

bobokun
-
Posts
225 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by bobokun
-
-
Tried a different PCIe slot and I'm still getting the same fault_state error when rebuilding data. Is the only way to rule it out purchasing another Dell H310? How often do these fail?
-
I'm not sure where to find the syslogs after it crashes but I think this is it. Please take a look.
Thank you
-
5minutes after rebooting the server and start the parity check/data rebuild it crashes again.
Please see the logs attachedunnas-diagnostics-20191227-0849.zip
-
Any recommendations going forward to help capture the logs before unraid crashes?
-
I woke up with my whole server not responding, I couldn't SSH or download the logs. So I force rebooted the server and when it came back up my disk5 could had a red x. Please see attached diagnostics.
-
2 hours ago, tazire said:
im getting this
The "X-Frame-Options" HTTP header is not set to "SAMEORIGIN". This is a potential security or privacy risk, as it is recommended to adjust this setting accordingly.
Even with the settings included in the new config file. And strangely when i F12 in chrome on my nextcloud tab it appears to be set to SAMEORIGIN...
comment out the line 38 with #
-
 1
1
-
-
1 hour ago, almulder said:
LOL yep that was it, that's what I get for copying and pasting from the nextcloud site, they have it with a $ bold note section, but without it in the file section. Thanks!
Also it seem to run twice as fast not with the changes. not instead of 10-20 seconds delay when switching screens it like only 5 or less.
")
Did you have you change anything in your appdata\nginx\site-confs\default or was it just from appdata\nextcloud\site-confs\default? I tried to follow the config as well and this is what I tried changing it to but it doesn't seem to be working. Can you see if I did anything wrong?
Old Config:
location / { rewrite ^/remote/(.*) /remote.php last; rewrite ^(/core/doc/[^\/]+/)$ $1/index.html; try_files $uri $uri/ =404; } location ~ \.php(?:$|/) { fastcgi_split_path_info ^(.+\.php)(/.+)$; include /etc/nginx/fastcgi_params; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; fastcgi_param PATH_INFO $fastcgi_path_info; fastcgi_param HTTPS on; fastcgi_param modHeadersAvailable true; #Avoid sending the security headers twice fastcgi_pass php-handler; fastcgi_intercept_errors on; }New Config:
location / { rewrite ^ /index.php; } location ~ ^\/(?:index|remote|public|cron|core\/ajax\/update|status|ocs\/v[12]|updater\/.+|oc[ms]-provider\/.+)\.php(?:$|\/) { fastcgi_split_path_info ^(.+?\.php)(\/.*|)$; try_files $fastcgi_script_name =404; include /etc/nginx/fastcgi_params; fastcgi_param SCRIPTFILENAME $document_root$fastcgi_script_name; fastcgi_param PATHINFO $fastcgi_path_info; fastcgi_param HTTPS on; # Avoid sending the security headers twice fastcgi_param modHeadersAvailable true; # Enable pretty urls fastcgi_param front_controller_active true; fastcgi_pass php-handler; fastcgi_intercept_errors on; fastcgi_request_buffering off; }-
1
-
-
I hope this it the right thread to ask but I've been trying to create a script to change the throttle speeds of my upload. Does anyone have any experience with this? Right now after some investigating the only way I managed to get this to work is to change the lines for download_rate and upload_rate in rtorrent.rc and restarting the docker container. The end goal is when people are streaming remotely on my plex server I want it to dynamically adjust the upload rate in my rutorrent and adjust it back when nobody is streaming on my plex server. I've tried to follow this guide to adjust it through the throttle.php plugin but it doesn't seem to change in the WebUI. https://www.seedhost.eu/whmcs/knowledgebase/245/rTorrentorruTorrent-limit-uploadordownload-speed.html
-
When adding a drive to Unraid it clears the drive before adding it to the array. I'm seeing a few Buffer I/O Errors in the log while it is clearing. Is it still safe to add to the array? Prior to adding this drive I did a SMART extended self-test that resulted in no errors.
Example errors:
Oct 3 07:19:11 unNAS kernel: Buffer I/O error on dev md5, logical block 0, async page read Oct 3 07:19:13 unNAS kernel: Buffer I/O error on dev md5, logical block 1953506608, async page readPlease see attached diagnostics. Thank you!
-
13 hours ago, jbartlett said:
That's correct, my utility only does non-destructive reads. If you want to identify if Disk 4 has issues and remove the Parity drive from the equation, carefully recreate your array without Disk 4. The parity rebuild speeds will tell you if the Parity drive is the issue. If it looks good, mount the old Drive 4 using the UD plugin and copy files to it to see if you can duplicate the slow writes.
While the Parity is rebuilding, you can also kick off a long SMART test on the old Drive 4. If everything still looks good, take the array offline and kick off a long SMART test on the parity drive and all of the others for a shiz-n-grins sanity check.
I did as you suggested and I created a new config, removed both Disk4 and the old Parity drive to rule out all bad options. I put the new parity drive in that has successfully passed preclear at 180-200MB/S. Now when I start the array and it is rebuilding the parity it's extremely slow! I don't think it's the drives anymore because the new parity drive was precleared super fast. Do you think it could be my SAS HBA card? I have the Dell PERC H310. If it's not that then it might be the miniSAS to sata cables that I'm using. Either way now I'm at a loss once again what I should do. I purchased some new miniSAS-Sata cables and hopefully that helps.
EDIT: I powered off my machine and decided to use just normal SATA cables for all 5 drives instead of using the HBA card. So now all my drives are plugged in using SATA cables to my motherboard. Parity drive starts rebuilding started off slow at 19MB/s-30MB/s but after couple minutes it ramped up to 126MB/s.
I just realized my HBA card is plugged into a PCIE 3.0 X4 (In x8) slot. I'm not sure if I need to plug it into a PCIE 3.0 x8 slot would that help?
-
3 minutes ago, jbartlett said:
That ... that is weird. I've never seen anything like that. Even if every other drive was being pounded at the same time, you wouldn't see something like this.
Your Tunable's won't affect it because it doesn't go through the unraid driver to access, it's a straight dd read using a block size given by the drive as being the optimal size.
The drive might not be bad. The only thing I can think of is to try pinning some CPU's to the docker to see if it cleans it up if it happens again. I'm also assuming that you didn't have any CPU intensive tasks going on or no VM's taking all the CPU's away.
I don't think it's the DispSpeed utility that is incorrect because the past few months my parity checks have been extremely slow (fluctuating between 3.5MB/s to 50MB/s) and now when I try to do a parity check it runs at 150-200MB/s full speed with no fluctuation. Should I still replace the parity just in case? I think the read speeds are fine but write speeds still seem to be slow because when copying from cache drive to disk4 it is writing at 30MB/s. From my understanding DiskSpeed doens't test for write speeds only read.
-
I'm hoping some of you guys might have some insight on what is going on. So I ran the DiskSpeed test multiple times on all my drives but constantly it showed my Parity and Disk4 was very slow. This caused my parity checks to double in length the past few months because it would slow down to 3.5MB/S for hours and then ramp back up to 150MB/S. I figured I would need to replace both the Parity and Disk4. I started to preclear a new 10TB drive that I was planning on replacing my parity with and move all the contents from disk4 to disk5 so I can shrink the array. After waiting a couple days to move everything from disk4 to disk5 (remember it fluctuates from 3.5MB/s to 50MB/s max.. even with turbo write on), I finally have Disk4 empty. Before I send it back for RMA I decide to do a diskSpeed test one last time...shockingly all my drives are now running at full speed and I'm not even sure if I need to replace my Parity or disk4 anymore...Does anyone know the reasons why this might be the case? I'm afraid that it could be because Disk4 is currently empty and once Disk4 is no longer empty it will start to slow down dramatically again.
The differences I can only think of is (I ran DiskSpeed without any other docker containers running.) I thought this could be the reason so I started up all my docker containers and re-ran the tests. It still ran at full speed.
Another change I did was change the tunables in Disk settings from
Tunable (md_num_stripes): 1xxx to
Tunable (md_num_stripes): 8192
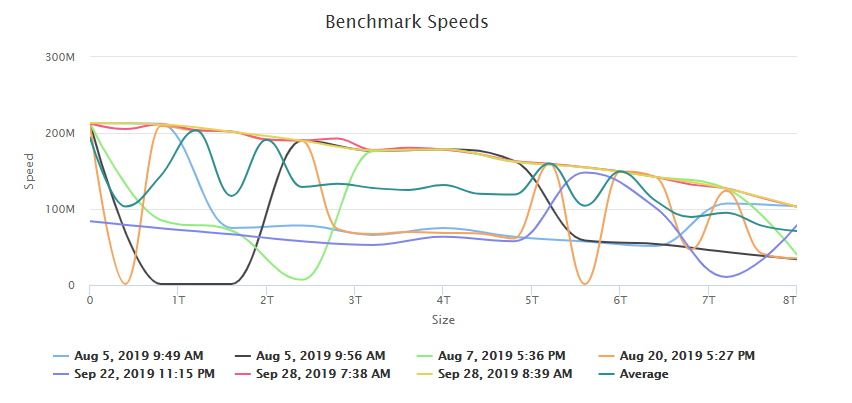
Here are the results for Disk4 and Parity.
Disk4:
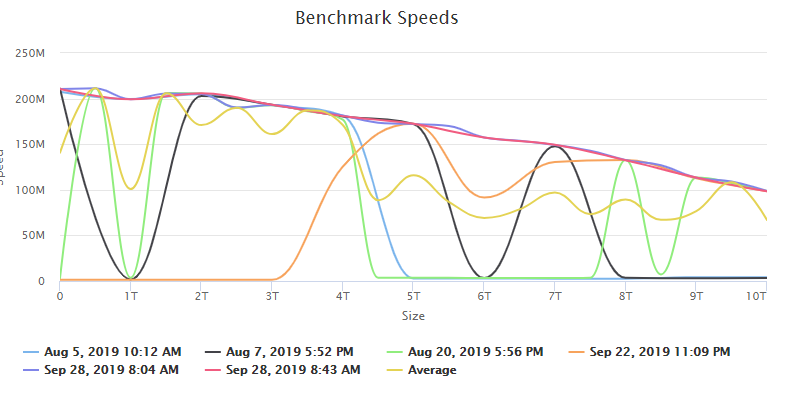
Parity:
-
Thanks, is this the best way to shrink my array and remove the disk?
https://wiki.unraid.net/Shrink_array
-
Hi I'm trying to shrink my array because my disk4 is acting really slow based on diskspeed docker so I was planning on RMAing the disk. I've moved all the contents out from the disk4 so it shows up as empty but it still says there is 8GB of used space and I have no idea what it is. Is it safe to remove the disk?



-
I'm seeing these in my logs recently. Has anyone ever encountered this error or know how to fix it? I tried searching on Google but I'm not sure what the problem is...

-
Should I post on the support thread of binhex-plexpass instead? Since that is the plex container I'm using.
-
6 hours ago, bonienl said:
Did you reboot your system after uninstalling the plugin?
Unfortunately it still persists after reboot as well. (I've attached new diagnostics of logs)
-
No, I will try that. thanks
-
On 9/25/2019 at 2:25 PM, bonienl said:
The plex errors come from the wrong crypto library installed.
Remove the DevPack plugin, it installs the wrong version.
I'm still receiving the same errors after uninstalling devpack plugin. I tried restarting Plex container but that doesn't help. Is there anything else I need to do to get the right crypto library install?
-
Okay I suspect that there could be a virus on my parents PC that could be trying to connect to my unraid server. Any idea about the plex related errors? Is that also connected?
Sep 25 13:28:31 unNAS kernel: traps: Plex Media Scan[21984] general protection ip:15421f94d097 sp:154213c38fe0 error:0 in libcrypto.so.1.0.0[15421f83c000+204000]
-
10.0.0.10 is the internal ip address of my unraid server.
10.0.0.21 is my parent's PC. They are not tech savvy at all and I doubt they would know how to connect or try to connect to the server. I asked them if they were using the PC at 13:17 and they were but they were just transferring files through SMB fileshare to my unraid server that I had already saved credentials for. I asked if they had tried to enter in any username/passwords but they denied anything.
-
no it shouldn't be accessible outside... I have changed the port for my webUI to http port 81 and https 443 but I don't have it port forwarded. Is there any way I can check?
-
I'm seeing a lot of these errors in my logs and I'm not sure what they mean or what I should do. Is this something I can safely ignore?

-
Okay good idea. I'll wait until the rebuild is finished. Swap the sata cable and do another preclear









Disk 5 Error state
in General Support
Posted
Unfortunately I don't have another HBA on hand. I'll probably buy another one from ebay. I heard there are a lot of fakes and perhaps the one I purchased was a fake since it was cheap and I flashed it myself.