




Ti133700N
Members
-
Joined
-
Last visited
Everything posted by Ti133700N
-
Scan user shares is disabled, here is what happens when I re-enable the plugin with the option set to "No". Maybe I absolutely need to select at least one "Included folder" ?
-
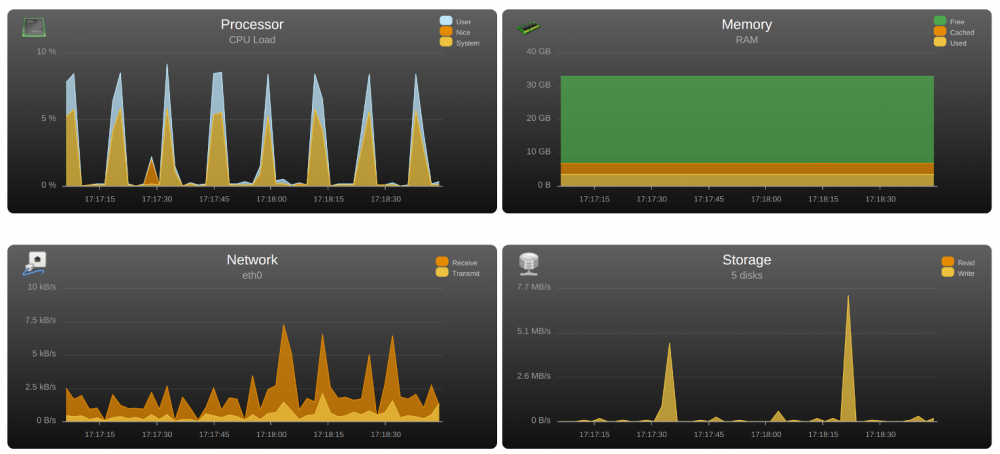
Thank you for the reply. I just found the source of the problem. Since I first noticed the issue yesterday, I thought it might have been a recent change in my UnRaid settings. So I remembered watching Gridrunner's latest video and installed a few plugins as a result in order to try to optimize my setup. After disabling Dynamix Cache Directories, CPU usage went back to normal. Not sure if it's supposed to behave that way, but in my case I don't want my fans ramping up and down every 8 seconds because of CPU usage spikes, so I'll leave it off for now and maybe I'll check with Dynamix later on to see why this is happening. Thanks !
-
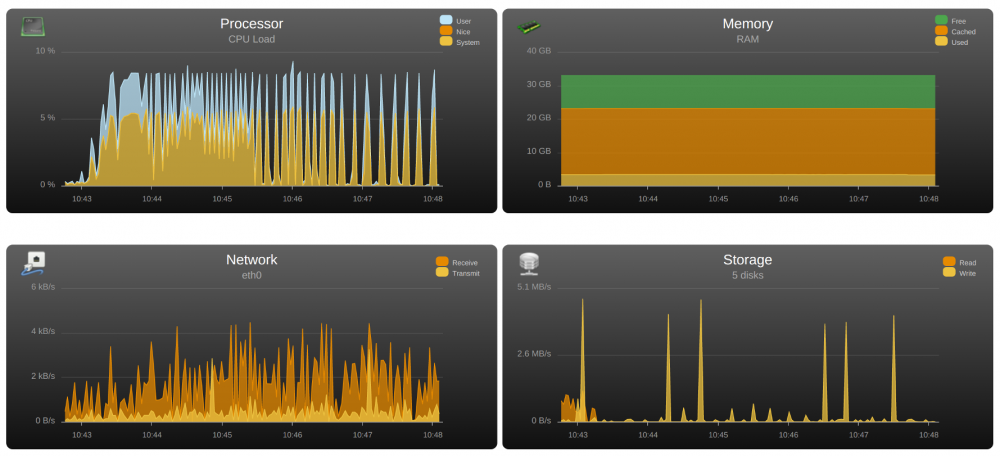
Hey guys, yesterday I noticed the fans in the server started spinning up and down at regular intervals, so I looked at UnRaid's System Stats and saw that the CPU was spiking up every 8 seconds. From the dashboard, in the System Status, I can see that every 8 seconds, a random thread spikes to 100% usage and then goes down to 0%. All the VMs are shutdown, and I also tried disabling Dockers completely but I am still getting the same result. I also tried SSHing to the server and looking at "top", but I didn't see anything super suspicious, although I might need help on that front. What steps should I take to debug this issue and determine what is the cause of those spikes (I assume that's not "normal") ? Thanks !
-
That sounds amazing, except for retro-gaming I would probably prefer playing it on my TV rather than in my computer room and since I can't directly pass-through GPU (TV is way too far from the server), I don't think this is a viable option for me. I currently use an HTPC running Steam OS to play games on my TV. Can you think of a workaround to use Lakka remotely or do you know something similar I could use on my Steam OS (Debian) ? What I like about Lakka (from what I understand) is that you can simply execute the rom and it will automatically play it. Currently with my setup I have to configure various emulators and manually launch them and start the rom, which is a bit of a pain. Thanks !

