




FraxTech
Members
-
Joined
-
Last visited
-
I keep getting an error when trying to copy data to my server or do anything with my dockers. I looked at Fix Common Problems, and I'm seeing "Unable to write to Cache - Drive mounted read-only or completely full. None of my drives are full and I don't know why they would be read-only. I have attached a copy of my diagnostics below. Thanks for your help!! epcot-diagnostics-20250113-1856.zip
-
I have an APC UPS connected to my unRAID server. I have it configured to shut down my server properly, and it works, but I cannot figure out how to have it shut down my Ubuntu VMs before the server shuts down? I had a power outage this morning and I lost data on one of my VMs because it didn't shutdown properly, but unRAID did. I'm not very strong with Linux, so if there is a guide I can follow, that would be great. I've tried searching, but I haven't found anything that has been helpful. Thanks for your help, all!
-
Is it normal for this to lock up the web GUI when the backup is running? I started it about an hour ago and since then, I can't access my server via the GUI, but I can SSH into it and when running htop I see that it is pinning the CPU usage at 100 (though only on a single core). I can still access my shares from other systems, and my dockers are still working (my MineOS server and OpenVPN are still running anyway), but I can't access the GUI. Was just wondering if anyone else has experienced this issue? I'm going to let the backup run overnight and check back on the server tomorrow. Thanks for any input you guys can give. EDIT: This has now been running for 14 hours and continues to peg the CPU at 100% load and I am still unable to access the unRAID GUI. Still wondering if this is normal? Should I let it continue or should I hard reboot the server (as I've tried killing the process and can't seem to kill it)?
-
I was able to resolve my issue. If you have bonding enabled to allow multiple NICs to work together, you have to set Key1 to "bond0" (or whatever the connection name is). After doing this, I was able to get into the GUI w/ no issues.
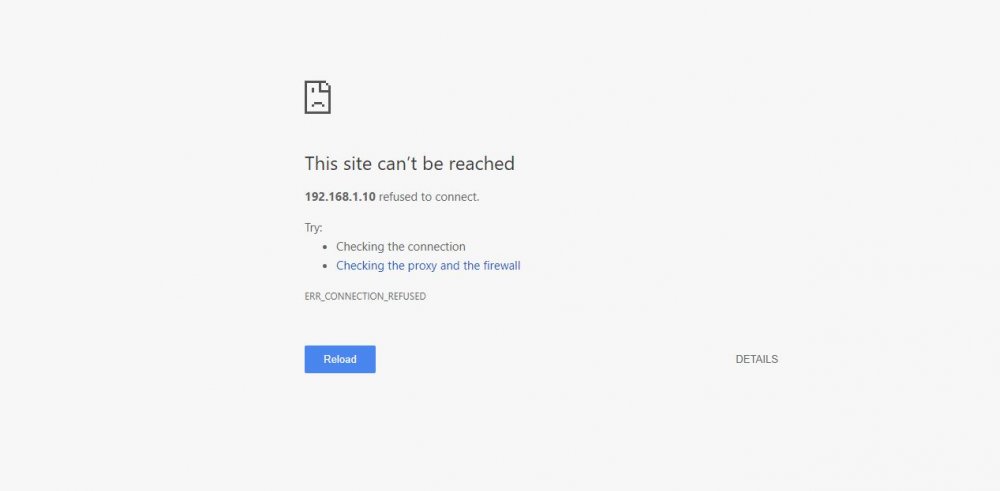
-
Hey all, I'm trying to set up OpenVPN on my unRAID server, I'm following the video from Spaceinvader One (here), but when I try to open the WebUI I get the page below (The site cannot be reached) and I'm hoping you guys can help me out. Sorry, I'm very new to unRAID and I've never used any type of VPN except what I use for work. Any help would be greatly appreciated. Thanks.
