relink
Members
-
Joined
-
Last visited
Everything posted by relink
-
This has all been happening for a few months now, but because of how rarely it happens I haven't been able to catch it in the logs, and sometimes during periods of low use I won't even realized it's happened again for hours or days. For the last several months I have been having some issues, that initially I thought were unrelated, but now I'm starting to wonder... 1. Most docker containers don't seem to pickup my servers IP in the template anymore. Meaning when I go to click "WebUI" for a docker container I just get http://:8080 or whatever port it happens to be. I have to manually put my IP into nearly all my docker containers templates now. 2. Sometimes, but not always, I will reboot to find a majority of my Docker containers and custom docker networks just gone. It seems to be after the server has been up for an extended amount of time. I'm struggling to make any sense of this. I tried recreating my docker directory (Overlay2) and it still happened, just now I created a ZFS dataset for docker and re-created the directory again using the native file system. I figured I'd try something different, But realistically I'm not sure if this has anything to do with it. I was thinking maybe the docker networks aren't being re-created sometimes and that's why the containers are disappearing. But that would cause them to not start sure, but it shouldn't cause them to disappear entirely right? Another theory is that maybe some of my config files are malformed or something? Flash drive is fine, and it's not old. Though my flash does have files on it from previous installs going at-least back to 2022. When I got the new flash I just moved my old setup over, but this was over a year ago. I've been watching syslog for hours now and nothing out of the ordinary has popped up, I've been re-creating all my containers for about the 6th time this year and they're all running fine. And much like last time I'll probably reboot a few times when I'm done to make sure everything is working, and it will be, and in another couple months it'll happen again.
-
Ohhh, if this gets added it would be fantastic for people who don't use ZFS. Too bad this wasn't around before I rebuilt my entire server. Still going to be keeping my eye on it.
-
I'll have to check for that. I've seen that setting on multiple boards but it never crossed my mind that it might allow more than two options. I've just always seen, "igpu" or "peg". I haven't found any other way to change the priority of GPUs and watching Ollama use my 2070 for a majority of the workload, while the 4060Ti barely does anything is heart breaking lol.
-
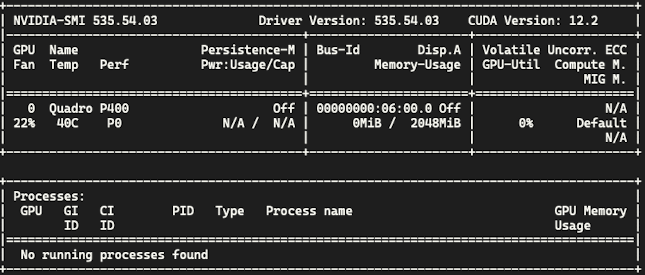
I have a Supermicro H12SSL-I-O and I have my GPUs in the physical slots that make sense airflow wise. But the causes the less power GPU to be seen as as the primary which is more annoying than I thought it was going to be. What I have is: Nvidia Driver Version: 575.51.02 Open Source Kernel Module: No Installed GPU(s): 0: NVIDIA GeForce RTX 2070 C1:00.0 GPU-255a4e4c-c942-9e62-96c7-86f8bd570a48 1: NVIDIA GeForce RTX 4060 Ti C2:00.0 GPU-c3d8840d-95dd-a5f7-e875-0626902776df All I need is for the 4060Ti to be `GPU 0`, and the 2070 to be `GPU 1`. If the Supermicro H12SSL-I-O has a BIOS setting for this, I'm not sure where it would be, but I'd be willing to change it if I can find it. I just really don't want to physically swap the cards because then 4060Ti will exhaust directly into the 2070's intake.
-
Sorry it took me so long to reply. I tried a brand new fresh USB and still froze at the exact same spot.
-
I didn’t even consider just making a fresh USB to test with😅 Ill give that a shot and see if I’m able to boot.
-
I recently got a H12SSL-i board along with an EPYC 7402P and 256GB of RAM. I’m on Unraid 7.0.0 and my previous board booted without any issues. I was using an ASUS STRIX B450-F Gaming with a Ryzen5 2600. When booting on the SM board It freezes after the loading bz root stage when it would normally begin showing the syslog and actually booting Unraid. I am using a dedicated GPU because the onboard VGA doesn’t work for the reason below. MASSIVE DISCLAIMER: I’m one of the lucky ones who had the VRM for the BMC burnout the very first time I plugged the board in. Yay me. I’m in contact with the seller and SuperMicro already. So while I wait to hear from SuperMicro I wanted to see if the board was atleast stable without a functional BMC. So far it’s looking like it’s not, but also maybe… I was able to boot into a live Ubuntu session which seemed to run fine for the short amount of time I used it. So I’m trying to figure out if Unraid isn’t booting because of a BIOS setting or something I need to change on my USB. Or if Unraid isn’t booting because of the damaged BMC.
-
Did I miss something? Edit: Nevermind, Apparently I did miss something, just checked out the Pricing page. All up-to speed now, lol.
-
Worked perfectly, thank you.
-
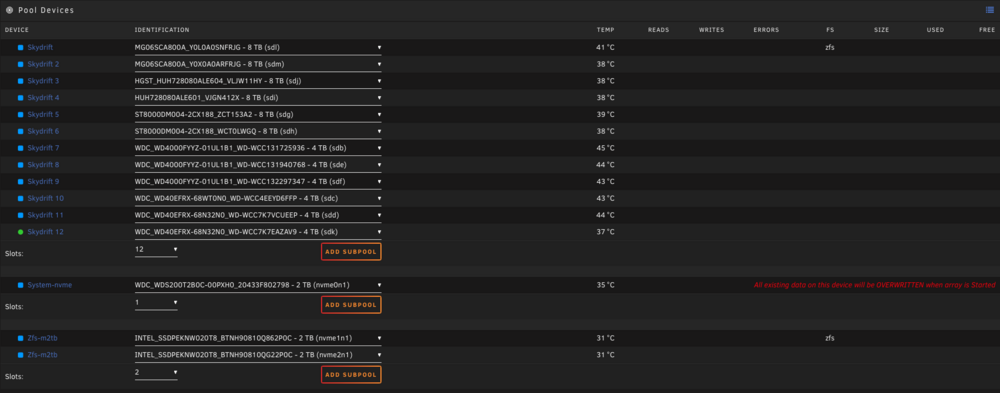
Do you mean just create a "new config", put the drives in the same slots, but instead of specifying the format and layout just leave it set to auto and don't change anything? Or do you mean the do a zpool export via the cli?
-
UPDATE: I created a new config, placed all drives into the exact same slots, with the exact same file system and settings. The array is up and everything is running fine, except `sdh1` but I already know about that. Attached is another screenshot except with the drives mounted now, and I attached another diagnostics taken immediately after start the array with the new config. UPDATE: Everything is still the same except I find it hilarious that all the sudden `sdh1` is fine again. I hate Seagate drives lol. Plus, "One or more devices has experienced an unrecoverable error", yet all disks are online and the pool is not degraded... pool: skydrift state: ONLINE status: One or more devices has experienced an unrecoverable error. An attempt was made to correct the error. Applications are unaffected. action: Determine if the device needs to be replaced, and clear the errors using 'zpool clear' or replace the device with 'zpool replace'. see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-9P scan: resilvered 82.7G in 00:16:42 with 0 errors on Sat Nov 9 10:44:18 2024 config: NAME STATE READ WRITE CKSUM skydrift ONLINE 0 0 0 mirror-0 ONLINE 0 0 0 /dev/sdl1 ONLINE 0 0 0 /dev/sdm1 ONLINE 0 0 0 mirror-1 ONLINE 0 0 0 /dev/sdj1 ONLINE 0 0 0 /dev/sdi1 ONLINE 0 0 0 mirror-2 ONLINE 0 0 0 /dev/sdg1 ONLINE 0 0 0 /dev/sdh1 ONLINE 0 0 2 mirror-3 ONLINE 0 0 0 /dev/sdb1 ONLINE 0 0 0 /dev/sde1 ONLINE 0 0 0 mirror-4 ONLINE 0 0 0 /dev/sdc1 ONLINE 0 0 0 /dev/sdf1 ONLINE 0 0 0 mirror-5 ONLINE 0 0 0 /dev/sdd1 ONLINE 0 0 0 /dev/sdk1 ONLINE 0 0 0 errors: No known data errors serverus-diagnostics-20241109-1035.zip
-
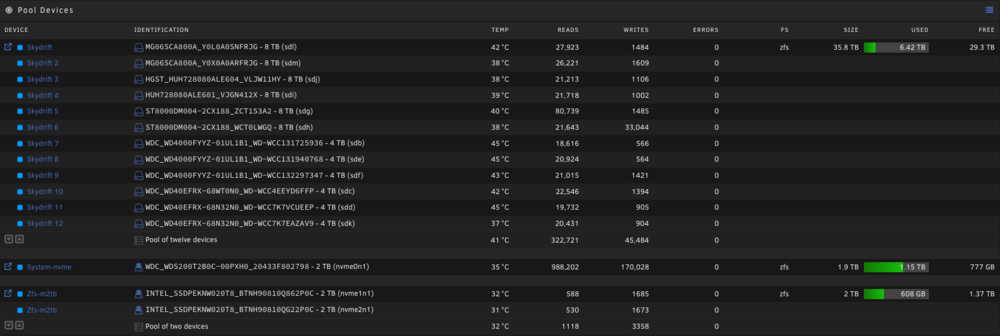
I attached a screenshot of my ZFS pools from the main page, and diagnostics. As you can see all the disks are marked as new...they are not new, not a single one. The "cache-nvme" disk is marked as new and that it will be formatted, it is also not new. Plus it has yet to be formatted, when I'm able to start the array it works fine, despite still being marked as new. Thats been that way for about a week, but never caused any issues. Last night I had to do a new config because my main pool was claiming it was missing too many disks so the array couldn't start. Except the pool wasn't missing any disks.. The pool labeled "zfs-m2tb" has Unraid claiming it has missing disks when I try to start the array. But there are no missing disks, and both are perfectly fine. This pool has never given me issues at all. The main pool does have one failing disk (sdh1), a replacement is on the way but that has never prevented me from running in a degraded state. And it also has nothing to do with the other two pools giving me trouble. I'm not 100% sure what to do here serverus-diagnostics-20241109-1013.zip
-
I google this at least twice a year to see if there’s been any updates.
-
This has been driving me nuts for a while now, Im currently on the Unraid 7 Beta, but this issue was happening way before that. I have disabled all ad-blocking, tracking protection, etc. I've disabled every plug-in and it still happens. Worst of all it'll often happen when I'm right in the middle of setting up a container, or changing a setting and ill loose all my changes. But it will happen on any Unraid page, Dash, Main, Settings, Docker, doesn't matter. This doesn't happen with anything other than Unraid. Im not sure what else to try. Does the WebUI just not play nice with WebKit browsers?
-
I know I’m bumping a really old post but I would have just ended up asking the same question if I started a new thread.
-
@vampyre_masquerade and @redvers76 do you have Bitwarden installed? I went digging through the JS Console and was seeing thousands on errors related to Bitwarden's autofill script. Set your Safari back to however you normally use it, and then go into your Safari settings and disable the Bitwarden extension. Close all Unraid tabs, and then try opening CA again, it should work this time! You can verify this by turning the Bitwarden extension back on, and CA will stop working again. Close the tab, disable Bitwarden, and it will work again. I just did this 3 times in a row before posting here.
-
sorry it took so long to respond, had 2 drive failures the next day. but i'm back up and running now and my cache drive is still getting hammered. I did have caching on, i have since turned it off. and this is my current advanced config section: proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; client_max_body_size 0; proxy_request_buffering off;
-
I have this up and running fine, but Im noticeing that my cache ssd is being absolutely hammered during a large transfer thats going through the proxy. I moved the appdata for npm to a seperate drive thinking it would solve the issue but It didn't. I am transferring several TB of data from my NAS to my Seafile server running on Unraid. You have to use the domain name when connecting to seafile otherwise youll get a CSRF error and no writes will commit. But I am noticeing that my cache drive is being written to non stop the entire transfer, but it's not filling up. Nothing I mentioned is using the cache drive. npm's app data is on a different SSD. Seafile and MariaDB are both on a ZFS pool. The cache drive shouldn't be involved at all other than thats where the "system" share is located. What can I do to get this to stop? That SSD can't handle this.
-
I appreciate the info, I'll keep it in mind though hopefully this doesn't happen again. Unfortunately I lost about 8TB worth of data because of this, no fault of Unraid, it was the HP SAS Expander I was using. In fact despite having 5 "failed" drives (which included both parity drives) Im really happy to see that a majority of my data is still intact thanks to Unraid! Luckily my Intel SAS expander came in today, and it's so far so good!
-
There must be some way to clear the failed status, and just simply add the drive back to the array? I know the drives are fine, it's my SAS expander thats bad. I already have a new one on the way, but I am trying to keep Unraid up until it gets here. Normally the disks just show as missing, and I reboot a few times and I'm good to go. But now disks are randomly being marked as "Failed". Whenever they are marked as failed the only way to get them back into the array seems to be to remove them, start the array in maintenance mode, stop the array, re-add the disk, then re-build the data on that drive. This would be fine if it wasn't multiple times a day when I know there's nothing wrong with the disks anyway.
-
Just like with CUDA in docker containers or LXC, the host OS needs the proper drivers in order for the docker containers to function. unfortunately ROCm just isn’t as popular as CUDA so it makes finding info more difficult. I'm hoping to not have to use a VM for one or two apps when there are prebuilt docker images available with ROCm support.
-
I really wanted to give it a try but the link is broken.
-
Ok so this has been a roller coaster. I rebooted again, Thankfully I could do it from the GUI Mode desktop this time. This time I booted into GUI Safe Mode and I was able to access the WebUI, but one of my drives was missing from the array. This has happened before but a reboot usually fixes it. I reboot again but back into regular GUI Mode. This time everything loads up just like it should, and everything is working again...except now I'm missing 2 disks from my array. But they are Mounted and fully accessible...I don't understand that one at all.
-
My Unraid box has been running flawlessly for almost 2 years now. I did the latest Stable update a few days ago, rebooted and everything was fine. Today I noticed I couldn't access Plex and when I went to open the Unraid UI it wouldn't load, I tried to SSH in and that couldn't connect either. Unfortunately this left me needing to do a hard reboot, this time I booted into GUI mode. The desktop loaded, but the WebUI still wont load. So basically I have no way to access the Unraid UI at all. Possibly related, My array took almost 10min to spin up which is not normal at all. Luckily I have a script that plays a tone when the array comes up or I wouldn't have known.
-
@ich777 ok I managed to figure out the issue. When I first setup the container I needed to add to my config, lxc.cgroup2.devices.allow = c 195:* rwm lxc.cgroup2.devices.allow = c 243:* rwm and I did verify at the time that 195 and 243 were correct. However I have re-created this container several times and tried different distros in-between and for whatever reason it has changed to 195 and 238...I didn't realize that could change. But regardless after manually installing the nvidia driver, manually installing cuda and cuDNN It appears to be finally working!