brianbrifri
Members
-
Joined
-
Last visited
Everything posted by brianbrifri
-
So, I ran memtest86 and got 1 good pass from it. Too impatient to run more. I was able to boot into unraid with fresh-ish configs (all but plugins). Server is now rebooting quite often, 5 minutes or less. I pulled G1 and H1 RAM sticks just now since they are part of the same channel to see if that helps. Any chance this could be PSU related? I'm not getting any IPMI errors about it.
-
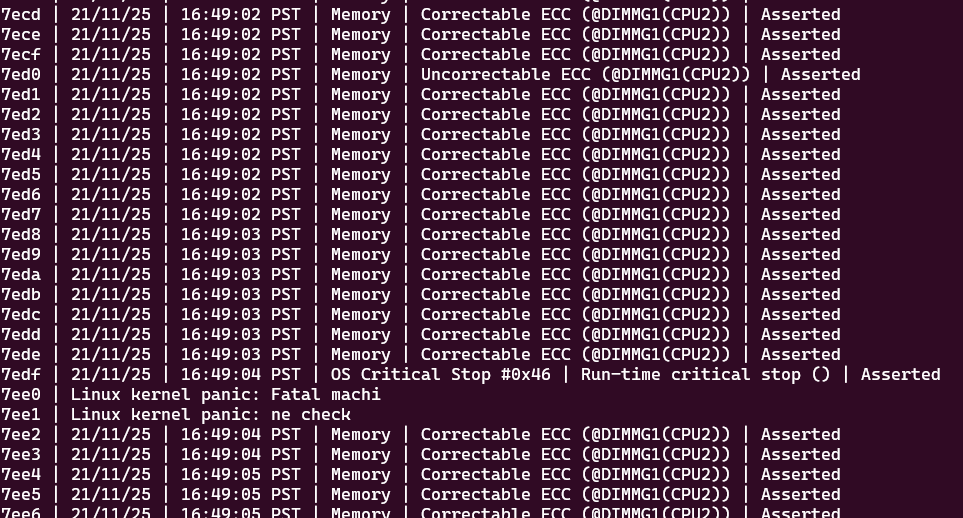
@JorgeB I know this is technically unrelated to the posted issue, but one of the reasons I've been needing to boot is due to random server reboots. I'm able to get the system event log and this showed up: Would bad memory cause a reboot? Unraid has been rebooting within a minute or so of fully booting up from a clean install. However, the server does not reboot while in bios. Currently running memtest86 but no errors so far through 32%.
-
Yup, doing that now.
-
Yup. I'm doing it again to double check.
-
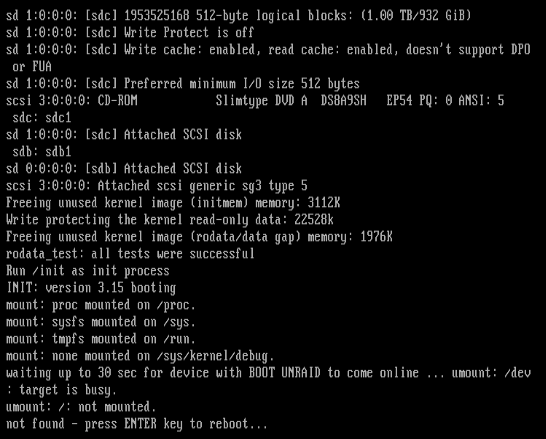
Sorry for the late reply. I'm able to boot into Unraid on a fresh install. I was also able to boot into Unraid the first time after a fresh install + copying over my config folder. I was only unable to boot into Unraid after my server restarted a couple times. What would this tell me? What kind of config would cause an issue like this?
-
I've been having an issue recently on both 7.1.4 and 7.2.0 where my server would restart and then fail to boot. FYI, I'm running unraid on bare metal, a Supermico Motherboard and an HBA SAS Backplane. I've been running Unraid for 10 years on the same hardware and have had my share of issues, but never this one. I have not changed the hardware at all. This started happening after I had been on 7.1.4 for a long time. I even migrated Unraid to a new USB thinking there was an issue with the old one not being recognized. I honestly don't see a lot of info about this error. I found one post in the virtualization forum but I don't think that's the same issue. I have 8 HDDs for my array and 2 SSDs for my cache. Any help pointing me in the right direction would be appreciated.
-
I realize that overseerr hasn't been updated in a while but it finally got one 3 days ago. How long can we expect to wait for the build pipeline to pick up the changes and push out the new version? Thanks!
-
Reboot worked for me too
-
NOOOO I have about the same uptime I'll try upgrading to see if that helps. But ya, it's definitely NOT a networking issue on my end as I proved I can reach both aws and github from unraid.
-
Nope. I am running pi-hole but I changed my unraid server's DNS to OpenDNS and Google in Unraid's network settings as a test and still got that error. Also, I'm not getting any blocks in the pi-hole logs when launching CA. EDIT: Again...was able to pull CA from the CLI of Unraid's terminal ... Gotcha. Wasn't sure how it all worked, was just trying to do some investigation and provide as much info as possible.
-
Current status: The output of md5sum Apps.page and what was in the ca.md5 file for the Apps.page entry did not match. So, I updated the ca.md5 file to contain the output of md5sum Apps.page I'm still getting the "Download of appfeed failed" error. However, the hashes now all check out according to the logs (attached here). I was also able to download both s3.amazonaws.com and raw.githubusercontent.com URLs via wget from my unraid terminal shell, so it's not networking that's the issue. I also downloaded the latest Apps.page file from github wget https://raw.githubusercontent.com/Squidly271/community.applications/master/source/community.applications/usr/local/emhttp/plugins/community.applications/Apps.page then ran diff Apps.page Apps.page.1 and got an output of 5c5 < Code="e942" --- > Code="f0db" 1184c1184 < confirmButtonText: "<?tr("OK")?>", --- > confirmButtonText: "<?tr("Install")?>", So it doesn't look like there's any real difference in my version of Apps.page with what's on master. CA-Logging-20220812-1407.zip
-
I'm having the exact same issue for a while now as well. MD5 failed for ./Apps.page ONLY. Currently on Unraid 6.9.2 and CA version 2022.07.26 Any thoughts on how to fix? EDIT: Reinstall of plugin did not help.
-
Yup. Looks like it was a Plex specific issue and not a docker build issue. Remove the tag for the specific version and apply (if you rolled back to the previous version) and then check for updates (those who have not rolled back to the previous version just need to do this). Latest version fixes the issue.
-
I think something is just broken with that build
-
That worked. Weirdly it seems that version is actually the same as the latest version, which I assume is having issues.
-
Are you able to roll back to a previous version?
-
Hello, I just updated to the most recent docker version: Container ID 04de605cabe4 and am getting errors: Plex Plug-in [com.plexapp.system]: error while loading shared libraries: libpython2.7.so.1.0: cannot open shared object file: No such file or directory 2019-08-26 11:15:29,351 DEBG 'plexmediaserver' stderr output: Plex Plug-in [com.plexapp.system]: error while loading shared libraries: libpython2.7.so.1.0: cannot open shared object file: No such file or directory 2019-08-26 11:15:29,357 DEBG 'plexmediaserver' stderr output: Plex Plug-in [com.plexapp.agents.htbackdrops]: error while loading shared libraries: libpython2.7.so.1.0: cannot open shared object file: No such file or directory I've researched the error online and most common fix was to export LD_LIBRARY_PATH=/usr/lib/plexmediaserver. I added that to the docker config but the errors still persist. Any thoughts on what might be the issue?
-
That's it. Nothing in options
-
I run it with Nord VPN just fine. Use custom VPN provider from drop down
-
Yup, I'm thinking it was a isp or VPN issue
-
Mine works with VPN now too....no shaggy what's going on here either.
-
Hmmmmm was able to get it to work by disabling VPN. I didn't work with it disable last time but I just upgraded my unRAID version to 6.6.6. Will try messing with VPN stuff then report back
-
@binhex Here is my supervisord.log file (I removed sensitive info and cert stuff only) supervisord.log
-
Sad other people are having this issue too but also good to know that it's not just me.
-
Hello, After the most recent update the binhex-sabnzbdvpn docker container is not available. The logs do not seem to indicate anything wrong but I cannot pull up the UI and my services cannot connect to the application either. I have changed nothing other than updating the application. Here is the link to the pastebin for my logs on a fresh startup. Also attached is my docker config. Any help would be appreciated. EDIT: Tried recreating from scratch and am getting the same behavior. EDIT2: Tried turning off privoxy and strict port forwarding. Also changed vpn servers. Still the same behavior