




madpuma13
Members
-
Joined
-
Last visited
Everything posted by madpuma13
-
At the risk of being too optimistic, I'm marking this as solved. I implemented both of the above suggestions, disabling global C-states and turning off a docker that was on custom:br0 network type to avoid the call trace issue. The server has been up and running for over 24 hours which is the longest in a long time. Marking this solved, ill update if the issue comes up again. Thanks again!!
-
Thank you soo much. This puts me down the path of figuring everything out. You are awesome!
-
I never came across this before. I'll give it a shot. Is this a common thing to start at random times? My server was up for about a year without any crashes until now.
-
So I've been dealing with this for about a month. Trying what I could research to fix the problem but I'm not left with many options. The issue: After a manual physical reset, the server boots as normal and everything comes online. Everything works, all UI's, all dockers, all shares. Then after a varied amount of time (sometimes 12 hours sometimes an hour) everything is unreachable. Even under Safe mode. The server itself shows something similar to this everytime and is unresponsive at the console itself.https://cdn.discordapp.com/attachments/585542638854471702/914953789029638194/PXL_20211127_022300451.jpg Diagnostics while the server is running if that helps. I kept the log open and was able to catch this before it cleared. Nov 29 15:42:42 Tower kernel: rcu: INFO: rcu_sched self-detected stall on CPU Nov 29 15:42:42 Tower kernel: rcu: 21-....: (240004 ticks this GP) idle=c46/1/0x4000000000000000 softirq=3856062/3856062 fqs=52036 Nov 29 15:42:42 Tower kernel: (t=240005 jiffies g=7800977 q=1908501) Nov 29 15:42:42 Tower kernel: NMI backtrace for cpu 21 Nov 29 15:42:42 Tower kernel: CPU: 21 PID: 29147 Comm: kworker/u256:17 Tainted: G W 5.10.28-Unraid #1 Nov 29 15:42:42 Tower kernel: Hardware name: ASUS System Product Name/ROG ZENITH II EXTREME ALPHA, BIOS 1502 07/13/2021 Nov 29 15:42:42 Tower kernel: Workqueue: events_power_efficient gc_worker [nf_conntrack] Nov 29 15:42:42 Tower kernel: Call Trace: Nov 29 15:42:42 Tower kernel: <IRQ> Nov 29 15:42:42 Tower kernel: dump_stack+0x6b/0x83 Nov 29 15:42:42 Tower kernel: ? lapic_can_unplug_cpu+0x8e/0x8e Nov 29 15:42:42 Tower kernel: nmi_cpu_backtrace+0x7d/0x8f Nov 29 15:42:42 Tower kernel: nmi_trigger_cpumask_backtrace+0x56/0xd3 Nov 29 15:42:42 Tower kernel: rcu_dump_cpu_stacks+0x9f/0xc6 Nov 29 15:42:42 Tower kernel: rcu_sched_clock_irq+0x1ec/0x543 Nov 29 15:42:42 Tower kernel: ? trigger_load_balance+0x5a/0x1ca Nov 29 15:42:42 Tower kernel: update_process_times+0x50/0x6e Nov 29 15:42:42 Tower kernel: tick_sched_timer+0x36/0x64 Nov 29 15:42:42 Tower kernel: __hrtimer_run_queues+0xb7/0x10b Nov 29 15:42:42 Tower kernel: ? tick_sched_do_timer+0x39/0x39 Nov 29 15:42:42 Tower kernel: hrtimer_interrupt+0x8d/0x15b Nov 29 15:42:42 Tower kernel: __sysvec_apic_timer_interrupt+0x5d/0x68 Nov 29 15:42:42 Tower kernel: asm_call_irq_on_stack+0x12/0x20 Nov 29 15:42:42 Tower kernel: </IRQ> Nov 29 15:42:42 Tower kernel: sysvec_apic_timer_interrupt+0x71/0x95 Nov 29 15:42:42 Tower kernel: asm_sysvec_apic_timer_interrupt+0x12/0x20 Nov 29 15:42:42 Tower kernel: RIP: 0010:gc_worker+0x9a/0x240 [nf_conntrack] Any assistance would be appreciated.
-
Just a quick update. Reinstalled from official, works now. I'm still getting stuttering! But thats not a problem for this thread. Not sure why the original container wouldnt allow me to transcode. Thanks for the assistance!!
-
Screenshot attached. Yes, I have enabled it by checking both Yes and Advanced (no options show under advanced though). Forcing transcode shows it working via cpu. Binhex Upgraded GPU's recently and this one wasnt doing anything. Absolutely overkill.
-
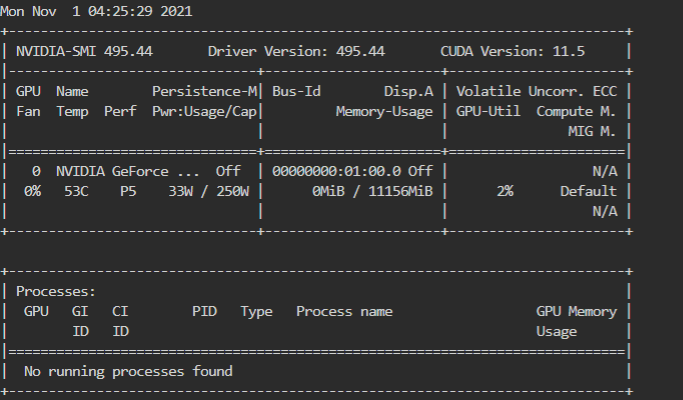
I've followed instructions found in the main couple of posts but I can not get my card (1080TI) to show in emby to use for encoding. I've added nvidia driver, runtime variable, device id variable, divice capablities variable. checked spelling/spaces of all values, nvidia driver is latest and showing no errors, disable/enabled docker, restarted server. As far as I can tell everything is correct. I do not have any errors in plugins or the emby docker. I have no VM's using the card (or even running to test). Attached is my diagnostics. Hoping you could point me in the right direction. Thanks tower-diagnostics-20211101-0558.zip
-
Sure thing
-
There anything I can do to help?
-
Hello, Trying to setup sabnzbdvpn on synology. I seem to be stuck and can not access the webui within local network if enabled. Works fine is disabled. Ive seen this brought up on the delugevpn thread a couple times and there was talk of fixing it but then the people reporting the issue seem to have dropped off. Any assistance would be appreciated! pertinent debug info: 2018-09-12 20:49:38.466033 [info] NAME_SERVERS defined as '209.222.18.222,209.222.18.218' 2018-09-12 20:49:39,795 DEBG 'start-script' stderr output: random.c:102: fatal error: RUNTIME_CHECK(ret >= 0) failed 2018-09-12 20:49:39,796 DEBG 'start-script' stdout output: [crit] ca-toronto.privateinternetaccess.com cannot be resolved, possible DNS issues


