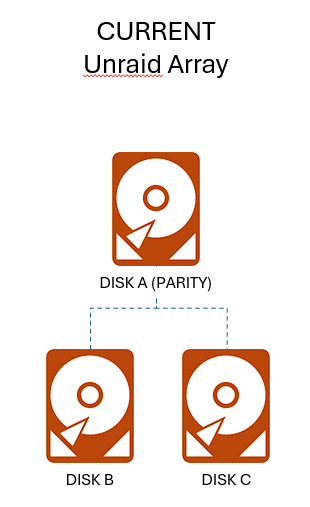
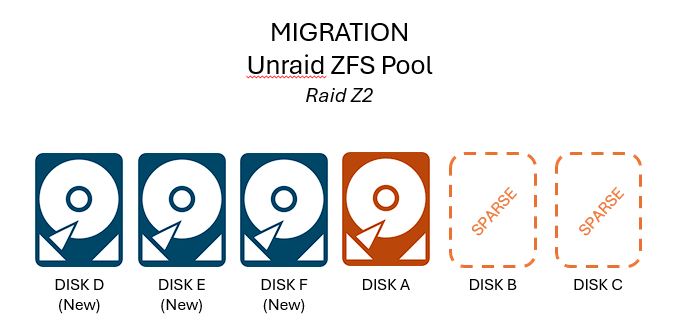
**NOTE: THIS PLAN OPERATES IN DEGRADED AND UNPROTECTED STATES. I HAVE MULTIPLE BACKUPS AND I AM COMFORTABLE TAKING THIS RISK. DON'T JUST BLINDLY FOLLOW THIS APPROACH IF YOUR SITUATION IS DIFFERENT.** Thanks to some Black Friday deals and in anticipation of Unraid 7, I picked up some more hard drives to be ready to migrate my array to a ZFS pool. I'm doing this for better performance and better data protection versus XFS and FUSE, and to get full ZFS functionality we have to use a separate pool and not the Unraid array. Current config: 3 disks in Unraid Array (1 parity + 2 data) Future config: 6 disks in RaidZ2 pool (2 protection + 4 data) THE PLAN Inspired by: [zfs-discuss] Can I create ZPOOL with missing disks? and Creating a degraded pool and Setting up new 4 disks RAIDz1 pool; build degraded Create RaidZ2 ZFS pool with four real drives and two fake drives (guide here: Setting up new 4 disks RAIDz1 pool; build degraded) 1. Pull parity drive from Array. Unraid Array is now degraded. 2. Create two sparse file "fake drives" to make ZFS think it has six disks available. These will later be replaced by the real disks from the Array. 3. Create a six-disk RaidZ2 pool using the four real disks (three new disks plus the parity we pulled) and the two fake disks. Copy data from Array to ZFS Pool 4. Offline and delete the two "fake" sparse drives so they don't interfere with our data transfer. ZFS pool is now degraded but still operational. 5. Copy the data from the Array (Disk B and Disk C) to the ZFS pool. 6. Scrub ZFS pool to confirm no errors. Restore ZFS Pool to full operation 6. Remove Disk B and Disk C from Unraid Array. 7. Use ZFS replace to switch the two fake drives with the two real drives. 8. Allow ZFS to resilver / repair until it returns to normal status. QUESTION: aside from the obvious lack of protection due to the degraded state, are there any other considerations here? Do these steps make sense? Am I missing something?
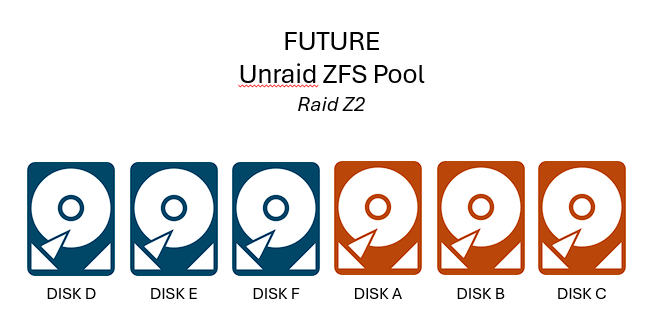
-
Confirming that this worked for me with a Smart-UPS X 1500. At some point in the past I updated it to firmware UPS 15.0 (ID20) -- not sure if that's relevant.
-
Oh yes but unless it's automatic, it's not happening! My last manual backup was in 2020
-
Failed on reboot. Pulled the drive and ran diskcheck on a windows machine. Windows showed errors as soon as I plugged it in. Let the checker run and it seemed to clear it up. Drive is back in the server and we just booted successfully. So hopefully that's it! But I will be using the My Servers auto backup now in case this drive does give out.
-
Got the dreaded message today 🤕 Is it safe for me to try a reboot? I noticed the wiki also suggests pulling the drive and running a disk check on a PC. Diagnostics attached. Edit 2: I also have the following error with my logs maxed out (??): Fatal error: Allowed memory size of 134217728 bytes exhausted (tried to allocate 2097160 bytes) in /usr/local/emhttp/plugins/dynamix/include/Syslog.php on line 18 Edit: Last manual backup I have is from 2020 and here's what I see in My Servers: citadel-diagnostics-20230323-2107.zip
-
REDIS_PASSWORD has been added in the latest update. I believe you'll have to manually add the environment variable in Unraid at the moment, but the app supports it now.
-
PR created because I have the same need
-
So it appears that formatting to remove type 1 protection wasn't enough -- but also changing to 4K sectors appears to have made it work. Not sure if they are both necessary in any particular order but it wasn't until the 4K change that I was able to see the full size of the drive. Now it is assigned in Unraid and rebuilding parity. The thread linked in the previous post does have a lot more detail about this whole process, but in summary it appears you can prep these specific Oracle/Sun HGST drives for use with Unraid using the sg_format commands together: sg_format --format --fmtpinfo=0 --size=4096 /dev/sXX --format will erase the entire disk --fmtpinfo=0 will remove Type 1 Protection --size=4096 will set sector size to 4K (instead of 512 or 520) [NOTE: your disk needs to physically support this change; an older drive might not] /dev/sXX should be changed to your drive's device name
-
So I ran sg_format as indicated in that post, for my device at /dev/sdb: sg_format --format --fmtpinfo=0 /dev/sdb Completed, here is the detail showing protection is set to 0: root@citadel:~# sg_format /dev/sdb HGST H7280A520SUN8.0T PD51 peripheral_type: disk [0x0] << supports protection information>> Unit serial number: 001551P1RTYV 2EK1RTYV LU name: 5000cca23bac41f4 Mode Sense (block descriptor) data, prior to changes: <<< longlba flag set (64 bit lba) >>> Number of blocks=15362376264 [0x393ab4248] Block size=512 [0x200] Read Capacity (16) results: Protection: prot_en=0, p_type=0, p_i_exponent=0 Logical block provisioning: lbpme=0, lbprz=0 Logical blocks per physical block exponent=3 Lowest aligned logical block address=0 Number of logical blocks=15362376264 Logical block size=512 bytes No changes made. To format use '--format'. To resize use '--resize' It completed this evening and the device is still showing as only 7.9 TB instead of 8.0 TB. Now I'm worried that because this is a Sun white-labeled drive, maybe it has some proprietary stuff on it that prevents it from having access to the full 8 TB or something. Any other ideas to try? EDIT: I came across this thread: https://forums.serverbuilds.net/t/fixing-sun-oracle-hgst-8tb-drives-reporting-7-86tb/7018 which suggests to reformat the drive with 4k block size instead of 512. Apparently it's a common issue for these Orace/Sun white-labeled drives. So tonight I'm going to kick off the 4k block size reformat and will report back tomorrow: sg_format --format --size=4096 /dev/sXX
-
Thanks, in progress now. I'll report back with results.
-
Diagnostics attached. I have attempted a full power cycle so unfortunately this won't show us what happened right after the preclear operation. citadel-diagnostics-20211218-1407.zip
-
It's a SAS drive so not shucked. When I try to run that command for HPA: hdparm -N /dev/sdb I get this result: /dev/sdb: SG_IO: bad/missing sense data, sb[]: 72 05 20 00 00 00 00 34 00 0a 00 00 00 00 00 00 00 00 00 00 01 0a 00 00 00 00 00 00 00 00 00 00 I noticed running this command on other drives does show HPA is enabled, although they all report bad/missing sense data (maybe b/c SAS?)
-
Just ran a full preclear cycle on a replacement disk (HGST He8 SAS 8TB - SUN branded) and it is showing in the GUI as 7.9 TB capacity instead of 8 TB. Of course, that means this new disk can't be a direct replacement for the old disk because Unraid thinks it is too small. It's the same model of disk and the same rated size as the drive it replaces. Anything I can do to rescan or clear that disk (or something else) to make sure Unraid sees the full capacity?

-
This is true but I discovered one slight modification; redis doesn't usually have a username so you actually leave it blank before that colon. So it will be: redis://:password@[IP]:6379
-
Yep it's under Settings > Docker > Advanced View and has a help tooltip. But I would never have known it was there without you guys nudging me to look for it. Google still turns up a bunch of older info from all the usual places (unraid wiki, forums, reddit, etc.) that says user defined bridges aren't possible in unraid. The question often comes up in context of using docker-compose so perhaps the older comments are more about that, but in short, I turned up empty on my research.
-
For paperless-ng, is there an environment variable for a redis password? I've been searching for a while now and can only find detail about the one variable to specify the redis host, but not the password.
-
I did and @aptalca helped me out. Didn't realize you *could* make user defined bridges in unraid, all my google searches turned up that it wasn't possible. Unraid docs need updating I think. Revised my previous post.
-
EDIT: This was all made moot by moving my external facing docker containers to a user defined bridge per the Unraid section of these instructions: https://github.com/linuxserver/reverse-proxy-confs#ensure-you-have-a-custom-docker-network. It is possible! Leaving the rest of the post here for posterity. Hi everyone, I'm still working on getting Authelia & SWAG to be happy. Because we're talking Unraid I can't use the user defined bridge network, so I'm trying to set it up with the subdomain config. I now have four different files I'm working with: authelia.subdomain.conf myapp.subdomain.conf authelia-server.conf authelia-location.conf For #1, I have set up the subdomain for authelia and verified that it works -- CNAME set correctly and can access authelia directly as expected. For #2, myapp works correctly on its own when unprotected. To enable authelia protection, I have uncommented the two relevant lines so that myapp includes #3 and #4 in its proxy config. For #3, I have it set up exactly according to the authelia sample on github, lines 1-30, with the only changes being I put the actual server IP and authelia port into the appropriate placeholders. And lastly #4 is changed only to remove /api/verify from location in the LSIO default, because that is already a part of #3 per the default config from authelia. So now the first line reads: auth_request /authelia; which means this file matches lines 36-42 of the github example. And now I'm getting these nginx errors: "invalid port in upstream "http://[server ip]:[authelia port]/authelia/api/verify," "auth request unexpected status: 500," Any suggestions for why it says the port is invalid? I noticed that lines 33-34 and lines 44-69 don't appear to be covered in any of these four files, but it also appears the LSIO has set up some slightly different variables than the default Authelia config so I'm not sure. TL;DR: Authelia works fine in SWAG independently, my app works fine in SWAG independently, but when I try to have my app protected by authelia i'm getting the upstream port error, above.
-
@TX_Pilot Can you explain a little more about how you achieve #2? With "creating an internal Docker network for your reverse proxy and specifying container names". Right now my whole system is in Bridge networking but I love the idea of using variables, as you have here... I'm sure there will be a reason my future-self will appreciate that.
-
Something like this could become very useful with Google Photos changing. Do you know if they intend to have mobile upload, sharing, etc? Seems like the use case is more for a professional (?) who backs up from a memory card to a directory on the server. Don't see a single file upload so I guess you have to find a way to get everything into the monitored directories.
-
Anyone had success with the built-in Collabora environment (CODE) in v19.x? I'm having trouble connecting to the new built-in CODE server and I wonder if it has something to do with nginx config. I'm using nginx proxy manager so I'm not sure how to properly edit the config to allow access, e.g. according to this post: https://www.collaboraoffice.com/online/connecting-collabora-online-built-in-code-server-with-nginx/
-
So I gathered that the drives might be accessed during the test so I actually shut down all VMs and all other docker containers (so this was the only thing running) and that produced the test results you saw in my post. I haven't had a chance to try swapping disks between the onboard controller and the PCIe controller but I can do that next if you think it might illuminate something. Thanks
-
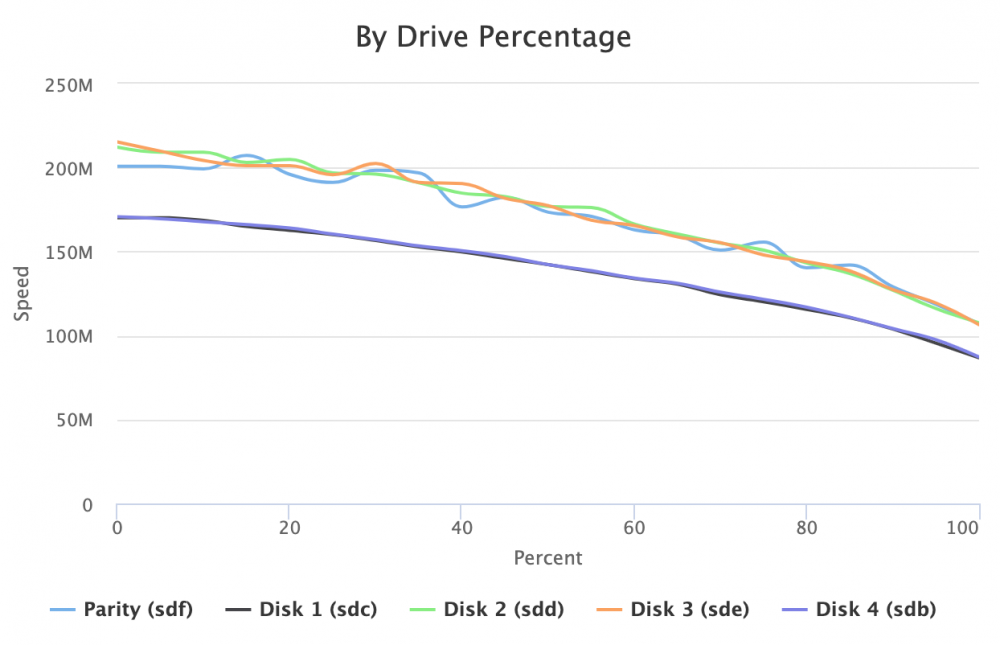
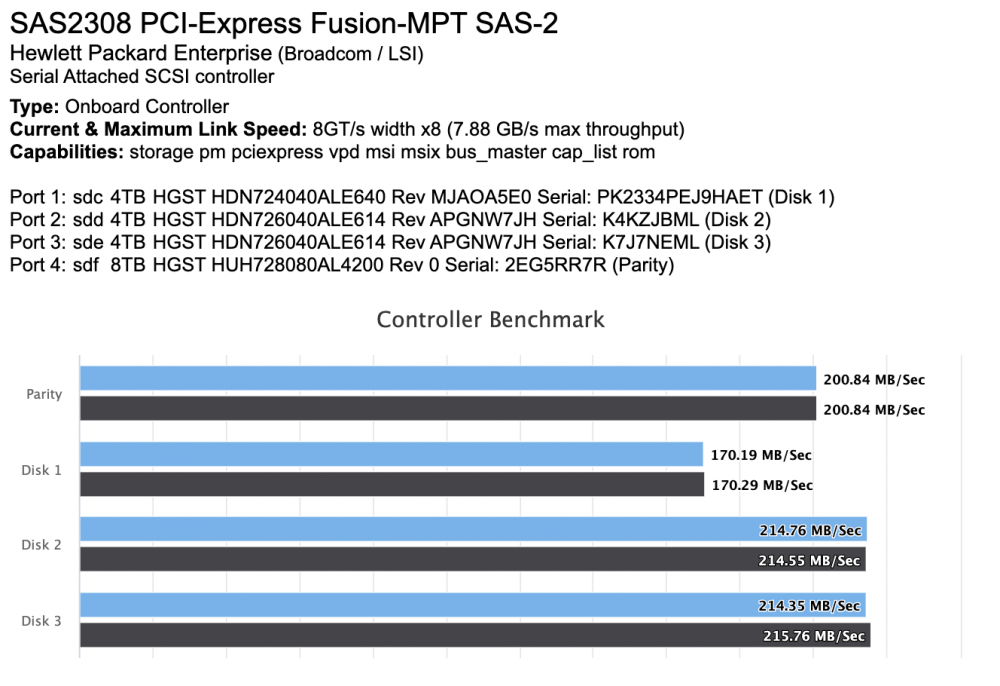
Hi @jbartlett this is a really cool tool, thank you. The tests are finding a few problems. Note that Disk 4 is on the onboard controller and the others are on a SAS HBA card. First, the app reports a bandwidth cap error on all my SATA drives. Second, I'm getting frequent Speed Gap notices when I run the all-disk benchmark. Third, the graph appears to be pretty shaky/wobbly for several of my disks. I attached a shot of the graph. Any suggestions for what is causing this behavior?