




sminker
Members
-
Joined
-
Last visited
-
Another one over here. New CX500 500GB drive. About three weeks old. Getting the error since installing. I use it for my plex appdata (got tired of the mover taking forever when upgrading cache drives). This is going to make me avoid Cruicial SSDs for a while. Never had an error with any of my samsungs, SPs, or Sandisks. Some are 3-4 years old.
-
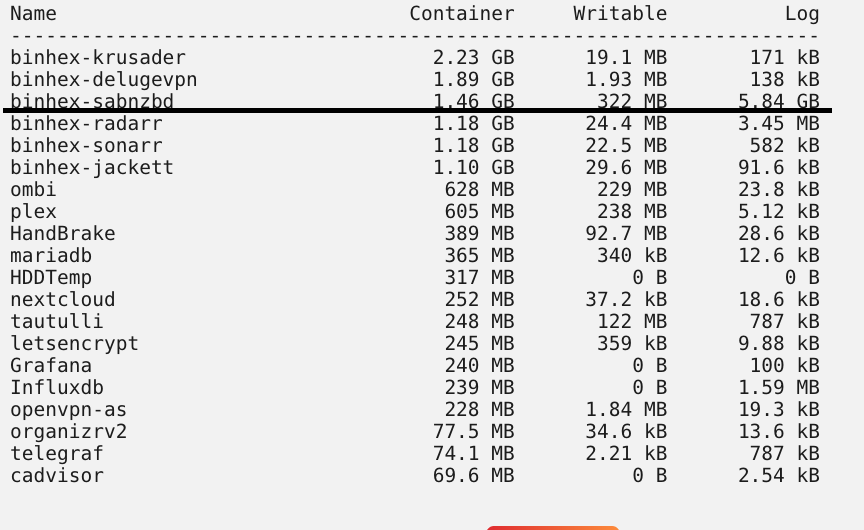
Log issues with SABnzbd? Ive looked everywhere and cant find the spot to change logging size and google hasnt been very helpful. Im sure its staring me right in the face. Edit: I did the extra parameter for setting the maximum logging. It fixed the size. But for just more knowledge, what setting could I of changed in the actual docker gui or command prompt to setup the app properly.
-
Thanks for that. Still not giving readings for the nvme drive. Ive tried /nvme*, /nvme0*, and its direct location in the dev folder /nvme0n1. Anyone have anyother options I can try.
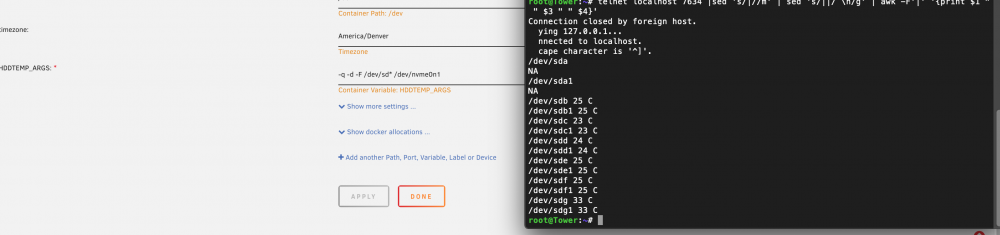
-
HHDTemp docker question. I need to get the temps from nvme0 (m.2 cache). I get all the sd** just fine in grafana. Assuming i need to add another parameter to the docker. Can I just put a comma? EX: -q -d -F /dev/sd*, -q -d -F /dev/nvme* Or should I make another HDDTEMP_ARGS variable and duplicate the command with the /nvme* at the end instead of the /sd*?



