

-
Posts
616 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Can0n
-
-
On 2/8/2020 at 4:04 PM, sdamaged said:
168TB usable, with 14 x 14TB including two drives for parity.
16 bay server, didn't want to go 24 bay as was worried about having more drives with only two parity drives.... (triple parity please!)
I have asked for option for as much parity as we want, but constantly asked "Why" i said becasue with 28 max Data drive risk of more than two failing at once increases the future answer is multiple drive pools with up to two parity and 28 data drives per pool so that will help
-
two servers (formerly 3---retired one)
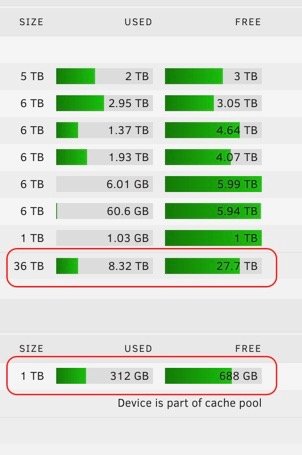
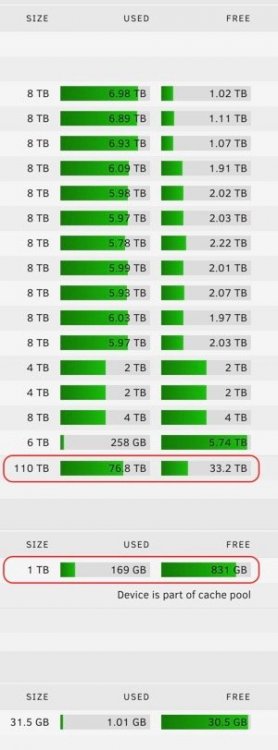
Primary 2U 12bay hotswap - 110TB Data Array, 1TB Cache pool (2x1TB SSD) Two 8TB Parity DrivesUsing a Netapp DS4246 to get past my Server Case's 12 drive limit only just starting to populate it now
Secondary 3U 10 bay hot swap - 36TB Data Array, 1TB Cache pool (2x1TB SSD), 1 6TB Parity Drive
So guess if counting both im at 146TB total Array space and 2TB Cache space

-
thanks everyone
I backed up the plus.key file under the config folder and tried to use the mac USB creator but that doesn't work on MacOC 10.15.3 (get a pasteboard error i posted on another thread) so i grabbed my linux/windows dual boot laptop and booted windows and wrote 6.8.2 (last version used as well on my old server) and was able to restore the USB and placed the backup of the plus.key under the config file
hoping that should work but i dont have a system other than the laptop to test it on and it wont boot on that -
Hello Everyone
I retired my Green server in my signature, sold the hardware but kept my unraid USB, I am looking to give this USB to my brother for his build and wondering if there is an easy way to factory reset it with out the hardware to boot and reset the configs, i found the obvious one like user shares i removed and plugins and machine name, SSL certs etc. should i just back up the key file and format the usb and reflash unraid to it and put the key file back?
Ideas and Suggests are all welcome -
The beauty is you don’t even need to install it on your VMs you can just set your config profile in unRAID To send you an alert if pinging any of those PMs goes down that’s how I have my VM’s monitored without paying extra to Pulseway Since I am currently paying for five systems but I only need four now since I sold one of the servers that was running my third instance of Unraid
-
On 11/3/2019 at 10:32 AM, Hoopster said:
Yes, you cannot connect to docker containers on br0. You need either a VLAN or different NIC to which to assign docker containers that need a custom IP address.
Sent from my iPhone using TapatalkI have no issues accessing my br0 dockers using the fqdn i have assigned to them internally from my iPhone using Wireguard with Remote LAN connection, only using port forwarding (cant seem to get static routes to work on my Unifi setup) no VLAN's in use for br0 either
-
On 1/14/2020 at 3:12 AM, SavageAUS said:
What would be the procedure to uninstall this?
Just remove the copy and execute commands commands from your go file
then Run
/etc/rc.d/RV.pulseway stop
to remove the config and files in command line run these:rm -rf /etc/pulseway
rm -rf /var/pulseway
rm -rf /boot/pulseway
rm /boot/extra/pulseway.tgzp
then reboot the server
-
 1
1
-
-
On 3/20/2017 at 10:31 AM, PTRFRLL said:
cp /boot/pulseway/config.xml /etc/pulseway/config.xml cp /boot/pulseway/pulseway.id /var/pulseway/pulseway.id /etc/rc.d/rc.pulseway start
thank you for the update for 6.8 !!!!
I was just following a video tutorial here on youtube and i am running 6.8.1 and wondering why after all was setup Pulseway saw the server and i rebooted to test that pulseway never saw it come back up and when i saw the daemon wasn't running and I couldnt start it was getting an error i then found the config.xml was gone so i redid them and made some manual backups to the array as well for safe keeping -
after doing some research online I found some drives have it disabled in firmware and you need to contact the drive maker to get updated firmware to have it enabled. ill eventually replace that old HGST as i bought it used anyways but no issues with writespeeds with it disabled anyways
-
On 1/7/2020 at 4:46 AM, drawmonster said:
Two servers updated without a hitch.
me too leaving third one (main one) on 6.8 for now in case of issues
-
On 12/30/2019 at 3:27 PM, interwebtech said:
I've been troubleshooting erroneous disk utilization warning emails and found there is no way to visually determine what any particular disk's utilization status is. I would like to propose adding a column to the display grid (far right between Free & View) on the Main tab (Array Devices & Cache Devices sub tabs) with simply "%" for heading and the calculated percent full for each disk. Maybe go out a couple decimal places so you can spot one about to go over without it actually having to happen. Total at the bottom but frankly that already covered by the "Show array utilization indicator" doohickey.
this isn't a percentage per-say but you can get an actual read out already on the main tab like this
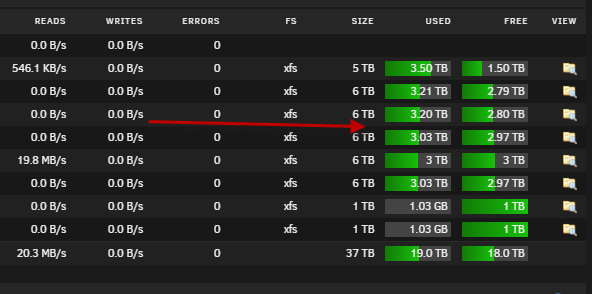
to get it, go to settings, display settings then scroll to bottom and check all the
Used / Free columns setting to find your preference my image is using Bar (Color)
-
Just now, trurl said:
If I had been replying to you instead of OP I would have quoted something in your post.
hahaha ok no worries
-
4 minutes ago, trurl said:
Possibly one of the hundreds of dockers available can be used to solve some of your needs without you needing to resort to the command line.
Have you installed Community Applications plugin yet?
I did like 3 years ago lol this my post was to be able to ssh without using a password some things need CLI when GUI isnt available
-
22 minutes ago, Derek_ said:
Thanks. I'm was just starting to look at keyfile authentication and to my horror its not in the GUI at all. As i've just posted in the SSH plugin thread i think that's astonishing. IIRC SSH is enabled OOTB, and now i see that there's no GUI way to change the authentication method to key only. Password entry should be disabled by default.
Reading more, there's no fail2ban built into the OS either. Does the Let's Encrypt Docker with f2b protect the OS, or just the Docker?
I have SSH keys enabled for my Putty, and linux and mac terminal i found it on a linux forum
to use and create
Ssh keygen
On host:ssh-keygen
ssh-copy-id root@unraid hostname or ip
On server may need to run these as root
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
then add this to the go file in tools->config file editor (it will make the key and ssh file persistent across reboots since the live unraid system lives in ram)
#SSH Keys Copy and enable
mkdir /root/.ssh
chmod 700 /root/.ssh
cp /boot/config/ssh/authorized_keys /root/.ssh/
chmod 600 /root/.ssh/authorized_keys
as for your questions about fail2ban and lets encrypt i cant answer those I have my own reverse proxy running in a VM on another server and dont expose my servers host ip to the internet (dockers and VM's have access since they cannot access the host directly)
-
you can use the SSH plugin called "SSH Config Tool" on the app tab to enable multi user SSH access
it works well if you dont want to use root when using SSH
more info here
-
network stats is a plugin i suspect
you can shut down the server move the USB to a computer and go to /config/pluginsremove the netstats plg file and its folder then move USB back to the server and try and boot
-
 1
1
-
-
48 minutes ago, JohnGaltLine said:
This is late for the OP, but may be useful for anyone else with the same problem. For whatever reason, when using the binhex-plex server, possibly other dockers as well, the webUI option doesn't appear on the menu when the docker is running on a different IP from the UnRaid interface. Following Craftsman's instructions above will work just fine, however the menu option will still not appear. You simply need to type the IP of the plex server and the 32400 port of Plex into the address bar of your browser, for example if the plex server is set to use 10.0.1.124 as in the example posted above, type " 10.0.1.124:32400 " in the address bar of your browser to access Plex's WebUI.
I noticed using br0 that the webgui in the contextual stopped working on unRAID 6.7.4 binhex doesnt want to find and fix what ever changed since then back when i noticed it i back dated and the option was there again. updated and its gone again something changed in unRAID in 6.74 that conflicts or errors out, something other plex dockers dont seem to have a problem with
-
On 12/14/2019 at 2:19 PM, astarock said:
Hi binienl. I did exactly as you described and saved. Plex docker is starting but when click ont the Plex icon to pop up the web gui below console, there is no web gui to select?
yes binhex container wont show webgui link since unRAID 6.7.4 i have personally spoken to Binhex here and on the github link and he says support for using custom is not built in...it works still access the webgui via the IP:32400 and you will get in
I have found linuxservers Plex works fine when using br0 as does the official container but i prefer the binhex/arch-plexpass container myself.
to fix the need for an ip in my browser I added a fqdn to my Pi-Holes lan.list file in /etc/pihole
made mine like this
10.0.1.124 myplex.mydomain.ca myplex
now i can ping myplex and get a reply and bring the gui up by typing myplex.mydomain.ca:32400 -
just saw this banner come up on two of my 3 unRAID server

Happy New Years and may 2020 bring many more great things to everyone
-
Hi All I just started seeing this in FCP for my HGST HUH728080ALE600 about two months ago on one of my drives there is no errors in SMART at all and my other WD red's and HGST and Seagates are fine (all 8TB drives)
the closest to same model I have working is HGST HUH728080ALE604 (note the 4 instead of 0 on the end)
hdparm -W 1 /dev/sdg/dev/sdg:
setting drive write-caching to 1 (on)
write-caching = 0 (off)
wierd thing is disk speed actually shows this disk perform just as good as the other drives in the array in terms of read and write speeds -
im getting same issue on one of my HGST_HUH728080ALE's 8TB Sata drive that JUST showed up. I have 3 others of the same model without issue it just wont enable.
I have another similar model with no issue
HGST_HUH728080ALE604 is fine
HGST_HUH728080ALE600 is the one that wont enable with the hdparm or sdparm commands
root@Thor:~# hdparm -W 1 /dev/sdm /dev/sdm: setting drive write-caching to 1 (on) write-caching = 0 (off)
also tried
root@Thor:~# sdparm --set=WCE /dev/sdm /dev/sdm: ATA HGST HUH728080AL T7JF root@Thor:~# sdparm -g WCE /dev/sdm /dev/sdm: ATA HGST HUH728080AL T7JF WCE 0 [cha: y]
diagnostics attachedthor-diagnostics-20191114-1147.zip
-
11 hours ago, paperblankets said:
Is this still the best way? I'm finding the installer stalls during install, and eventually restarts.
I'm deleting my vdisk and starting fresh. In case something with vdisk I created is the issue.
Unraid 6.6.7 (Awaiting 6.8.* to avoid database corruption issues)
Settings:
Base VM: Arch
Distro: I've tried both Manjaro KDE and XFCE
Primary vDisk bus: Virtio
Graphics: VNC Cirrus
Bios: OVMF
Machine: Q35-3.0Both installers have been stalling at or before 30%. I've tried all the above with `systemd.mask=mhwd-live.service` set as well.
Edit: I got a stable install by wiping my entire hard drive from the install media, and then selecting the ext4 partition I wanted to install onto.
6.8 RC4 and on corrected the database corruption that some got (I never did see it for the last few years)
try my method I have since my last post removed all the manjaro VM's -
On 11/8/2019 at 12:10 PM, Trites said:
I tried setting this up. I've been using openvpn-as docker with no issues but with wireguard I cannot get the handshake to initialize.
On my iPhone the log indicates:
... 2019-11-08 14:53:52.110832: [NET] peer(q4nv…iXkg) - Handshake did not complete after 5 seconds, retrying (try 19) 2019-11-08 14:53:52.111139: [NET] peer(q4nv…iXkg) - Sending handshake initiation 2019-11-08 14:53:57.174070: [NET] peer(q4nv…iXkg) - Handshake did not complete after 5 seconds, retrying (try 20) 2019-11-08 14:53:57.174466: [NET] peer(q4nv…iXkg) - Sending handshake initiation 2019-11-08 14:54:02.217420: [NET] peer(q4nv…iXkg) - Handshake did not complete after 20 attempts, giving upAt first I thought it was a port forward issues, I tried enabling UPnP and letting wireguard do its thing but that didn't help. It appears that my client is hitting the service as the data sent/received goes up but no handshake.
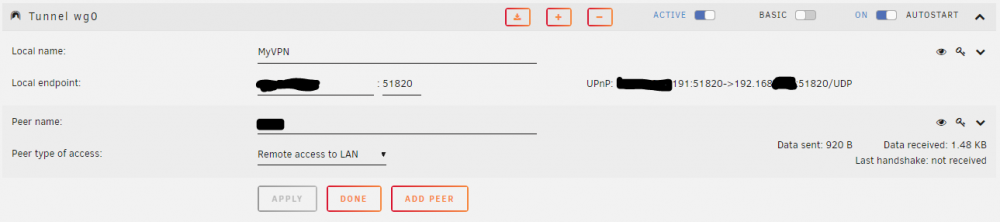
Any ideas what would be causing this? Are there any logs available within unRAID I can look at?
Thanks.
under the wg0 tunnel Local endpoint: is your public facing IPv4 address
under the peer (your phone) make sure peer end point is the static internal IP of your unraid server
-
On 11/8/2019 at 12:52 PM, Trites said:
Just tried it, no luck. I changed it both on unRAID and my iPhone Client.
The odd thing is, I can get it working on a Win 10 Client on my network.
I've been testing with my iPhone with wifi turned off. Would my Cell service be blocking something? (I'm on Bell in Canada)
Update: I can get it working on my iPhone while connecting to the same network as my server (Internally). Looking like my network is to blame. I'm using Google WiFi if anyone is curious.
did you set up your port forwarding? im on telus (canada) and no issues once i set up port forwarding








How many TB's is your Unraid Server?
in Unraid Polls
Posted
this is one reason I have staggered the purchase and installation of drives
I have just had two recently purchased Seagate Ironwolfs both exihibit UDMA CRC errors and due to time sensitivity of the RMA from the reseller i got them from I had to replce both last night Parity is almost done rebuilding but boy would it have sucked if one of my other 13 drives decided to bite it while rebuilding the two current drives.