




jfeeser
Members
-
Joined
-
Last visited
-
Hi there! I'm having some issues with the Soularr container - i followed the unraid-specific instructions on the github page, but the container doesn't seem to want to start. When i try to start the container, i get the following in the logs, and the container stops again: run.sh: line 2: $'\r': command not found run.sh: line 4: $'\r': command not found run.sh: line 7: $'\r': command not found run.sh: line 19: syntax error near unexpected token `done' run.sh: line 19: `done' Any idea what may be going on? Thanks!
-
Sorry just getting back to this. UI is showing 8.7.1.32.
-
Hi Djoss, I'm running the latest version of the container and I'm still running into this issue. Any idea what could be going on?
-
Hi All, having a bit of trouble with this container...it looks like just about hourly the crashplan instance in the container tries to update itself, and creates a temp file to do so, but then the update fails. That's fine by me, since it's still working, but it leaves the temp update files behind, so after half a day I end up with gigs upon gigs of files like "c42.12976608722313913967.dl" in the /conf/tmp folder of the crashplan container. Is there any way to prevent this from happening, other than setting up a Cron job to delete the contents of the folder? Thanks in advance for your help!
-
Hi all, this morning I woke up to this in my inbox: Event: USB flash drive failureEvent: USB flash drive failure Subject: Alert [FEEZFILESERV] - USB drive is not read-write Description: USB_DISK (sda) Importance: alert I logged into the server and the flash drive is showing "green", and the server appears to be running fine (I remember reading somewhere that the entire OS loads into RAM so that makes sense). I'm also not surprised the USB stick is failing since it's ages old and wasn't exactly a high quality one to begin with. So I ask: What do I do at this point? How do I go about replacing the USB drive? I've attached diagnostic logs for more info for people smarter than me. Thanks in advance everyone! feezfileserv-diagnostics-20220327-0933.zip
-
I just figured it out! It turns out that at least in my case, it was Valheim+ doing it. i had it turned on on the server side when the clients didn't have it installed. For some reason the last version didn't care about that, but the new one very much does. I installed the mod and it worked without a hitch. I'm assuming setting that variable to False on the server side would also fix it.
-
What ended up working for you for getting the update? i've tried turning firewalls off, disabling pihole, everything short of rebuilding the container and so far nothing has worked.
-
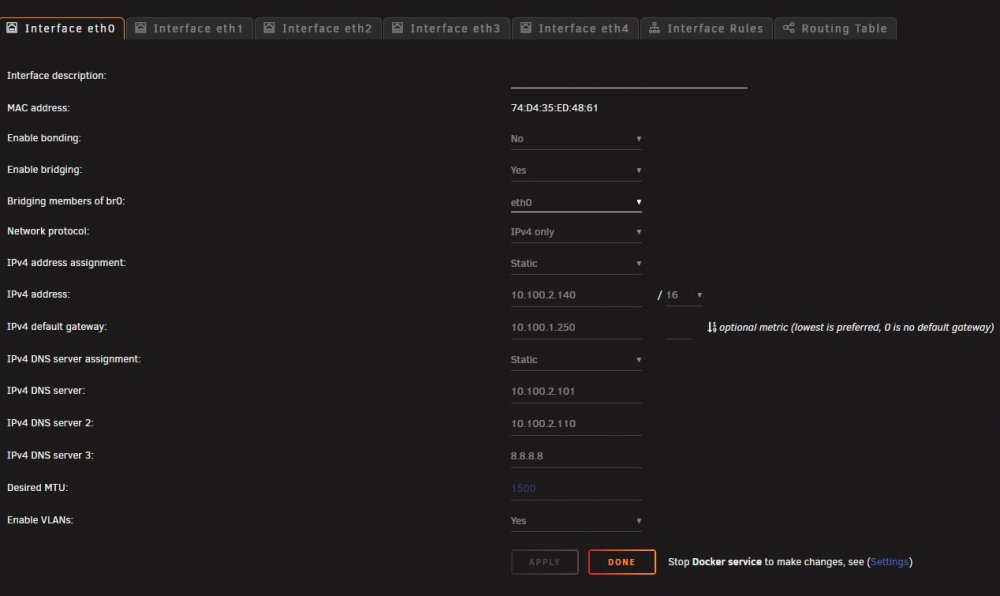
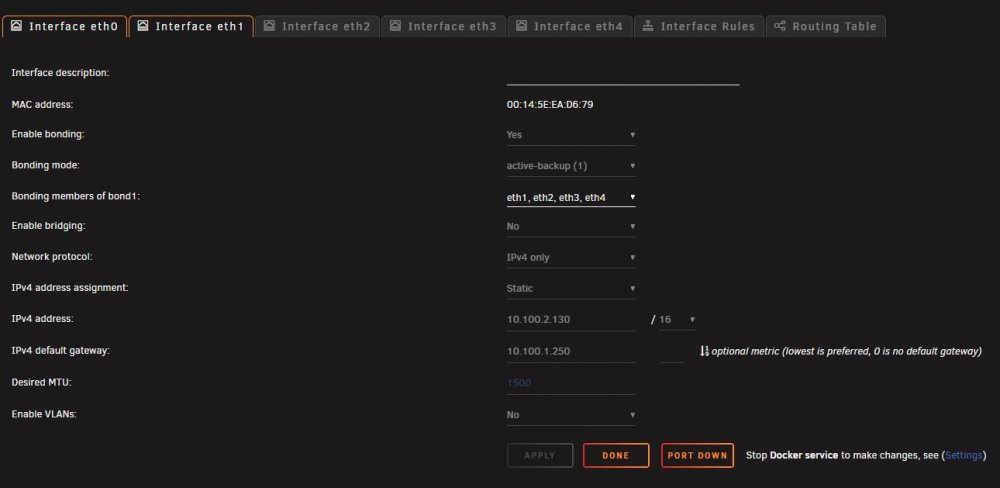
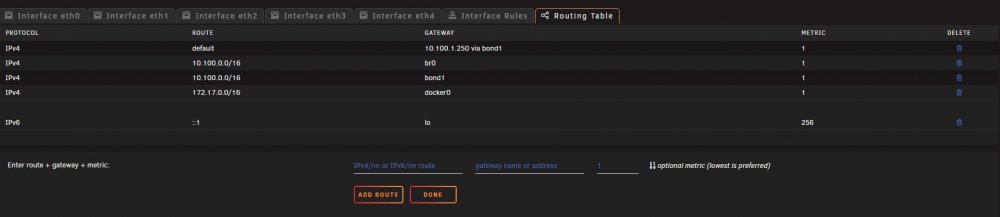
Understood. So ideally i would just bond everything and then use VLANs to separate traffic. That being said, any idea why the bond is stuck in "active/backup" mode? (also love your nick, it's "nicely inconspicuous")
-
Right, the intent of that way i have it would be for eth0 (which is on the motherboard) to be the primary interface for management and docker functions, and then eth1-4 to be bonded for all other functions (file access, primarily). Would that be the correct way to accomplish this?
-
Hi all, i'm experiencing some odd behavior on my unraid server while trying to set up link aggregation. The short version is that when i enable bonding for eth1-4 (4 interfaces on a 4-port addon card) the only bonding mode i can choose is "active-backup". If i choose anything else and hit apply (such as 802.3AD, which is what i actually want to use), it just flips back to active-backup. I've got the 4 ports that they are plugged into set up as "aggregate" on my unifi switch, but the mode refuses to change. Can't seem to figure it out. Attached are screenshots of my configurations, can anyone take a look? Thanks!
-
Hi all, i've been trying to use this docker in my existing setup with the rest of my content stack, but i'm running into some issues. Is it possible to have the docker running on my application server with the library on a separate unraid box that serves as my fileserver. If i use unassigned devices to map the share as NFS, after a while i get "stale file handle" errors when accessing the books. If i map it as SMB (with the docker looking at the share as "Slave R/W") i get errors that the databse is locked. If i run everything local to the application server and keep the library in the docker, everything works fine, but this isn't ideal for me as the app server is pretty lightweight and i'd rather keep the files on the file server where they belong. Any thoughts, all?
-
Not sure if you ever got this done, but if anyone else finds this topic, here's how i did it: 1) Stop the VM in ESXI 2) Export the VM as an OVF template 3) Make a folder on your unraid box called /mnt/user/domains/<NameOfVM> 4) Copy the VMDK file from the export folder to the folder you created in step 3 5) Run the following command: "qemu-img convert -p -f vmdk -O raw <vmdkfile> <vmdkfilename>.img". This will convert the file to the KVM/OVirt format. 6) Create a new VM, change the bios to "SeaBIOS", and choose the .img file created in step #5 for the first hard drive. At this point, if it's a linux machine, you can boot it and it pretty much Just Works (tm). If it's a windows box, you've got a couple more steps. 7) Boot the windows box, let it freak out that there is a bunch of new hardware and attempt to install drivers for it. Let it do it's thing - it'll probably reboot a couple times. 8 ) go to add/remove programs and uninstall vmware tools 9) As part of the creation process, you'll end up with a D (or first available) letter drive with the OVirt client VM files (basically vmware client for OVirt). Open that up, go to the client install folder and install it. Reboot. 10) after the reboot, go to device manager and install drivers for anything that wasn't detected properly. All the drivers you need should also be on that D drive disk. 11) Reboot one last time and you should be good to go! That's pretty much it. The only other snag i noticed is that a couple VMs that i converted that had static IPs flipped back over to DHCP (my assumption is because of the change in virtual network hardware), so make sure to check that. Let me know if you (or anyone else) runs into any issues!




