

Niklas
-
Posts
323 -
Joined
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Niklas
-
-
12 hours ago, John Jensen said:
Hi binhex.. first, i am a happy user of your rutorrent-vpn.. i have used it very much - and very stable..
Buuut, the last few days, i am getting "Port status unknown" inside the GUI right down corner - i havent changed anything and using PIA swiss.. what could have happened ?
Thanks, JohnSame here. Using another server with port forwarding.
Running 6.7 RC2.
-
5 minutes ago, johnnie.black said:
Sorry, I though you were saying Unraid was detecting the cache as 352GB, fstrim is reporting the amount of free space trimmed, so free space that shows on the GUI x 2.
Oh, ok. Of course. Doh! So it is correct then. 🙂 GOOD. Thanks!
-
Hello,
With Unraid 6.7-rc2 ---allow-discards was added to enable TRIM on LUKS encrypted SSDs.
This is what I get:
root@Server:~# fstrim -a -v
/var/lib/docker: 23.8 GiB (25545605120 bytes) trimmed on /dev/loop2
/mnt/cache: 352 GiB (377950724096 bytes) trimmed on /dev/mapper/sdb1
Where does that size come from? 352GiB (378GB) looks strange when I have my two 250GB SSDs in RAID1 (btrfs).
I know too little about btrfs yet to understand if the reported size is correct or not.
Server specs in signature. -
12 minutes ago, Frank1940 said:
Is the share that you were saving the test file to being cached? The fact that the file is being encrypted (the read file being de-encrypted) may be a factor. What else was going (Docker wise) on at the time(s) when the stalling occurs? Have you checked to see what the CPU loads look like on the Dashboard?
No cache. The dockers did nothing special. Streaming from the Emby docker. I checked CPU load using the dashboard and htop in terminal. No excessive use. I don't think it is bandwidth problem with the hdds but maybe?
I have the array and parity connected to LSI controller and the cache and one spinner for temp data connected to the motherboard. I'm at 6.7 rc1 now and need to test it again. New samba version.
-
I had that plug in installed but not activated. Removed it now. Will check to see if it made any difference.
My server stops responding when transferring big files using samba. Made a test 10gb file and transferred it while streaming. The stream stops until the transfer is done. The stream was 720p so not much data. Strange..
-
Yes. I added my domain to config.php under trusted_domains. Forgot about that but you would see that as you do now.
")
I also run Nextcloud (and Traefik) on br0 with static internal ip.
'trusted_domains' =>
array (
0 => '192.168.1.30',
1 => 'nextcloud.domain.tld',
), -
No changes to Nextcloud config. I use subdomains for my dockers so I use frontend rule as "Host:subdomain.domain.tld"
How about adding insecureSkipVerify = true to the toml instead of a label?
Log to file and check what traefik is doing?
debug = truelogLevel = "DEBUG"
[traefikLog]
filePath = "/etc/traefik/log/traefik.log" -
I tried today. This works fine for the nextcloud docker from linuxserver:
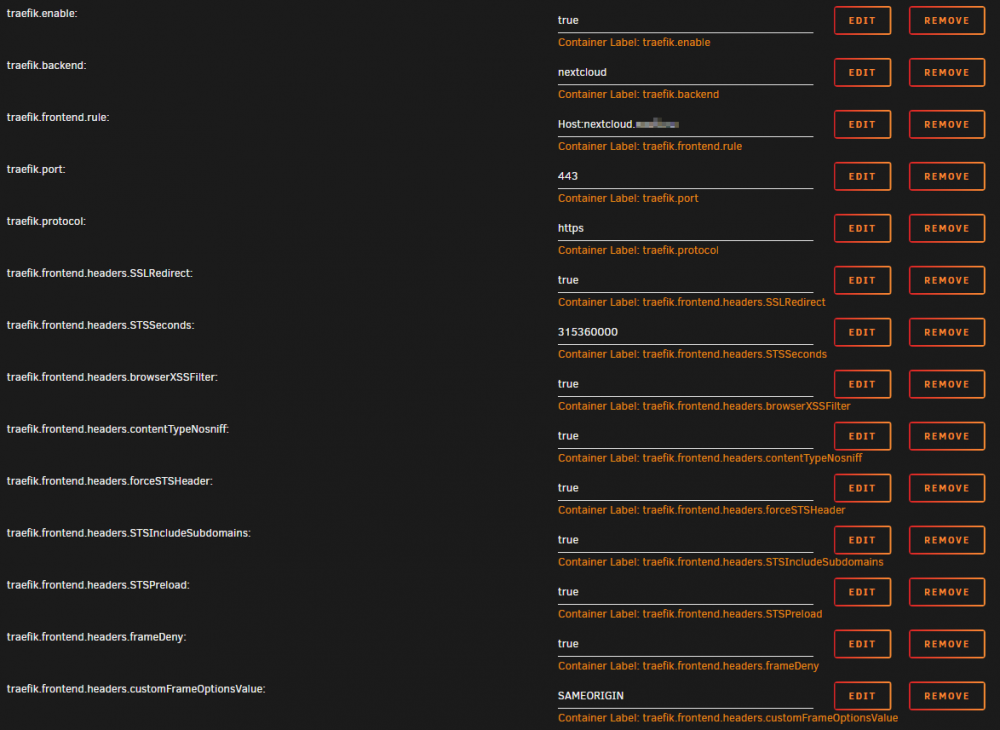
The last label (customFrameOptionsValue) is needed, without it, Nextcloud will tell you to set it.")
This is my traefik.toml:
#debug = true logLevel = "INFO" #DEBUG, INFO, WARN, ERROR, FATAL, PANIC defaultEntryPoints = ["https", "http"] InsecureSkipVerify = true sendAnonymousUsage = false checkNewVersion = false [api] # Enable more detailed statistics. [api.statistics] # Number of recent errors logged. # # Default: 10 # recentErrors = 100 [traefikLog] filePath = "/etc/traefik/log/traefik.log" [accessLog] filePath = "/etc/traefik/log/access.log" [entryPoints] [entryPoints.http] address = ":80" [entryPoints.http.redirect] entryPoint = "https" [entryPoints.https] address = ":443" [entryPoints.https.tls] sniStrict = true [retry] [file] directory = "/etc/traefik/rules" watch = true [docker] endpoint = "unix:///var/run/docker.sock" domain = "removed" watch = true exposedByDefault = false network = "br0" [acme] email = "removed" storage = "/etc/traefik/acme.json" entryPoint = "https" OnHostRule = true acmeLogging = true [acme.dnsChallenge] provider = "my_provider" -
Do you have any traefik.toml?
-
Fix Common Problems sends out notification about plugin update available. Every day.
") Just ignore that warning in the settings for now.
Just ignore that warning in the settings for now.
-
I only have two disks with data. The third disk is sleeping all the time because not needed. Spin up takes like 1-2s. The tasks freezes for at least 1 minute or more. Even when the disks are spinning.
-
I see no answers to this but I experience the same problem. If copying files from my windows desktop to the array and I simultaneous want to open a text file or something, samba becomes unresponsive. The copy task just grinds to a halt and the network share freezes with "not responding". After a while, the file opens and the copy task starts doing its thing again. This has happened to me several times. The web gui also responds very slowly when this happens. Like it can't cope with two requests at the same time. CPU usage is OK when it happens.
-
No problem. Unraid identifies drives using the serial number of the drives.
-
I see your signature 😉 make sure that you have it enabled in the settings for your signature. You can turn them off and on there.
Unraid OS Plus 6.6.6 MB: Asus P8Z77-V LX (microcode updated). CPU: Intel i5 3570k 3.4 Ghz (Ivy Bridge, 4 cores, no Hyper-Threading). RAM: Corsair Vengeance DDR3 1600MHz LP 4x4GB (CML16GX3M4A1600C9) = 16GB. PSU: Corsair TX650W. DRIVES: Parity: 1 x Seagate IronWolf ST4000VN008, 4TB. Data: 3 x Seagate Barracuda ST4000DM004, 4TB 1 x Seagate ST1000DM010, 1TB (unassigned, used as temporary storage). Cache: 2 x Samsung SSD 860 EVO 250GB (RAID1). FS: Cache: Encrypted btrfs. Array: Encrypted xfs. TOTAL STORAGE: 12 TB data, 250GB cache. NETWORK: LAN: 1 Gbps, WAN: 500/100 Mbps (fiber). Router: ASUS RT-AC68U (Asuswrt-Merlin). USED FOR: Dockers and storage. No VMs. POWER CONSUMPTION: 45 - 55w normal use, 98w max during parity check, 1.1 - 1.5 kWh daily.
tl;dr
-
4 minutes ago, bally12345 said:
Not seeing signatures for some reason, what are you using to log?
You don't see them in the mobile version.
Using Domoticz and z-wave power plug. Nice graphs and stuff.
-
Specs in signature. Spinning down hdds after 45 min inactivity. About 1.5 kWh the day of parity check. -
Yes, I understand that. It just catches my eyes every time I scroll the smart info. Like something is wrong when the problem is solved.
-
6 minutes ago, Squid said:
Yes. Basically Means that its a monitored attribute with a non-zero value
And it should be like that? It catches my eyes every time.
Now I will see it forever, until I change my drives?
Edit: I would be happy if the highlight disappears when I ack the error.
Edit 2: Could deselect UDMA error count in the settings but I want it to tell me if the value changes... so.. hm -
Hello!
I had some UDMA CRC errors, stopped increasing when I changed all SATA-cables.
After acknowledged the error, status is green again but the value is still highlighted when looking at the smart info for the drives affected.
Getting very apparent when using the dark theme.
Is this by design?

-
Following this thread with interest.
I just moved all my drives over to encrypted fs, mostly to protect the data if hw stolen.
I have 2 SSDs as cache and fs is encrypted btrfs in raid 1. Trim "should" work even on encrypted drives, right? I understand it won't on unraid (yet?) but what problems can this cause me? Over provisioning is an acceptable workaround if it helps with anything. But how do we do that?
Would be nice to be able to set size when formatting the drives in the gui. Just leave some unformatted is what over provisioning does?
-
When you say "Dashboard", what do you mean exactly?
On the right side, on the "Dashboard" you can toggle a switch to "All Apps" or "Started Only".Maybe something like that?
-
Well. The strange available updates with 0 B pulled has suddenly stopped happening. From one day to another. 🤔
-
Is the "pulling from" correct? Showing plex when working with traefik?
At first, I thought it was only the linuxserver containers. It's not. I just see them more often because I mostly use containers from them.It happens to the others too. Pressing check for updates could show no updates, pressing again directly after could show there is updates but 0 B pulled data. Looking at docker hub the last push can be like a week ago but it still shows as update available, updating fetch 0 B and the status goes from update available to up to date. One example is uberchuckie/observium. Has shown updates several different times since 2 days. Always 0 B pulled.
linuxserver builds once a week? I have seen different updates from them over the weekend.
I have seen 0 B pulled before but now it happens daily. Some dockers updates without problems, like Emby server beta that got "real" updates yesterday.
It's like Unraid is showing updates for containers that don't have any updates? -
Hello,
Getting updates for my Docker containers and it's pulling data for some but for most I get "TOTAL DATA PULLED: 0 B"
I also noticed this (it is standard with 1+ update?):
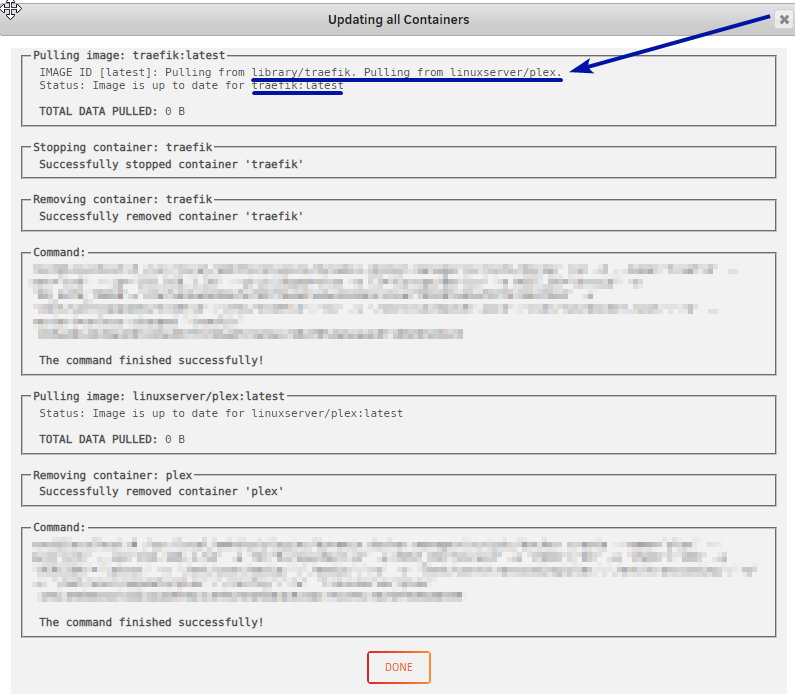
What could be up with this? Most of the updates are pulling 0 B. Not seen that before. Can't find any errors in logs.
Unraid 6.6.5. Looked at other threads with "TOTAL DATA PULLED: 0 B" but not same error or solutions.
Recently changes are all sata-cables (got some UDMA CRC error count on one drive (6), changed sata cable, put server back in place hard to get, ran parity check, UDMA CRC error on one of the other drives (got up to 6 here too), decided to get brand new sata cables and replace ALL. New parity check, no new UDMA CRC error's), added parity drive (had 0 parity drives before) and added "--restart=unless-stopped" to some containers. Then, this started to happen.
appdata and system (docker.img) on samsung ssd (cache).




[Support] binhex - rTorrentVPN
in Docker Containers
Posted
Ah, yeah. Sounds about right.") Thanks.
Thanks.