




Vexorg
Members
-
Joined
-
Last visited
Everything posted by Vexorg
-
Updated to the latest version and getting errors when running nzbToSickBeard.py after a fetch. Traceback (most recent call last): File "/config/nzbToMedia/nzbToSickBeard.py", line 270, in <module> import nzbToMedia File "/config/nzbToMedia/nzbToMedia.py", line 727, in <module> eol.check() File "/config/nzbToMedia/eol.py", line 100, in check warn_for_status(version, grace_period) File "/config/nzbToMedia/eol.py", line 141, in warn_for_status days_left = lifetime(version) File "/config/nzbToMedia/eol.py", line 71, in lifetime time_left = PYTHON_EOL[(major, minor)] - now KeyError: (3, 10) Looks like new version of python is not yet supported? Rolled back to older version and things are working again.
-
I wonder what's the longest gap between reply's but I'd like to add my two cents. I was having problems running Tdarr-node's handbrakecli encoding docker, it would only use one CPU core and therefore take forever to encode. I wanted to test to see if handbrake would work better running on the host machine and not in a docker or vm. I found this thread but being over a decade old I really had no hopes but figured I give it a try and I'm glad to say it does work! I had to tweak some things but you can still get this to work. I'm running unraid 6.9.2. I used https://slackware.pkgs.org/ to find all the missing packages: handbrake-1.5.1-x86_64-1alien.txz fontconfig-2.13.92-x86_64-3.txz freetype-2.12.1-x86_64-1.txz gcc-g++-12.1.0-x86_64-1.txz glibc-2.35-x86_64-2.txz graphite2-1.3.14-x86_64-3.txz harfbuzz-4.4.1-x86_64-1.txz libdrm-2.4.110-x86_64-1.txz libogg-1.3.5-x86_64-1.txz libtheora-1.1.1-x86_64-4.txz libva-2.14.0-x86_64-1.txz libvorbis-1.3.7-x86_64-3.txz ldd Handbrakecli will show the libraries and I would just search for the missing ones and install them.
-
map /temp to /dev/shm /dev/shm is a temp file system that by default uses half your ram. I have 128G and it uses 64G but eats away from total ram as you use it. So if there is nothing in the temp folder I have 128G free but one I start to use it my systems total ram decreases. If the /dev/shm is full i only have 64G remaining for the rest of my system. Also if something goes wrong with tdarr it might leave files in there so you'll have to delete them yourself or reboot your system. Please note if this burns down your house I'm not responsible.
-
I'm back to answer my own question. Seems like I'm a boob and forgot what I did when I first setup this docker way back. I guess I updated this docker and looks like anything that is installed into the docker is lost :( apk add --no-cache ipmitool This is what is needed to install the ipmitool into the docker. To the maintainer of this docker, is it possible to include this program in the base install?
-
Hi all, I'm having a little issue with my telegraf docker. All was running nice and smooth with all types of data being stored in influxdb. After a restart of the telegraf docker it stopped getting temps/fans from my motherboard. I have a supermicro board and I can get the stats using ipmitool. Now in the telegraf log i get: 2018-09-10T05:11:00Z E! Error in plugin [inputs.ipmi_sensor]: ipmitool not found: verify that ipmitool is installed and that ipmitool is in your PATH I checked and ipmitool is still in /usr/bin/ and is executable. My google-fu suggested that the docker needs root access and I think it does. Like I said this all was working before.
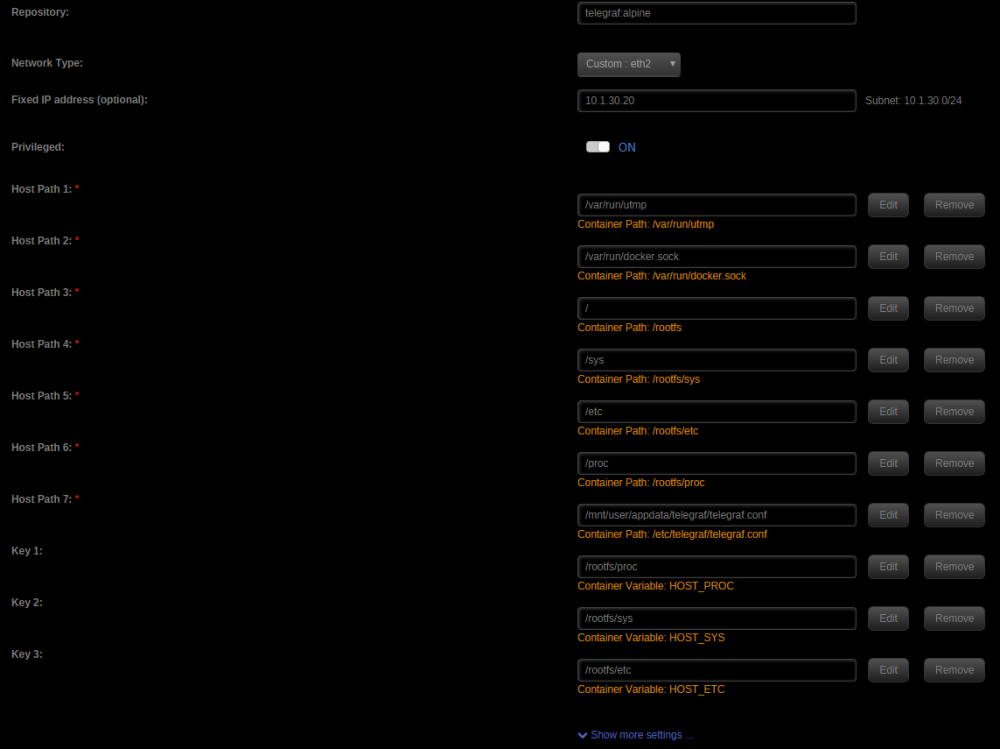
-
I didn't have to do it again. I just had to do a reboot and it seems the setting has suck so far.
-
After a ton of Google-fu I was able to resolve my problem. TL;DR Write cache on drive was disabled found an page called How to Disable or Enable Write Caching in Linux. The artical covers both ata and scsi drives which i needed as SAS drive are scsi and are a total different beast. root@Thor:/etc# sdparm -g WCE /dev/sdd /dev/sdd: HGST HUS726040ALS214 MS00 WCE 0 [cha: y, def: 0, sav: 0] This shows that the write cache disabled root@Thor:/etc# sdparm --set=WCE /dev/sdd /dev/sdd: HGST HUS726040ALS214 MS00 This enables it and my writes returned to the expected speeds root@Thor:/etc# sdparm -g WCE /dev/sdd /dev/sdd: HGST HUS726040ALS214 MS00 WCE 1 [cha: y, def: 0, sav: 0] confirms the write cache has been set Now I'm not total sure why the write cache was disabled under unraid, bug or feature? While doing my googling there was a mention of a kernel bug a few years ago that if system ram was more then 8G it disables the write cache. My current system has a little more then 8G so maybe?
-
Hello all, I've just build a new unraid server and after playing around with a bit before I really start using it I was finding it the drive writes seemed to be a bit slow. I first noticed the slowness while I was doing a badblock run on the new drives and after 50 hours it had just finished the first pass. For 4TB drives I understand it should take a total of 40hours or so for this size of drive. I did not see any errors and killed the process and proceeded to build the array with the drives and when it was doing the parrity build the stated write speed to the drive with 47MB/sec which seemed to me a bit slow for the drives. I checked the spec's from the manufacturer and it said it should be closer to 200MB/sec so I'm getting about 25% of the speed. Next thing I did was boot into windows and ran a few benchmarking tools from there and they all reported read/write speeds about 200MB/sec... I did find that one of the LSI cards was in a PCIe 4x slot instead of an 8X one so I moved it to a new slot. Next try was a live linux USB to see if the problem was with unix after things seem to be fine in windows. Used knoppix and ran a few tests and the drives speeds where in the 200MB/sec again?!? My conclusion is the Unraid distro is the problem and not with hardware. Now for some hardware details of my system: Supermicro x10DRi-ln4+ 2x intel e5-2630's 3x LSI 9211 HBA's connected to a supermicro BPN-SAS-846A backplane 6x HGST 4tb 3.5" HDD HUS726040ALS214 SAS drives root@Thor:~# hdparm -Tt /dev/sdh /dev/sdh: Timing cached reads: 21860 MB in 1.99 seconds = 10970.43 MB/sec Timing buffered disk reads: 570 MB in 3.00 seconds = 189.82 MB/sec root@Thor:~# dd if=/dev/zero of=/dev/sdh bs=128k count=10k 10240+0 records in 10240+0 records out 1342177280 bytes (1.3 GB, 1.2 GiB) copied, 28.5249 s, 47.1 MB/s I'm not really sure where to look at next. thor-diagnostics-20180716-1149.zip



