




Rex099
Members
-
Joined
-
Last visited
-
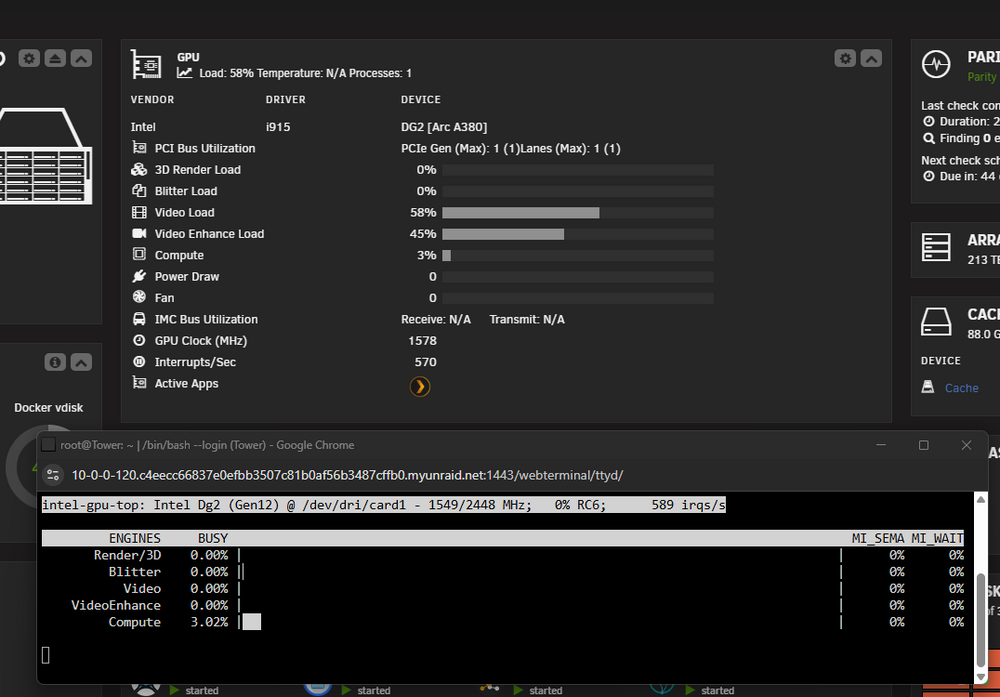
So after rebooting, and running a transcode again I guess it is "working" The fan, power draw, never move from zero. And the PCI BUS info seem incorrect.
-
I have the same issue with my A380 ELF root@Tower:~# ls /tmp/gpudata* /tmp/gpudata0000:84:00.0 root@Tower:~# ls /tmp/gpujson /tmp/gpujsongpujson gpudata00008400.0
-
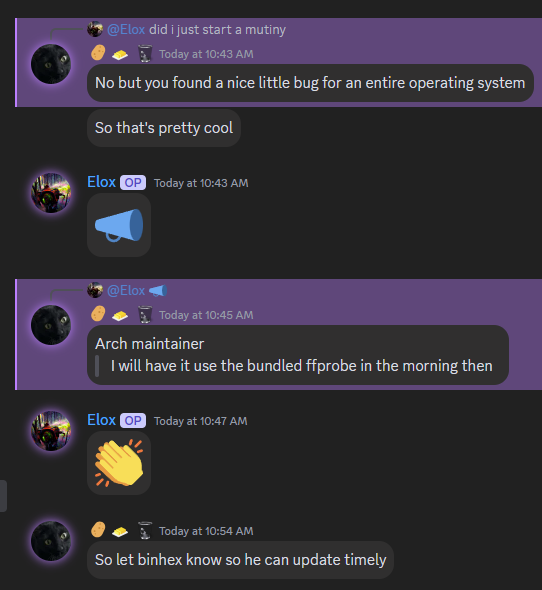
Appears there was an issue with the all the arch arr's not getting the custom ffprob. I reported an issue and was told there should be an update being pushed by the morning.
-
I had already attempted everything in that post, im actually the last comment on the thread Made a post on the plex fourms, it seems its actuallly a player problem not the server. https://forums.plex.tv/t/req-98a-transcode-denying-access-due-to-session-lacking-permission-to-transcode-key/882988/5
-
Still wondering if anyone has any ideas what might be going on here. Still having the same issue with HW Trancode Only.
-
Anyone recently had issue with HW transcoding? (Via GPU, Quadro P2000, also tried Quadro M2000 same result) Not sure what changed, but recently whenever I have HW transcoding enabled and the transcoing attempts My log gets flooded with [Req#115b/Transcode] Denying access due to session lacking permission to transcode key /library/metadata/192259 Then after a few seconds the client session dies with An unknown error occurred (4294967283) Error code: 4294967283 Software transcoding works fine with no issues. For info transcoding to RAM /tmp/plex I've tried changing it back to disk just to check but same results.
-
If i load binhex/arch-sabnzbd it shows "Par2cmdline-turbo:Not available" but if I load binhex/arch-sabnzbd:test it shows its working
-
Will this ever be rolled into the latest tag?
-
Wondering if you even found a fix for this? Whenever I used the action center to update anymore then one docker, I seem to have the same problem. If I update one at a time, it works fine but if I do multiple it says the updates happened but if i click the advanced toggle on the docker tab there will be orphaned images. Then I have to click force update on the individual dockers to get them to straighten out.
-
Posting how i fixed this just in case someone else runs into this. So I still never figured out what exactly the issue was but I ended up backing up binhex-plexpass using the old Backup/Restore Appdata plugin again. Then reformatted plex_appdata as xfs, then again back to zfs (I tried zfs first but it didnt fix the issue, so i had to do xfs first then zfs again). Once I did that I restored from the Backup/Restore Appdata plugin and the ran the spaceinvaderone script and it did a proper full snapshot... what a headache with no clear reason why.
-
Sanity check: In theory if I deleted all the snapshots from both datasets binhex-plexpass and plex_appdata_binhex-plexpass. Then took a snapshot, shouldn't it send a full backup from binhex-plexpass -> plex_appdata_binhex-plexpass when the Spaceinvadeone script runs?
-
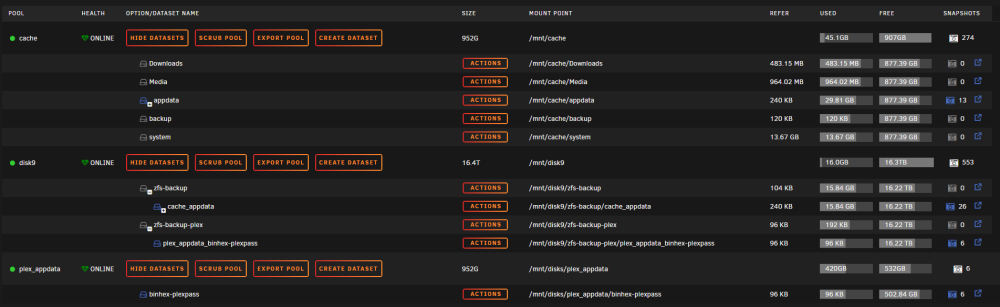
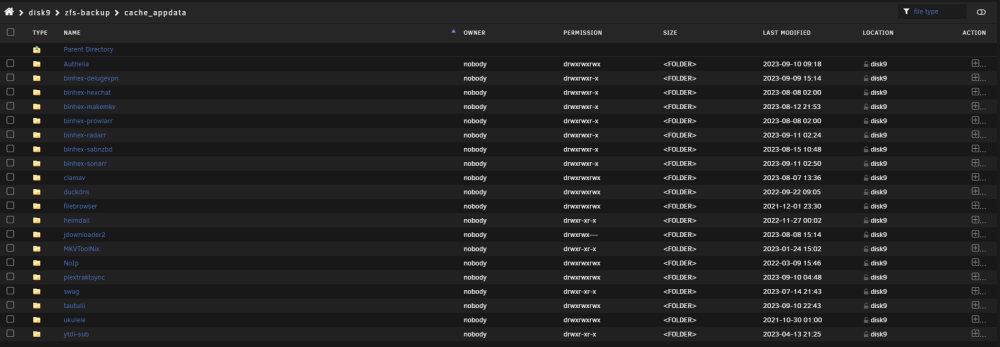
I'm wondering if there is someway to reset the zfs snapshots without deleting a dataset. I have 3 zfs drives, 1 cache and 1 unassigned devices and both of them are replicating to a ZFS drive in my array using 2 copies of spaceinvaderone's script. But i think my unassigned drive which is my plex appdata somehow didn't actually get a full snapshot, even though it says it did. really hard to explain what I mean but ill do my best. Here is my ZFS master My appdata folder from cache seems to be working fine and everything is backed up to the zfs-backup on disk9 with no issues But my binhex-plexpass does not seem to be actually backing up to the zfs-backup-plex, The snapshots say they are getting incrementally backed up but no data is being populated on plex_appdata_binhex-plexpass like it is on cache_appdata Example when i browse cache_appdata i see files But if i browse plex_appdata_binhex-plexpass its empty, like it never got the first full snapshot So im just not sure what I need to do to fix it or even if there is a way to without blowing away the plex_appdata drive and rebuilding again, which i really dont want to do. its something like 420GB of plex appdata which takes a long time to build.

-
Just just seemed to encounter this for the first time today. I installed the Dynamix Share Floor plugin which modifies the Minimum free space value. but just as noted in the other posts, if I modify any of the export settings(even if you just change it and change it back then save), the message goes away.
-
Not really sure what i'm looking for, or what this means but line 1343 of the syslog: Feb 22 02:46:36 Tower kernel: mce: [Hardware Error]: Machine check events logged Should i be looking elsewhere?
-
So I guess sometime over the past two days I got a MCE error from fix common problems. Attaching the diagnosis log as requested from the plugin. Any help or info would be appreciated. tower-diagnostics-20230227-1441.zip





