

Cull2ArcaHeresy
-
Posts
98 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Everything posted by Cull2ArcaHeresy
-
To allow grouping of VMs and thus better organization. Say school, networking, current projects, and backburner projects as categorizations that someone might have. Go to VM tab and can expand only the folder you need like networking to troubleshoot a problem instead of scrolling up and down all your VMs to go to the different networking related ones. For simplicity I would assume a VM would default to uncategorized (or unlabeled or whatever). Ideally this property of the VM could be changed with it running, like maybe one goes from projects to processing data to signify the functional state of the VM (big data application so runs for long time). Farther down the road it would be nice to apply actions to the whole group. Start/stop/pause, and vnc to open a vnc window for each VM so you can quickly look at the whole group (tiling the windows would be cool but probably be too far). Apply settings to the group like autostart toggle. Can think of other actions, but not ones that make sense for unRAID VMs.
-
I have a r720XD running unRAID (2x12tb parity, 5x12tb + 3x6tb array, 3 cache, 1 unassigned). A chunk of the storage is "vault/archive" type files/folders/projects, but also the stacks of external harddrives. I bought a 4246 with 24 x 4tb drives (and the cable and a 9202-16e) which should be delivered friday. When including everything shipping/tax/warranties/cable/lsi/das/drives, total was ~$2k but will make future upgrades easier (and still cheaper $/tb than 12tb exos). After preclearing the drives, I could add most of them to my array, but hoping to do better. You know how you have cache-->array, I'm trying to concoct some way to do (cache-->array)-->vault/archive. So when I search for a file or [plenty of other examples] I just go into the share it would be in and it will show up functionally speaking. I get that unRAID does not have 3 layers. Thinking give the 24 x 4tb drives to a VM running an actual RAID config (figure out number later) and have it mounted on the unRAID side. This would require some custom "mover" script to create the links for files to show up on the share when they are in the VM array (and move them to the VM array). The more I think about this method the more it seems like it will crash and burn hard. Maybe the solution is to run a basic unRAID server using the max number of drives and just have the other 4 (or 2?) drives ready to hot swap in (they are used sas drives). I am open to other ideas too, worst case I have main storage and vault/archive storage (still run from the VM), and they are separate network entities.
-

slow write speeds for linux, windows still fast
Cull2ArcaHeresy replied to Cull2ArcaHeresy's topic in General Support
CrystalDiskMark (w10 with direct 10gig line) on M is a cache enabled array share, S is no cache share. Not sure how RAM would have any impact here as under normal use or high disk IO use have never seen it above 50% (128g installed). But tested with 256g and 64 (max of CDM). So my testing method was problematic, but there still is an issue. Remote things speed problems seem to be VM based. I know it could be headless but installed desktop version because this is still a relatively new addition and it made testing easier (few months old). I have an ubuntu vm that I manually run autossh -M port1 -R port2:localhost:22 user@seedbox (again place that needs to be automated eventually, but unraid server is not rebooted often). The VM has movie and tv shares mounted from the vm options in unraid. The vm can still access all server shares, so the whole point of doing it this way for security is not good but better than the unraid server itself making the connection (and the hassle of getting autossh running on unraid again). On seedbox side I have sshfs -o reconnect,ServerAliveInterval=15,ServerAliveCountMax=3,cache_timeout=3600 [email protected]:/mnt/TV/ /home/user/RazaTVdir/ -p port2 and a movie share command. Internet is 200/20, and sonarr would import via this tunnel at ~80mbits previously, which I'm now thinking might have been the VM limiting it not a sonarr limitation (base on the ~10mbs speeds below). Older method (before vm) was to manually download files with desktop with ftp/filezilla which would get ~170-220mbits with 220 pegged if using segmented and parallel downloads. [I know 10g is small here, but this vm is on a vm ssd which only has like 30g free.] Seeing other posts about br0 being an issue with some VMs speed, but there was not a network spike during test (why monitor is behind terminal). Rebooted the vm and tested again with a speed of 6.80 so about the same. Not sure that this would be a br0 issue tho as I used to get 80mbits/10mbs, and now i get 20mbits when lucky, most the time 5 to 10. Using desktop/ftp I get the same speeds from seedbox, but ssh tunnel thru vm is slow. The issue(s) fall into 3 categories VM speeds unraid or seedbox side problem im way off and have a different problem

-
slow write speeds for linux, windows still fast
Cull2ArcaHeresy replied to Cull2ArcaHeresy's topic in General Support
Server has been updated to 6.8.3 and rebooted. After reboot speeds were full and a bit later they weren't so tested and same results as before. Unassigned ssd great, cache pool <1m, and drive array ~3m. Issue is not disks being used by other things as there is little to no io shown on main when running the tests. cd /mnt/disks/Samsung_SSD_860_EVO_500GB_S3YANB0K808920W/ && dd if=/dev/zero of=test.img bs=100M count=1 oflag=dsync && rm test.img && cd /mnt/user/cache-only/ && dd if=/dev/zero of=test.img bs=100M count=1 oflag=dsync && rm test.img && cd /mnt/user/experiments-no-cache/ && dd if=/dev/zero of=test.img bs=100M count=1 oflag=dsync && rm test.img 1+0 records in 1+0 records out 104857600 bytes (105 MB, 100 MiB) copied, 0.36781 s, 285 MB/s 1+0 records in 1+0 records out 104857600 bytes (105 MB, 100 MiB) copied, 204.271 s, 513 kB/s 1+0 records in 1+0 records out 104857600 bytes (105 MB, 100 MiB) copied, 36.9284 s, 2.8 MB/s raza-diagnostics-20200425-0351.zip -
slow write speeds for linux, windows still fast
Cull2ArcaHeresy replied to Cull2ArcaHeresy's topic in General Support
Has been installed since idk, just never scheduled it (except for a bit when testing this issue). Just set it to run daily. -
My array is getting write speeds of ~3MB/s, cache getting ~0.5MB/s, and unassigned devices ssd getting full 333MB/s. Speeds got from runs of "dd if=/dev/zero of=test.img bs=1G count=1 oflag=dsync && rm test.img " with same results with bs of 1M/10M/100M/1G. Windows gets full speeds tho. For a bit I enabled scheduling of ssd trim, but results didn't change and then realized that speeds were bad for hdds as well, and then that windows was unaffected. Speaking of ssd trim, should that be running? It has never been enabled and when looking for info on unraid/trim, it is not current posts. raza-diagnostics-20200416-0126.zip
-
Unraid Forum 100K Giveaway
Cull2ArcaHeresy replied to SpencerJ's topic in Unraid Blog and Uncast Show Discussion
Best thing is how easy it makes everything for a "power user". Storage, VMs, and so many other tools all in the same place. Yes you could create a VM farm and have a nas vm, but with storage as the bottom layer it is faster and easier to work on. And to add a drive to the array is not this whole rebuilding multi layered RAID systems, but some of that was bad planning on my part (my setup was worse than hers on the iJustine/LTT video where she got her server). An interesting add would be "multilayered cache", for lack of a better term. A few forms of use that I can think of are more of a cache level system. you have ssd cache pool and nvme cache pool and either diff shares have diff pools or some sort of ML/AI predicts what files you'll want soon so it moves them to the ssd cache and then to the nvme when you are using them (making assumptions about how the mover actually moves files as i have not really researched it) archive/backup/hdd based. For a large storage volume this would almost be more of a multi server setup, so imagine a small to medium sized setup for this. You have your ssd/cache pool acting as it normally does, your main drive array (fast HDDs, say 10tb size or smaller), and then slower drives or larger ones (like the upcoming 20+tb drives). Files that have not been touched in a long time get moved to the slow/archive section to free up faster disk space for the current files. That idea is bordering on an uncomplicated optimization system...but maybe not. -
repair libvirt.img to restore VMs?
Cull2ArcaHeresy replied to Cull2ArcaHeresy's topic in General Support
Had to force shutdown a few weeks ago as it got stuck stopping the array, which had to do to add a new drive to it. When it booted back up everything was back to normal afaict. I just got a little paranoid ass all the custom configs are not exactly documented... But have the zipped copies of those images which at some point I plan on investigating them. Also I will have to update past 6.6.6 (come on, how can you not love it) as some plugins and apps cannot be updated anymore. -
My cache drive filled up and mover was not able to move anything (had too many winrar compressions running at once). Now all my VMs do not show up. I've seen posts about cache drive being full causing problems. I have 2 VMs that are still running but not visible. The solutions I've seen are to remake all the VMs pointing at the vdisks and having similar configs. Really dont want to have to do that as I have no idea what many of the configs are and some even had custom bios settings. There are 2 different libvirt.img files, neither mounted. Is there any way to repair the img? I assume the process will be to mount it somewhere else, go into it and edit files then tell the system to use that new img. At one point I turned cache off on all shares trying to get mover to move files that were not being moved, didn't help so turned it back on for the shares that use it. Idk if that contributed to this problem. I have not rebooted as didn't know if in starting it would run a cleanup of some kind and remove 1 of the imgs (both have been backed up into zips). root@Raza:~# find /mnt/ -name libvirt.img -exec md5sum {} \; 957e09e5cd152d2f5cd47d1f1be87554 /mnt/user/system/libvirt/libvirt.img 441704ee246fadb14a534508d17c4165 /mnt/user0/system/libvirt/libvirt.img 441704ee246fadb14a534508d17c4165 /mnt/disk1/system/libvirt/libvirt.img 957e09e5cd152d2f5cd47d1f1be87554 /mnt/cache/system/libvirt/libvirt.img root@Raza:~# find /mnt/ -name libvirt.img -exec ls -lah {} \; -rw-rw-rw- 1 nobody users 1.0G Nov 25 00:50 /mnt/user/system/libvirt/libvirt.img -rw-rw-rw- 1 nobody users 1.0G Jan 7 2019 /mnt/user0/system/libvirt/libvirt.img -rw-rw-rw- 1 nobody users 1.0G Jan 7 2019 /mnt/disk1/system/libvirt/libvirt.img -rw-rw-rw- 1 nobody users 1.0G Nov 25 00:50 /mnt/cache/system/libvirt/libvirt.img root@Raza:~# ls /mnt/ cache/ disk1/ disk2/ disk3/ disk4/ disk5/ disk6/ disk7/ disks/ user/ user0/ root@Raza:~# ls /mnt/user Downloads/ MOVIES/ TV/ TheMarauder/ VM/ appdata/ domains/ experiments-no-cache/ isos/ streamlabs/ system/ youtube/ root@Raza:~# ls /mnt/user0 Downloads/ MOVIES/ TV/ TheMarauder/ VM/ experiments-no-cache/ isos/ streamlabs/ system/ youtube/
-
Today the "Preclear Disk Send Anonymous Statistics" never finishes. Open a new window/tab/refresh and it pops up again. Dismiss does make it go away tho. sending reports again
-
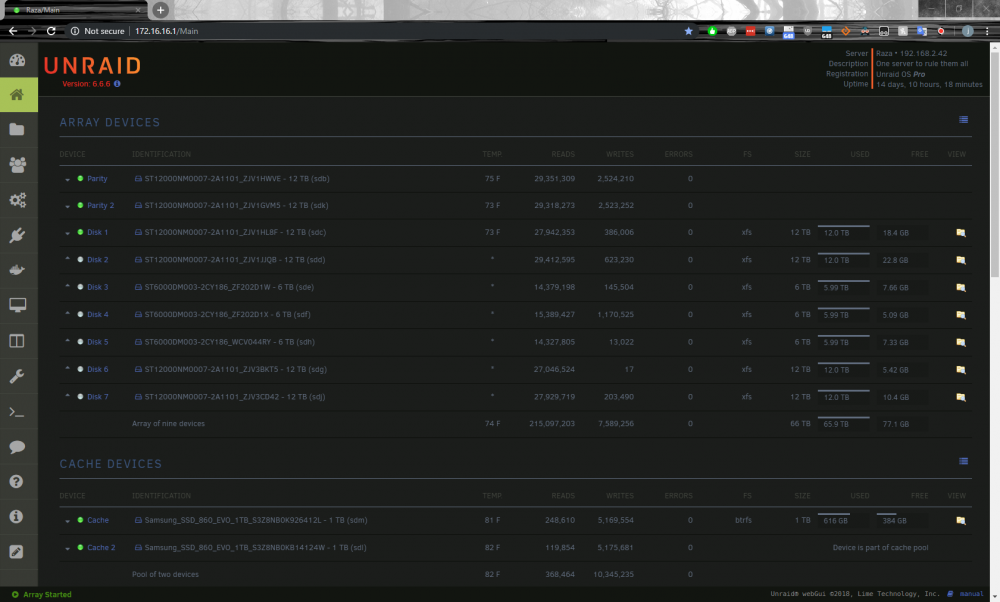
My server is a dell r720xd, so 14 drive bays (has 2 2.5in bays on back). 2 are for ssd cache and 1 is an ssd for VMs, which leaves 11 3.5in bays for drives. As you can see in the picture, really out of space. With 16tb exos drives still being new enough that they are ~25% more expensive per tb and haven't really seen trends yet on the off chance that there was a defect with drives, was going to go with 14tb exos. To use larger drives, I need to have bigger parity. Below is the proposed plan as for best steps to take based on what I've seen around, but guessing it has some steps that are not needed or other streamlining methods...and also last step is where not sure best method that is also safest. Maybe I'm just being paranoid about the 16tb exos. If so, let me know to buy them for parity for an extra ~$150 each. As using the larger parity now will allow me to add 16s when they come down in price soonish (hopefully). In the long run, this seems like a better idea, just don't know if can really trust them yet. With 16s, step 3.2.3 would bee getting 2 16s now for parity, then somehow recombining the 3x6tb and 2x12tb exP into data section adding 16s as needed with whatever the proper swap methods are. Am I being paranoid? And now that this paragraph has been added it is clear that I have an idea of what end result needs to happen but no idea how to really get there easily. If am being paranoid let me know and will adjust below to be about 16 not 14. current array: 2 x 12tb P 3 x 6tb 4 x 12tb 2 x OPEN 2 x 1tb cache 1 x unassigned ssd for VMs { *** looking at currently is use ones, only 1 is on the ssd and the rest are on one of the shares. if need be, i can move that vm to the share to remove the ssd to open up another slot during this procedure and then move it back later *** } prepare new drives {0 open bays} use 2 open bays for new 14tb run preclear 3 times (iirc 12tb took about 2 days for each clear so looking at a week of testing, but being the new parity drives I want to make sure they are good, unless 3 times is now overkill) "fix" parity {2 open bays} take 2 12tb parity drives out and set aside assign 2 14tb as parity and start parity check (unless doing a bit copy from the 12tb P would be better) add exP storage {0ish open bays depending on step 2} put thee 1 12tb exP drives back in ???????? this is where it seems to have more variance depending on where I look between data moving and parity rebuilding (and some unraid tools). I want to add the 12tb exP to the array for data, add 14tb drives and remove 6tb ones. it seems like there are 3 main methods people are taking here move data off 6 and onto 12, remove 6, add new add 12 to array, build parity, swap 6 with 14, build parity, repeat swap build as needed swap 6 with 12, build parity, add new have not ordered the drives from amazon yet, but if preclear is going to take a week, will probably order 2 and then when they are almost done order the data drives (probably go ahead and order 2) new array: 2 x 14tb P ?? x 6tb ---> eventually 0 4 x 12tb 2 x 12tb - exP ?? x 14tb ---> eventually 2 1 OPEN (not required, but makes it easy to preclear a new drive before adding or slot in some unassigned drive for whatever reason-probably need to add an expansion bay-or whenever i add a 3rd ssd to cache) 2 x 1tb cache 1 x unassigned ssd for VMs Feel like im making this more complicated than it needs to be, or all those rebuilds are just a part of the unraid experience that hadn't really had to deal with yet (only had the server for about a year). Thanks for the help.
-
Power outage parity check errors
Cull2ArcaHeresy replied to Cull2ArcaHeresy's topic in General Support
Ran check got 309 errors again and then ran and got 0. For future reference that second manual run was not needed, right?
-
Power outage parity check errors
Cull2ArcaHeresy replied to Cull2ArcaHeresy's topic in General Support
So I'm good then? I think I was downloading off my seedbox when it happened, or mover running since that share has use cache turned on (or plex causing it cause was watching a tv show). And I don't need to run more parity checks or disk checks (altho in just over a week the monthly one will run). -
We had a momentary loss of power yesterday. I know the server should have a ups, but have not been able to buy a large one yet, but looking at the parity check history it seems we've had more power issues than I realized. Upon rebooting the parity check started as normal. This time it found 309 errors. But looking up at the drives there are 0 errors listed. Between this forum and reddit there are many different posts with what to do about parity errors from nothing to running it 3 times and reseating all the hardware. Do I need to do anything? raza-diagnostics-20190523-2113.zip


-
We did not have power loss, and everything seemed to be working as normal still...but the vm that was running is now off. Had given it 40 cores out of 48 and 118 gigs of ram out of 128. Was being used for password cracking at a ctf. It was not 100% resource pegged non stop anymore (generate wordlists with specific rules, test wordlists). Day or 2 before it ran with those 40 cores at 100% for almost 24 hours with no issues, which is where I could see a crash being caused. Can you tell what caused the crash (vm or hardware or other) from those logs?
-
I know there was a bug with 6.6.5 that had to do with cron jobs on sunday, but the first of next month is a monday. If I have a hardware problem I want to take care of it asap. Check 2.1% in and all drives are showing green on dashboard and temps are currently all in 80s (except main cache drive is at 100F). I know there is an update to 6.6.7, but have not had a chance to take everything offline yet (and sad that it will not longer show "Version 6.6.6" at the top of the page always). There is a chance I'll be able to get it down this week, and if this is related to a bug that is fixed with the new version I'll work harder on getting it ready to update. raza-diagnostics-20190311-1804.zip raza-syslog-20190311-1806.zip
-
Under system devices "IOMMU group 41:[168c:002e] 41:00.0 Network controller: Qualcomm Atheros AR9287 Wireless Network Adapter (PCI-Express) (rev 01)" shows up, but never under Other PCI Devices when editing or creating a VM. I am seeing different XML edits that need to made that sometimes work sometimes not. USB devices show up and are connected to the VM. How do I get my PCIe card to show up too? Or is this one of those "every hardware behaved differently" things?
-
For me the latest update will have preclear saying it is done, but unraid never sees it being done (didn't try a restart). Going back and telling it to preclear the drive again, but with skip post read checked, unraid would be ok with it. Been meaning to come post about it here assuming there might be a bug.
-
I would love to run 3+ cycles, but I kinda need the space sooner than in 2 weeks. It looks like preread and zero are going at the same speed, and thus are each going to take ~16 hours. If I am reading it correctly, it does preread, zero, preread, zero, postread, zero, postread-so 7 steps that all take about the same amount of time, so like 4.7 days per cycle. Definitely going to run multiple cycles on older questionable drives, but they are also 250/500 gigs. Would there be any harm in me stopping the preclears running and starting them again with just 1 cycle? Assuming that math is right, my drives will then be free almost 4 days sooner. I ended up canceling it and it restarting it and it took about 51 hours per drive, so not linear however it works. Thanks for all the help @gfjardim
-
That explains the speed of their runs. I do not see the testing option anymore, but the first time I left it on because it was enabled by default. Since those 2 need to be redone and were part of an array, I assume "erase and clear" is better than just "clear" for operation? And is there any reason for more than 1 cycle (these are new drives, like arrived from amazon and stuck into server)?
-
12tb x 2 and 250gb x 1 claimed they finished. The 12tb x 2 still running taking so much longer are concerning me that there might be a problem. I am getting close to being 24 hours in with the first preclear not yet done, so also trying to figure out how I can start using my storage sooner. RAZA-preclear.disk-20181009-1941.zip
-
My first 2 12tb drives precleared in less than 6 hours last week. I added 2 more yesterday (so I have a full 2 parity drives) and started preclear. Just the pre-read took over 12 hours. The cleared drives currently in there are sitting idle with the array stopped (had started to move files but then decided to finish redundancy first). Now 8 hours in with 54%/56% done at 233/236 MB/s of zeroing (1 of 2) step. Since the first 2 drives are on the left backpane I put these 2 on the right one so both SAS cables are used figuring it would be better distribution. Between the first set of drives and the new 2, there was an update to the preclear app/plugin and the preclear code (system side), if that is the problem. Do I need to be concerned about my first preclear drives because that was too fast? Are these slower than they should be so I should investigate if the backpane has a problem? And I had told it to do 2 rounds of preclear...so am I just SOL for the next few days?







