




relink
Members
-
Joined
-
Last visited
Everything posted by relink
-
Technically yes, that was intentional. The sync only goes 1 way, from the share on the Array > Cache, and I was under the impression that If a file exists on the array, and it also exists in the exact same location on the cache drive that when the mover is ran it will simply fail to move those files and skip them. Correct me if Im wrong. I have actually read that before. But in the description of the first post it's talking about "If a user attempts to copy files from a disk included in a user share, to the user share", which is technically not what I am trying to do. I am copying files from a user share to a disk that "technically" isn't directly part of the user share. I have tested this with one show so far, and it seems to have worked If I am completely wrong in my thinking of how to accomplish this, then what would be the best way for me to remove the data from the cache disk without risking the data in the share on the array?
-
literally over 90% of what causes my Array to be spun up is my kids watching the same hand full of movies and shows. So I setup rsync to copy certain directories back to the cache drive, this way they will be on the cache AND the array. So when those shows or movies are watched my array wont need to spin up, but they are also still protected by the array. In this example, the show I tested with is downloaded from Youtube using Tubesync. I want to be able to use the --delete option with rsync so that anything removed from the Array will also get removed from the cache the next time my rsync userscript is ran. However I also realized that if Tubesync grabs a new episode it will place it on the cache drive, and if my userscript runs before the download is finished wouldn't rsync delete the in progress download? Current Rsync command: rsync -av --progress --delete "/mnt/user/Video/Youtube/video/show" "/mnt/cache/Video/Youtube/video/" I have a couple of solutions but they all have potential issues: 1. just remove the --delete option. But then I would have to remember to manually remove the cache drive copy wouldn't I? or would unraid know to delete both? 2. Modify the mover script to exclude those directories and reverse my rsync command. But I really don't want to modify the mover or any "system" files. Im ok if the files get moved from cache to array and then copied back to cache. 3. Use "Mover Tuning" to only run my command after the mover finishes. This seems like it may work, but I'm still concerned about in-progress downloads? I'm sure the mover is smart enough not to move them, but is rsync smart enough not to delete them? 4. Create separate shares for these files. But I'd prefer not to, I might use this for other files too, and things could get confusing fast. OR maybe I'm overthinking the whole thing and there is a better way to do this...
-
No unfortunately I still haven’t found a reliable way to do this automatically. And I opted to not do anything manual or janky that I’d end up forgetting I did a year from now. Honestly Im surprised this just isn’t a built in feature yet. A read cache seems like such an obvious thing to have. I might consider taking a crack at it myself at some point but I have never used anything like inotify before. My scripting skills are mostly just from piecing together Google searches. Lol
-
Im having my server lockup pretty regularly, it may take 5days or more but eventually it will lock up guaranteed. When this happens The WebUI still mostly loads, but all the graphs and actual details dont. I cant tell if my docker containers are still running or not, they dont act like they are but they still showup in htop. Infact when I ssh in and look at htop everything looks fine. On my syslog server I got over 2.8million logs from unraid just stating various forms of "out of shared memory", "no memory", and "no space left on device". But again, htop looked fine. I also checked the capacity of my flash drive and its only at 1.5GB of used space. So im not sure what space its running out of.... I took a diagnostics while it was locked up, and then I took another after stopping the array before I rebooted. serverus-diagnostics-20211206-0950.zip serverus-diagnostics-20211206-0926.zip
-
Im thinking this was the issue, g2g, xteve, and Plex were all updating around midnight, so if g2g or xteve wasn't done yet and plex did its import that would explain why my guide would have been empty. So what I did was changed the cron.txt so that g2g updates at 9:00pm, I set xteve to update at 10:00pm, and left Plex at its default of between 11:00pm-Midnight. This way there is absolutely zero chance any one of them will ever overlap.
-
I can certainly try it if nothing else works, but I've had bigger lineups than that working for almost a year, on the same system with 32GB ram. I think ill check into this first, as the g2g cron, xteve, and Plex all update at the exact same time. Im going to try and stagger them. However I am going on 2 days and I still have guide data so far....
-
Yup, I ran it manually and everything worked fine. Im not sure I follow, I have 3 lineups all very small, 79 channels , 19 channels and 9 channels. and each one has its own yaml. All 3 are set to download 14 days of guide data, and the cron is whatever the default in the container is. Part of the issue seems to be that already downloaded data is being replaced by nothing. I ran cron manually today, and currently have data but there is a good chance I will wake up tomorrow and have no guide data again.
-
My guide ends up blank almost every morning. I’ve been running your Xteve guide2go container for a couple years now. A few weeks ago I started loosing guide data almost every morning. I changed IPTV providers last week so I took the opportunity to start over from scratch, new cron.sh, new yaml files, everything should be new. I thought I fixed it, but I woke up today to no guide data again. not sure what else to check?
-
Thank you for laying that out for me, I had no idea those steps were required to make this plugin work. But it is definitely working now. oom errors are rare, but it's nice to have a safety net now.
-
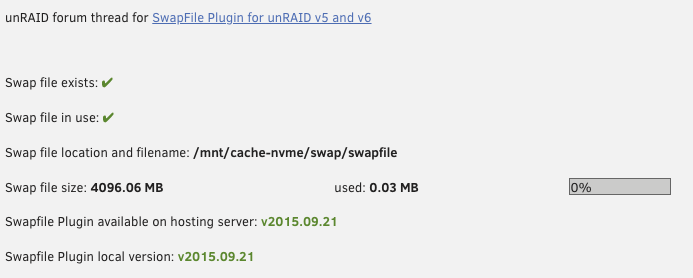
@primeval_god thanks for the tip, I tried running the command and got the following output, and the swap is still not enabled. swapon: /mnt/cache-nvme/swap/swapfile: insecure permissions 0666, 0600 suggested. swapon: /mnt/cache-nvme/swap/swapfile: read swap header failed After some googling I see people using other Linux distorts running “mkswap”, but they are all referring to a swap partition. I’m not sure if that’s the correct fix for unraid.
-
Im having the same issue. Mine is set to "/mnt/cache-nvme/swap/" so I ran the below commands; - cd /mnt/cache-nvme/swap/ - truncate -s 0 ./swapfile - chattr +C ./swapfile - btrfs property set ./swapfile compression none everything looks fine, and I don't get any errors. I see "Swap file exists: ✔" but when I click "start" nothing happens and it still shows "Swap file in use: ✖"
-
I think I might have got it, and shame on ASUS for this one. For whatever reason they decided to give the top PCIe slot 2 different modes that you have to manually change “X16” and “PCIe RAID Mode”, now what’s confusing is if you read the help at the bottom of the screen this option talks about enabling this for a single specific m.2 expander card, nowhere does it say it’s used for anything else. To make matters worse not only is the change not reflected in the manual on the ASUS website, the entire section is missing from the manual, and none of this was documented in the change logs for the BIOS updates. I can’t believe I just spent 4 hours trouble shooting every inch of my server, only to find out it was an undocumented change to the BIOS... Since I am far from the only person with an AM4 ASUS board, and I’m sure in not the only one who doesn’t put their transcoding GPU in slot one the solution to this is below; In your BIOS go to; Advanced > Onboard devices configuration then change; PCIEX16_1 to PCIe RAID Mode
-
Swapped it back and it’s gone again. something changed with this BIOS update and I cannot figure out what it is. I’m currently reading the Mobo manual and it’s not very helpful so far. I’m going to read through all the release notes for the bios versions. something is different, I just need to find out what...
-
Literally just finished trying that and it does seem to work in another pcie slot. But I had to swap with my GPU and the GPU is also still working. I keep my HBA in the top pcie x16 slot so it’ll get all 8 lanes it needs, then my NVME, GPU, AND NIC all get X4, and it’s been like that for over a month now. The bios update has to have done SOMETHING that is causing it to not initialize the raid card when it’s in slot one. I’m going to tray swapping back and see what happens.
-
Oh man this seems to get getting worse and worse. I made a freeDOS bootable USB and got a copy of the cards latest bios and the flashing utility. I load it up and get the error “no known controllers detected. Quitting” has anyone ever had something similar happen? I find it very hard to believe my raid controller just died out of the blue like that. Are there any bios settings on my Mobo I should look for?
-
I have finally found some more info, including the missing “readme” however when it comes to the instructions for resetting everything I have found says to just contact Adaptec...not very helpful. of course I didn’t do anything afaik that should have messed with the raid cards bios...
-
I have been troubleshooting some crashes on my unraid server for the last couple weeks, after checking everything software I could think of, I moved onto the hardware, after re-seating my ram I decided to update my motherboards bios. The bios in my board was from 2019, and there are updates all the up to 2021. The update went fine. Except for some weird reason now my Adaptec raid card is just...gone. It’s like it’s not even in the system. It should show in the bios, and it doesn’t. It also doesn’t show up anywhere in unraid. I did notice that immediately following the Mobo bios update that I saw the Adaptec “Press CTRL + A” screen which was odd because I had disabled it back when I first bought the card. The boot failed because I didn’t realize the update reset my settings, and it was actually trying to boot from the HBA. after putting my bios settings back to boot from my unraid usb, I tried again. This time I saw another Adaptec boot screen with the message “BIOS not installed” and my system then booted into unraid, and there has been no sign of my Adaptec card since other than it’s leds do still blink when booting. I read the manual for the card i found a section on how to reset the card, but it just tells you to refer to “the read me”....but I have no idea what read me it’s talking about. Mobo: Asus rog strix B450f gaming CPU: Ryzen 5 2600 HBA: Adaptec 71605 1G
-
So, as a temporary work around, would there be an issue if I copied files over to the cache from the array? From how I understand it everything would function like normal, except those files that are duplicated wont get moved.
-
Well it was a total success! After quadruple the amount of time I thought it was going to take my new cache drive is up and running. I think next time I’ll take the advice above and just restore from my backup.
-
Good thing I ended up not doing that at the last second. instead I decided to add my new nvme drive as a second cache, and use MC to move everything from the old one to the new one and reassign the cache for each share. however, this is still ungodly slow. Midnight commander “claims” it’s transferring at 15MB/s ...it’s not, there’s no way. It’s maybe 15Mb/s if that. I calculated out the transfer time beforehand and this should have been done hours ago, yet it’s still going.
-
I just realized that midnight commander is built in to unraid. Woul I just stop the mover and then use that to move the folders from “/mnt/cache” to “/mnt/user”?
-
What command would I need to run to move everything from cache to array? unless there’s some reason I shouldn’t, I will gladly stop the mover and do that instead.
-
Crap...that’s exactly what it is. Tons of tiny little files.
-
As the title says I am trying to upgrade my cache disk so I am moving everything to the array. I stopped docker and VM services first, and set all shares to use cache yes. The mover is running but it’s been over 12 hours and it’s not even half done. I would have expected a transfer time closer to 6 hours. so far I have used “renice” and “ionice” to set the priorities of the processes involved in moving higher, but it doesn’t seem to have made much difference. I was hoping to do that cache upgrade this morning, but at this rate I’ll be lucky if I can do it by tonight.
-
So I e been giving this some thought over night and I’d really like to take a stab at this. if all I need to do is make sure the file/directory exists on both the cache and the array, that’s easy enough to do. the tricky part is how do I find out when the file was last accessed? Considering the extra write required I doubt unRAID keeps track of “atime” on files. And I don’t know how to use the Plex API but this could be made really simple I’m thinking. As an example If the movie has been watched in the last week copy its entire directory (so the srt files come too) to the cache. The script runs daily, and checks the last time a movie was watched, once it’s been more then 7days the copy gets deleted. As for TV shows, I’m thinking it should copy entire seasons but this could be messy quick. Especially if - like me - you run something like DizqueTV.


