




Rex099
Members
-
Joined
-
Last visited
Everything posted by Rex099
-
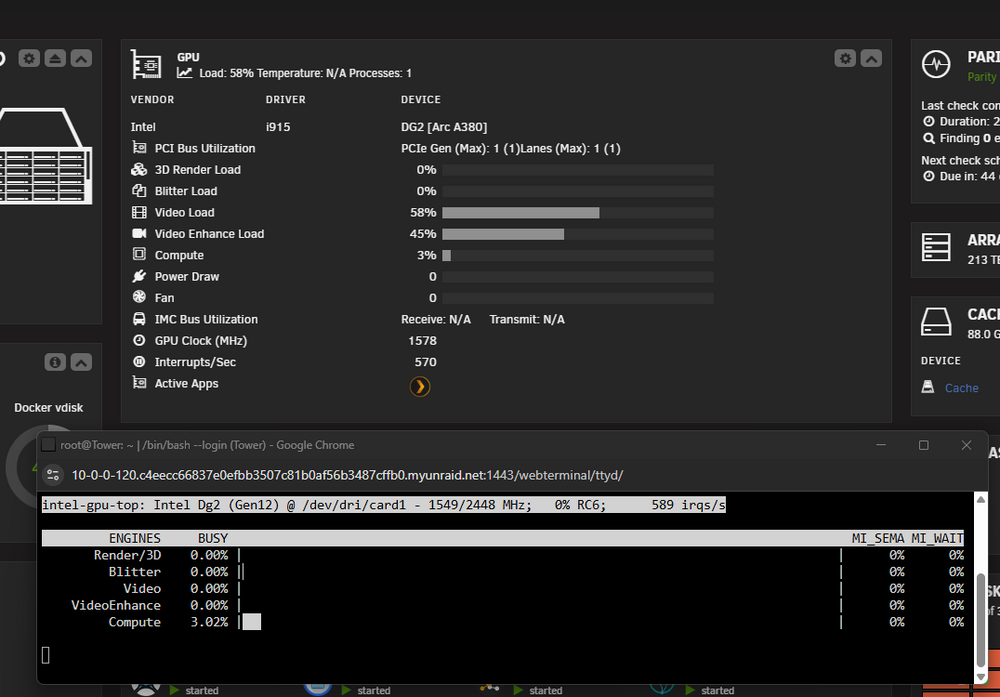
So after rebooting, and running a transcode again I guess it is "working" The fan, power draw, never move from zero. And the PCI BUS info seem incorrect.
-
I have the same issue with my A380 ELF root@Tower:~# ls /tmp/gpudata* /tmp/gpudata0000:84:00.0 root@Tower:~# ls /tmp/gpujson /tmp/gpujsongpujson gpudata00008400.0
-
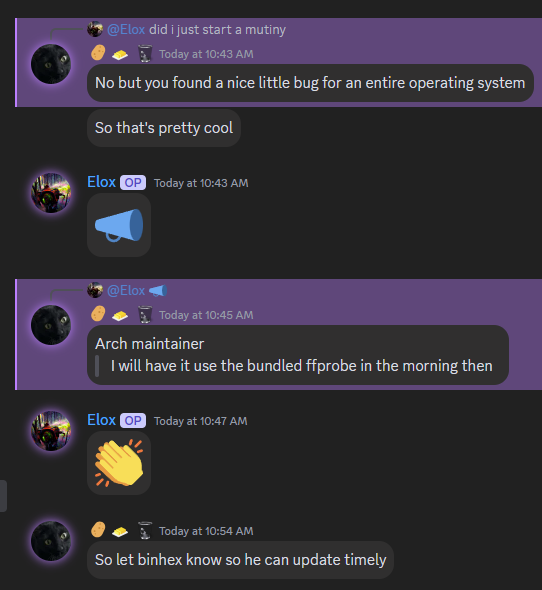
Appears there was an issue with the all the arch arr's not getting the custom ffprob. I reported an issue and was told there should be an update being pushed by the morning.
-
I had already attempted everything in that post, im actually the last comment on the thread Made a post on the plex fourms, it seems its actuallly a player problem not the server. https://forums.plex.tv/t/req-98a-transcode-denying-access-due-to-session-lacking-permission-to-transcode-key/882988/5
-
Still wondering if anyone has any ideas what might be going on here. Still having the same issue with HW Trancode Only.
-
Anyone recently had issue with HW transcoding? (Via GPU, Quadro P2000, also tried Quadro M2000 same result) Not sure what changed, but recently whenever I have HW transcoding enabled and the transcoing attempts My log gets flooded with [Req#115b/Transcode] Denying access due to session lacking permission to transcode key /library/metadata/192259 Then after a few seconds the client session dies with An unknown error occurred (4294967283) Error code: 4294967283 Software transcoding works fine with no issues. For info transcoding to RAM /tmp/plex I've tried changing it back to disk just to check but same results.
-
If i load binhex/arch-sabnzbd it shows "Par2cmdline-turbo:Not available" but if I load binhex/arch-sabnzbd:test it shows its working
-
Will this ever be rolled into the latest tag?
-
Wondering if you even found a fix for this? Whenever I used the action center to update anymore then one docker, I seem to have the same problem. If I update one at a time, it works fine but if I do multiple it says the updates happened but if i click the advanced toggle on the docker tab there will be orphaned images. Then I have to click force update on the individual dockers to get them to straighten out.
-
Posting how i fixed this just in case someone else runs into this. So I still never figured out what exactly the issue was but I ended up backing up binhex-plexpass using the old Backup/Restore Appdata plugin again. Then reformatted plex_appdata as xfs, then again back to zfs (I tried zfs first but it didnt fix the issue, so i had to do xfs first then zfs again). Once I did that I restored from the Backup/Restore Appdata plugin and the ran the spaceinvaderone script and it did a proper full snapshot... what a headache with no clear reason why.
-
Sanity check: In theory if I deleted all the snapshots from both datasets binhex-plexpass and plex_appdata_binhex-plexpass. Then took a snapshot, shouldn't it send a full backup from binhex-plexpass -> plex_appdata_binhex-plexpass when the Spaceinvadeone script runs?
-
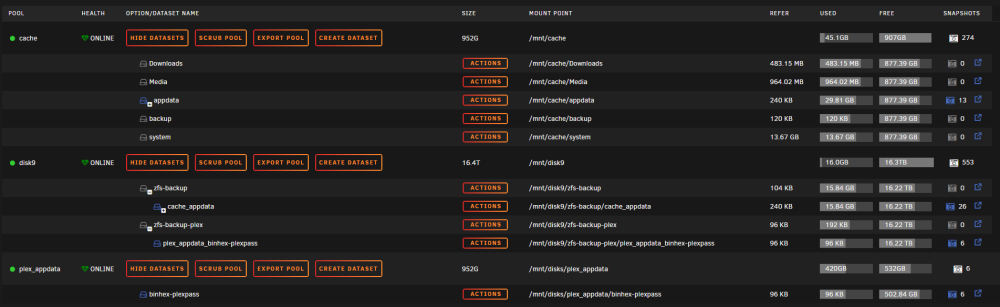
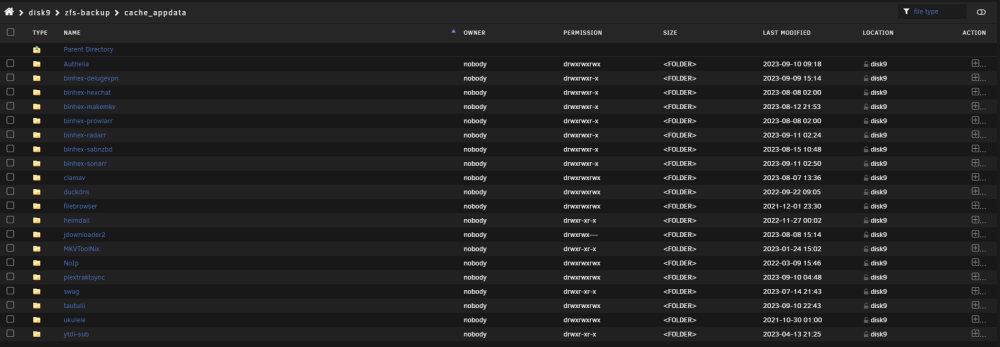
I'm wondering if there is someway to reset the zfs snapshots without deleting a dataset. I have 3 zfs drives, 1 cache and 1 unassigned devices and both of them are replicating to a ZFS drive in my array using 2 copies of spaceinvaderone's script. But i think my unassigned drive which is my plex appdata somehow didn't actually get a full snapshot, even though it says it did. really hard to explain what I mean but ill do my best. Here is my ZFS master My appdata folder from cache seems to be working fine and everything is backed up to the zfs-backup on disk9 with no issues But my binhex-plexpass does not seem to be actually backing up to the zfs-backup-plex, The snapshots say they are getting incrementally backed up but no data is being populated on plex_appdata_binhex-plexpass like it is on cache_appdata Example when i browse cache_appdata i see files But if i browse plex_appdata_binhex-plexpass its empty, like it never got the first full snapshot So im just not sure what I need to do to fix it or even if there is a way to without blowing away the plex_appdata drive and rebuilding again, which i really dont want to do. its something like 420GB of plex appdata which takes a long time to build.

-
Just just seemed to encounter this for the first time today. I installed the Dynamix Share Floor plugin which modifies the Minimum free space value. but just as noted in the other posts, if I modify any of the export settings(even if you just change it and change it back then save), the message goes away.
-
Not really sure what i'm looking for, or what this means but line 1343 of the syslog: Feb 22 02:46:36 Tower kernel: mce: [Hardware Error]: Machine check events logged Should i be looking elsewhere?
-
So I guess sometime over the past two days I got a MCE error from fix common problems. Attaching the diagnosis log as requested from the plugin. Any help or info would be appreciated. tower-diagnostics-20230227-1441.zip
-
Honestly I'm not sure but I think I recall having a similar problem when I fist setup my instance. I never figured out what was causing the problem, but I just stopped the docker, removed my folder appdata/plextraktsync. Restarted the docker, went to the console, entered "python3 -m plextraktsync" and re-setup the credentials and it just worked. Just figure something in the original appdata folder got corrupted somehow but don't know what. To note, both my plex and plextraktsync are running on host
-
Sorry I never actually figured out what the issue was. But after ~ 3 weeks everything just started working again on its own. I'm still thinking that it was something the ISP was doing but don't have any proof.
-
Wondering if someone might be willing to help point me in the right direction to what is going on with my Issue. As of 3am this morning everything was working fine with my swag setup, then i went to bed... when I awoke today my website (dlongo.net) is no longer accessible from inside my local network.(The site just times out ERR_CONNECTION_TIMED_OUT) But it seems to work fine if I turn on my VPN or access it from my mobile connection. Also if I ping dlongo.net it seems to resolve the correct IP. Anyone have any ideas on what I can check? Im just kinda lost at this point.
-
Not sure if others are geting the same thing, but mine is still showing Mono Version 6.4.0.
-
Looks like its been updated on arch! yay!
-
I know you were waiting for an upgrade but just wondering can the docker use the commands from the wiki? I see this in the wiki I get an TLS handshake (or similar certificate based) error Try mozroots --import --ask-remove which should update monos certificates. mozroots is part of the mono package.
-
Is there anyway to update Mono manually. Seems that the docker is running with v6.4.0. and the current stable is v6.8.0. i'm getting some web socket errors and have been told that i need to update the mono to current, but i'm not sure if I can do that if its in a docker. Not sure if this was right, but I did find that the Arch package page (https://www.archlinux.org/packages/?name=mono) is showing version 6.4.0.198-2 so I wrote a post on the forums requesting to update it, not sure if that is going to do any good or not. (https://bbs.archlinux.org/viewtopic.php?id=256541)
-
Ty for the info guys about the using old builds. I didn't know that was possible. Lear new stuff everyday.
-
Looking for some help to see if someone can help me pinpoint what is going on. Since updating to 6.6.7 I've noticed that my downloads from SABnzbd have been acting very strangely. Like It will download something, then Sonarr or Radarr will pause (they give you the gold/yellow option on the item) and say that the download is empty. But then when i manually check sometime there is files still in the download location, or they will be split up some in the incomplete and some in the complete. So i went to check the LOG for SAB, and i just get a bunch of weird symbols. Here is what my current log shows. Also Attached my Diagnostics log in case that can be of some help. ErrorWarningSystemArrayLogin ���,j�z 0��u�� �u��Lv" ���u��t �V�@�ɇ ��c����� �I�i0}q� �n�T�g� qoO2b5� ���v:�^3 ���/B�1� ��yr��� �{���/ ��yK�A� ��^��� ��6`@�� 1��p��]l ~�p���L �7*��� �~�vU�e �4�� O� cx,��j� ������G( i-e*� y����_ ����U.�� ��q?+s� w���C`� y�}���� �I�e�q� ���FZ� U���6 � ������ ҳ�Et3m ]W!n$�c% ��+c�X 4 8�J���� �<��!�6 ̺-̍�� �"z\�� � d���� �����P�� `�����^� y�)��\� ��;��6( dž�0H �$�: C�`�7&� ��*��\ aɻO�eٿ l��Z��h� zV���� 'm�ࢹ7 ��NuQk�] ��W@�b ��v�]} I_����# @w����e� @�э7�� "������� ��C.�hc �%�vG�� ��m���>i �#>��|? ;���%�| ��,n�}D� ��z�T�� C��fH� '!�墪�� ��;��* 2��᭡�$ ,̛S�� �/���;h� �\��#q ��V�2_D �p ���k* ���;��A nQ~�iZ,_ ���R�� H}��مI �J�(\y�E ?&錯B� �0M�5�� �x�H�� �_�R�= fdm&�X ���s�� �*9�IrW� � [wK� �h�;Y�s� b��q�ܡ �!L��)�� �s���(�� ���7}�� �+za�ε R���:m�8 �� ��W�7 X���i�WL ����d �:���Q�� wc*N�? �N�x� ��6A�i� ,�$]ؤ� M�`�H= ~ 3�/砵 ���Lk5$ }�u��.N Ӆ��[� ��s�Nx# �\u3��� ��<��#+ �X�d�q,� �W�9��# $����y�; LE��R� ��-�Y�( O1Ĵ��v ��^j�B +Q9�B��� w��31�p ���r !�vU�os� �p�6AeQ� ��7C��� s0��a,� v�]ة�"J bD�"�,�� ����} gW=��]H ��C1a��� ��>DP~ �����,� �T�CY�P� =�&�ch 1�u�aAJY �U�tc�� 6i'k!n� KEWt�{X ������| �X����� )�|f�Ua szw�(��� ��h���� Q�=�4�� s��!`��� t�e�!a� �&�#L�v� ��QI��8 �&����� Y1�����| s#S�A�0 r��y�Q�� M�l��â }-��_�m ��1��R ���X�#� ;F�G4e�� ��]_v::� t�J�]5+� ��C���� �f��{� ���3H�C ��ӯ� # ���moq�{ �W�j� �����?^^ ˝+Bcpי +R�e�cQ '?0�r� p_����l G�/B� �Y�`�� ����5��� ��L$7B|� ꠍ.� Hd�>@�C1 �$�pͻ� *�5~_�Y `{��C*�p ^�)A��d� ܄�� �n? ������q� d��Hq�4� �|%ȩ�N� /���� q����� 0p���9` �3��Yf �-��"�<l �F��H �#��x�N ��̢�� ֳy���7 �9������ rl)�/� �(ϓ��t� r:"�a#i� ���v�SR ����x�1 �����M 7���5X 5 ��4�|��� ��� �g祏��K 8��@s�q L� ���R �d�Y�o�� Xhp�˂ ��� 㛘tǸb3 YZ��\Z� GO��X��� �}�y$̓� Խ��cZ �k���z� km9Q�8c ����[|�_ e��\9� ��L�ML?k �ʿ����� ��`��d� 3�O�,��$ ������Tm X��ew�e ��[)H��) �_�j���{ F�|��� ���#cK Cȴg�� �Aơ�E�� �������4 �U�jj� E��!���� ��z�.!�� �]/]���� ��;?�� ��h� ��!}���� $5.�*נ� +oWY��� ݀�0 3 ��X��: ��ўl� oc���� �'���K�� B4+�pUb V<ݗ˼ xl�c� �h�l�� w�zl�d�- ����A� �z����w ��nǯj�� byG��'� e���Y��� �W���p k�Lt��� �f�w^��# W����K� �H!���J� u1��FEL n�3�w� .��\��� �uʶ4qO� g 賒t�E ���!߯� h������ =Paz�)�� ��M�(�V F�ʈ� ɦ���ZZ� D]�y��d� ��,�ʑ� �n�,���m �-�2��k� ]�� ) @�4`h^�� "�f.�d�H Y��D�� �Q4~�XP� ����aW9 �� �J7G܁ � �:vW��� ������ �!��j_�^ ��>��ޱ� =�*ep� �١�w%&� 5��س(�9 ������� ���{Y0J� N�,�pʿ� ]q!8հ �ޘVr��� 俻6�aT 31Q�:�5G �� �M=6 ; Bc��� 6���q��y c����� ���4��% %��<e:J� c���$/ 37'�MpD ����i� ����{Z� y��.4� $.�3,�F ��e٘�k ���"/ �XaY��0� j����j 8�L\� ,9�7=�r )*��TJ� \�����p ���¤� RӶ'� ��H���: w�2\(Ö �� �����$�� \W]� ��m|��� ix����� V"��� �J�KD� ;�-_�&e a�T/ 2019-03-01 13:04:27,871 DEBG 'sabnzbd' stderr output: 2019-03-01 13:04:27,786::WARNING::[assembler:123] Aborted job "NCIS.S13E17.1080p.HDTV.X264-DIMENSION-xpost" because of encrypted RAR file (if supplied, all passwords were tried) tower-diagnostics-20190301-1350.zip





