




BioHazardous
Members
-
Joined
-
Last visited
-
I've been running my Minecraft server with this docker for a few years now without issue. Unfortunately when trying to switch from 1.21 to 1.21.3, it stopped loading the server. I couldn't access logs either, I'd click them and they'd pop up for a second then disappear basically instantly. I tried combing through log files in the docker but found nothing relative to the crash, not sure where else to look for logs to determine why it won't load past 1.21. I updated the docker container today as well, and then edited the version number variable from 1.21 to 1.21.4, and same thing as 1.21.3, simply won't load. Switched back to version 1.21 and works again. I'm at a loss as to where to look for variables to play with since I can't get the normal log roll to show. Thanks in advance!
-
I don't have any issue with what I'm currently using for a video card for transcoding Plex media, but curious if anybody has ever used any of these types of specific media decoder devices: https://www.anandtech.com/show/18805/amd-announces-alveo-ma35d-media-accelerator-av1-video-encode-at-1w-per-stream Sounds pretty sexy if you were going to have a lot of concurrent users. Though I'm probably missing some glaring detail about how these devices aren't supported with our current configuration/version of unRAID. And I'm aware that AMD video cards don't work with Plex for transcoding.
-
One person had suggested that the issue was with codecs folder needing to be deleted and restarting the docker. Another guy said that temporarily fixed it but the permanent fix was to increase the number of directories Linux can monitor: https://forums.plex.tv/t/increase-the-number-of-directories-linux-can-monitor-notify/209156 That ones a bit beyond me, though I understand what they're saying, just not sure how to do that in a docker environment to make it persistent every time you restart the docker.
-
So yeah, this is the same issue I've seen before, and I've resolved it by simply selecting an audio file from the dropdown list other than TrueHD 7.1. So if I choose AC3 5.1, I don't run into this issue. In my docker logs in unRAID, I can see the error: decoder error: 121 TrueHD processing failed with 121 I don't however know WHY this is happening.
-
Did you ever get this figured out? @ammonrose or @TheOnly2wo ? I'm currently running into this issue as well, the audio cuts out while playing, and I check the logs and it's nothing but thousands of entries of this kind of stuff: Dec 27, 2022 20:43:06.085 [0x1548a2067b38] ERROR - [Req#e246207/Transcode/0b4c5fa62db6db55-com-plexapp-android/a3067125-0186-4238-adea-8a6a03c5e1ab] Error while decoding stream #0:1: No space left on device I've had no issues streaming and transcoding locally to my stuff in my house, but outside of my house, other people are reporting audio issues, and I was able to replicate it on my phone connected to just 5G instead of WiFi. I'll note the media file in question I'm testing this with is defaulted to TrueHD 7.1 for audio, so unsure if it's related to that or not. I know I've seen issues in the past related to the audio codec/format for the default audio file, and switching to AC3 would fix other issues I've had in the past. May fix it here as well, but that's not really a fix in my view of things, just a work around.
-
So it turns out it was the HDD, probably the logic board on it or something. I received the replacement HDD from WD and it ended up working. Though it scared the crap out of me because I tried putting it in my Windows system before taking my unRAID server down to test it there, and it would BSOD my Windows machine instantly every time. Whether plugged in directly, or through my USB external drive dock. Regardless, though, I tried it in unRAID, and no issues adding the replacement drive. Glad it wasn't me this time though. I just figured I was doing something wrong.
-
@JorgeB Thanks for taking a look at the logs and helping me make sense of what to troubleshoot. I tried a new cable and port, no change. These are two ports on an add-in PCI-E to SATA card that I've never used before, the original cable plugged in was known to be good as it was used with my cache drive that I shuffled to a different location (just kept the cable in the same place to not have to re-fish it through). I'll try getting a new PCI-E to SATA card and testing that out. If that fails, then I'll have to assume it's something with the drive I guess and have WD RMA it. I'll post updates after I get the new card shipped, installed, and tested.
-
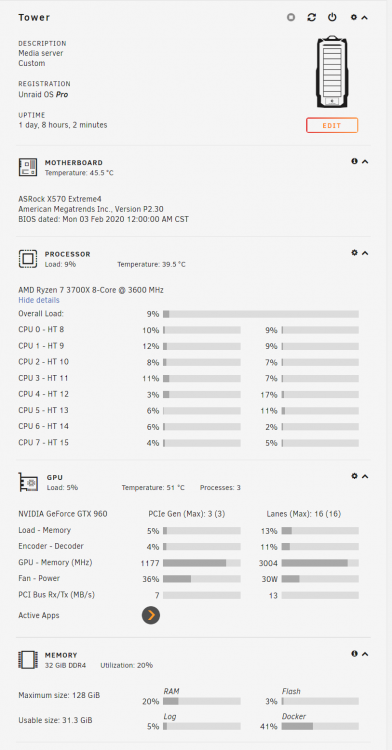
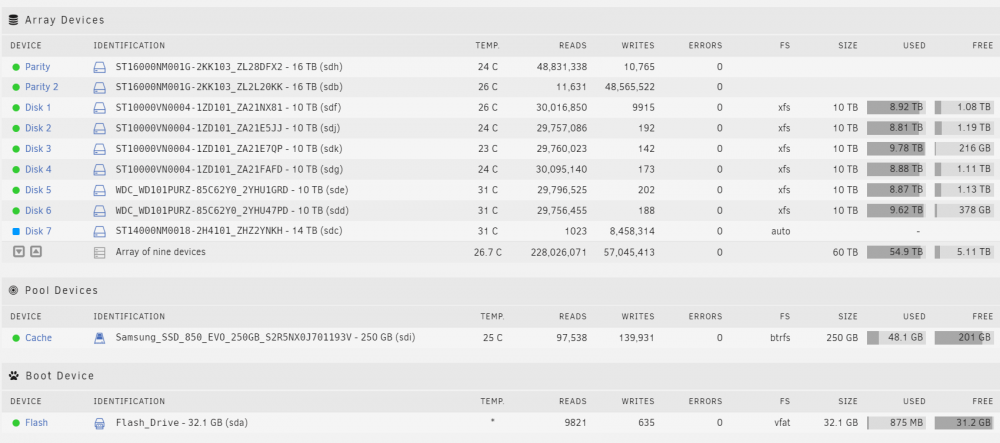
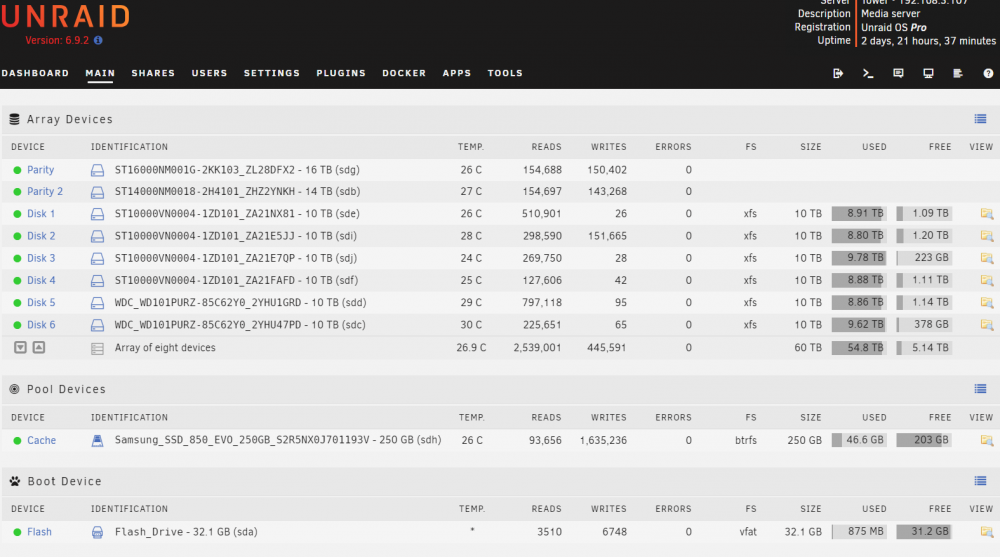
Bought a new 20TB WED Red NAS drive and seem unable to do anything with it. It shows up in unassigned devices, I see the format button, I format it, it says it was successful. Then I stop the array, select it from the drop down to add to parity, it disappears. I restart the array, it shows up still under Unassigned Devices grey status instead of green, then instead of the format button I get a No Array faux button. I downloaded the diagnostics, but I have no idea what it's actually saying about the drive. Sure I can find where it shows errors, but not sure what they mean or what to do to address them. Hoping for some help from the community since somebody is probably reading this thinking "you n00b, you need to do blah first". tower-diagnostics-20221205-2323.zip
-
Maybe something like this for another tower: http://www.phanteks.com/Enthoo-719.html
-
This is pretty awesome! Was just trying to browse to see if there was like a cool rigs section or something to see what people have accomplished with their unRAID setups. I have to start planning for the future, and I'm not sure another tower is the right answer, so may look at some sort of server chassis like you've done.
-
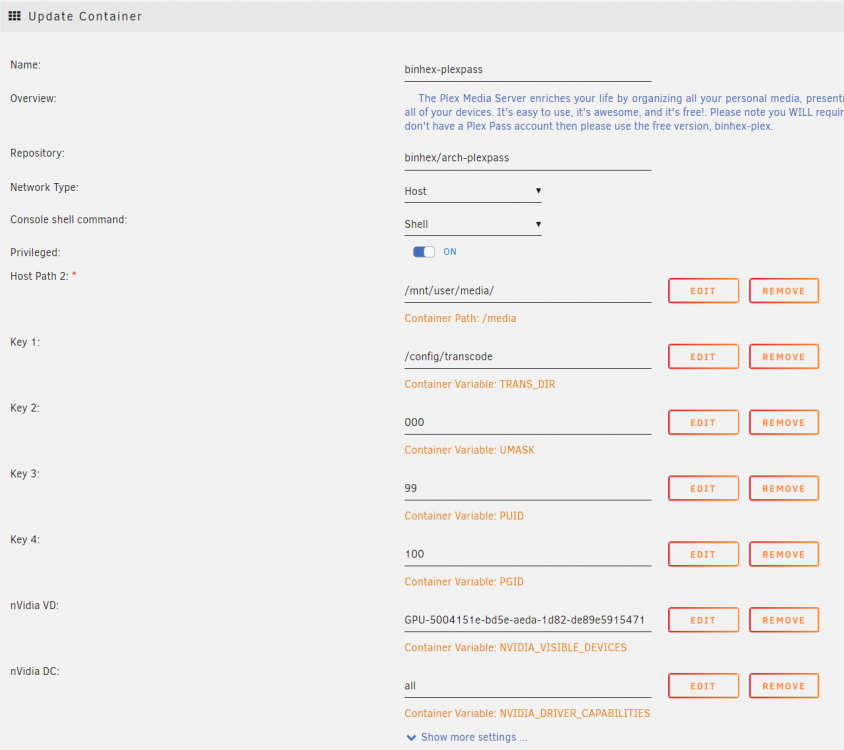
Sorry if this has been covered somewhere already. I've spent a few hours now doing different searches on Google trying to find something related to my issue, but have yet to find anything meaningful. My biggest issue with troubleshooting is I can't seem to get any of the crash report .dmp files as the folder for it is always empty. I'll start with the issue. One of my users started reporting an issue with playback. He was just getting a playback error "an unexpected playback problem occured". On a different device, he got an Error code: s1002 (Network). I was able to reproduce a crash with trying to play the same media file locally once I got home and on my network. So doesn't seem like it's network related, also other files play fine. It's just a handful of files that appear to be an issue. Transcoding is taking place on my GPU without issue for other media files as you can see in the image above. Yet in my logs I did find this one error that seemed possibly of interest "ERROR - Error creating directory "/transcode": Permission denied". A screenshot of my container settings below: Everything for the most part has been working fine for years. Only in the past week has anybody had any issues they've mentioned, and I know I use it almost daily to watch stuff. I don't do any TV recording. I just rip disks and put stuff on my server. I've not had issues with playback of the files/movies in question before. I've attached one of the media server logs from around the timestamp when I had attempted to load the movie Harry Potter and had it crash. Again, the crash report would probably make this a lot easier, but I'm unclear on how to prevent PMS from purging the crash reports so I can grab one of them. Seems like it gets purged the instant it's created as I never see it in the folder the logs indicate it was dumped to. 2021-11-28 12:21:31,466 DEBG 'plexmediaserver' stderr output: ****** PLEX MEDIA SERVER CRASHED, CRASH REPORT WRITTEN: /config/Plex Media Server/Crash Reports/1.25.0.5246-cb2507e4d/PLEX MEDIA SERVER/f3166314-0682-4fa9-bcb06a82-580b4e9f.dmp 2021-11-28 12:21:31,844 DEBG fd 8 closed, stopped monitoring <POutputDispatcher at 22710437100560 for <Subprocess at 22710436647840 with name plexmediaserver in state RUNNING> (stdout)> 2021-11-28 12:21:31,844 DEBG fd 12 closed, stopped monitoring <POutputDispatcher at 22710436850752 for <Subprocess at 22710436647840 with name plexmediaserver in state RUNNING> (stderr)> 2021-11-28 12:21:31,844 INFO exited: plexmediaserver (terminated by SIGSEGV; not expected) 2021-11-28 12:21:31,844 DEBG received SIGCHLD indicating a child quit 2021-11-28 12:21:31,845 INFO spawned: 'plexmediaserver' with pid 7552 Thanks in advance for any insights into how to troubleshoot this issue. Adding a screenshot of my Main page: I got a chance to do some more tests on my server with nobody on it finally. From some random sampling, it appears that the video files have the codec in common of VC1 vs H264 for some ones that worked. Is there some known issue with unRAID or the Plex docker with transcoding VC1 files? Did some more testing and found some more interesting stuff. I tried one person's suggestion of deleting the codec folder in appdata, and it did download a new libvc1_decoder.so file, but no change, still errors on VC1 files. I then tried disabling hardware acceleration in Plex Server > Transcoder settings. I attempted to play Harry Potter again, and no issues starting up. So the VC1 issue seems related to nVidia. I did try updating my driver for nVidia, which hadn't been updated since March, but that didn't fix the issue either. So my assumption is something changed with Plex and how it uses hardware acceleration that broke VC1 encoded files. For now I'll just stick without using my nVidia card to transcode, but hoping we can find a solution so I can go back to using it. 11/30/2021 - Plex responded to my forum post there, and it sounds like they have an update coming out possibly today that should resolve this transcoding issue with GPUs and VC1 encoded media. Will try to keep an eye out for updates to the docker. Plex Media Server.3.log
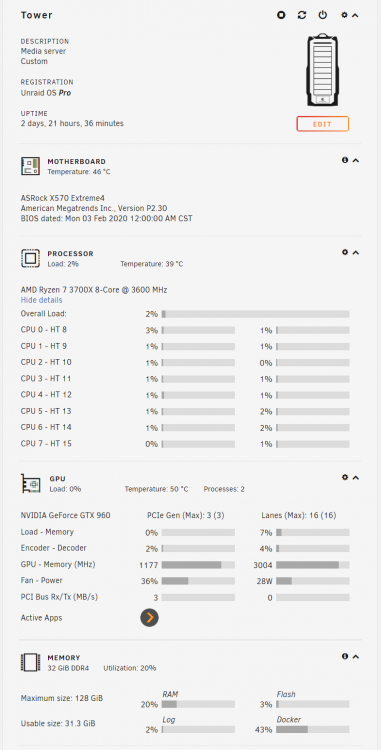
-
No worries! I know this is 100% charity by you with helping out shmucks like me who don't know what they're doing Hope you had a great holiday! So I tried already with the GPU stats to have it pointed to my GTX 960 when I started up the PM docker, and it still didn't get any stats from the GPU. I did not try uninstalling the GPU stats plugin as I had made an assumption about it not interfering with docker's abilities to also read the same info. I could very well be incorrect with my assumption. I believe I was basing it on the fact that the Dyamix fan plug was recommended, and it also puts stats on the Dashboard. So if having stats on the dashboard breaks communication for docker's with key metrics for the health of the physical devices, then I think a lot of docker's that rely on the hardware would inherently be running into a lot of issues. I've since moved the GTX 1070 to a different desktop that runs 24/7 anyway, and it's running at about 26.3 MH/s at 73C. Which seems a lot safer than 79C at 24.x MH/s with no controls over anything. I'm hoping to get another card in the near future and revisit your docker though, and I'll let you know how things go if I get to test it out again. Yours was better than the other mining dockers available on unRAID that I tested. NsfminerOC worked well for controlling aspects of the graphics card, like the memory clock and the like, but for whatever reason, it was only doing like 20MH/s, and despite the correct settings to my pool, my pool never saw my rig after 3 hours of farming. At any rate, this has been a fun past few days playing around with mining. Can't believe I waited this long to tinker around with it. Thanks for all your hard work with this stuff! Oh yeah, also on my list to figure out is CPU mining if I can find a crypto that my Coinbase wallet supports that these different pools support.
-
I think I may have figured out both issues I was facing. Onto the next one. PhoenixStats doesn't show temp or fan speed, and I have a feeling that's why the temp and fan speed aren't being controlled. PhoenixMiner is running privileged. I have the GPU Statistics plugin, and I put my GTX 1070 card on it since I couldn't see anything in PhoenixStats, and it was at 50% fan and 79C, so I shut it down since nothing seemed like it was being controlled with my settings of target temp of 70C, fan min speed of 70%, etc. Here's my additional arguments: -coin eth -worker unRAID -proto 2 -pool2 stratum+tcp://eth-us-east1.nanopool.org:9999 -gpus 1 -pass [email protected] -fanmin 70 My safety temp is 70, stop temp is 79, resume is 76. Oh and my Pool address was the issue before. I had found some link that showed some nanopool settings for PhoenixMiner, and saw they used ssl:// in front of the address, added that, and it worked. Also added my email as -pass. Anyway, it was at 79, and didn't stop running also, so I feel like for some reason, the Docker isn't getting any of the info from the GPU other than it exists.
-
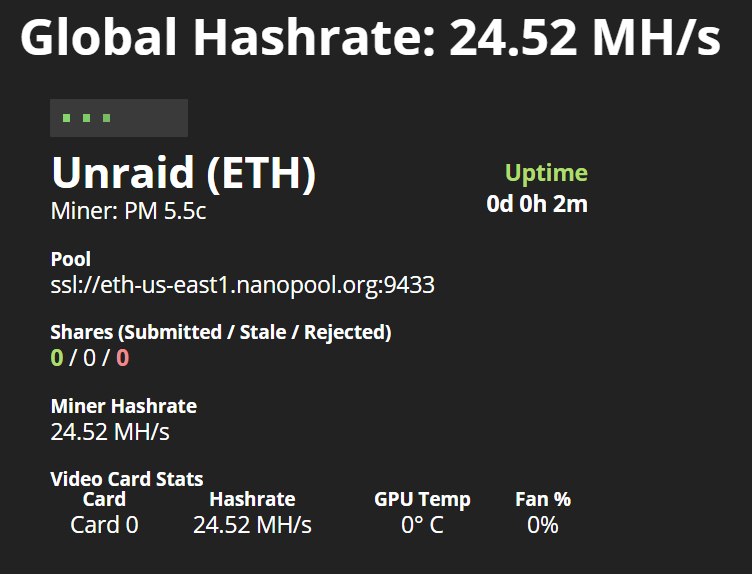
Solved I believe, looks like the default password parameter that gets added as a .x at the end of your wallet ID for my pool is actually used as the mining rig name, and then I added my email address as -pass since that's used as a "password" for my pool with nanopool.org Sorry, one other question. Is there a way to add my email to be passed along? Was just looking into my settings, and apparently I can't change anything without an email address tied to all my workers, just added one to my Windows worker, but don't see what parameter to use with Phoenixminer to do this.
-
Solved this in subsequent post below, leaving this here for anybody else running into the same issue. Can you take a look at my logs and help me figure out why I just get disconnected as soon as I connect, and nothing is happening as far as mining goes? Sorry, I'll freely admit I'm terrible with Linux. I just use my unRAID server for Plex, but I barely know what I'm doing there as well I added a second video card and put in the correct GPU UUID in, and I think I got everything else "correct" but clearly I've bollocksed up something here. After the last line, it just keeps repeating the connection and connection closed. On my Windows desktop, I have nanominer for nanopool installed, and it's running just fine. Figured this would be fairly easy and similar to configuring that, I was wrong it seems Project: PhoenixMiner 5.5c Author: lnxd Base: Ubuntu 20.04 Driver: 20.20 Target: Unraid 6.9.0 - 6.9.2 Wallet: 0x98e8F617DB907aD48F535dCFE49De6E75c154704 Pool: eth-us-east1.nanopool.org:9433 Starting PhoenixMiner 5.5c as uid=0(root) gid=0(root) groups=0(root) with the following arguments: -pool eth-us-east1.nanopool.org:9433 -wal <mywallet>.x -tt 75 -tstop 85 -tstart 80 -cdm 1 -cdmport 5450 -coin eth -worker unRAID -proto 2 -pool2 eth-us-west1.nanopool.org:9433 -gpus 1 Phoenix Miner 5.5c Linux/gcc - Release build -------------------------------------------- [0mCUDA version: 11.0, CUDA runtime: 8.0 OpenCL driver version: 20.20-1089974-ubuntu-20.04 [97mAvailable GPUs for mining: [92mGPU1: NVIDIA GeForce GTX 1070 (pcie 3), CUDA cap. 6.1, 7.9 GB VRAM, 15 CUs [93mUnable to load NVML [96mEth: the pool list contains 2 pools (2 from command-line) Eth: primary pool: eth-us-east1.nanopool.org:9433 [0mStarting GPU mining [96mEth: Connecting to ethash pool eth-us-east1.nanopool.org:9433 (proto: EthProxy) [92mEth: Connected to ethash pool eth-us-east1.nanopool.org:9433 (192.99.69.170) [93mEth: Connection closed by the pool [96mEth: Reconnecting in 5 seconds... [97mListening for CDM remote manager at port 5450 in read-only mode






