




rorton
Members
-
Joined
-
Last visited
-
sorry only just got around to hooking the machine up to a monitor to test this. Ive looked through the BIOS and can only see something about above 4G which seems to be related to graphics. Ive set this to enabled anyway, but no difference. If I go into the memory section of the BIOS, it shows 2 4Gb sticks, but the main bios summary screen just shows the 4GB, most strange
-
Just tried upgrading to 7.1.0 and when rebooted, my parity and one array disk is missing. Diags attached - im just regressing back to 7.0.1 as I need the box running as there is a DNS docker on there I need for the house internet to work. unraid-diagnostics-20250506-2113.zip
-
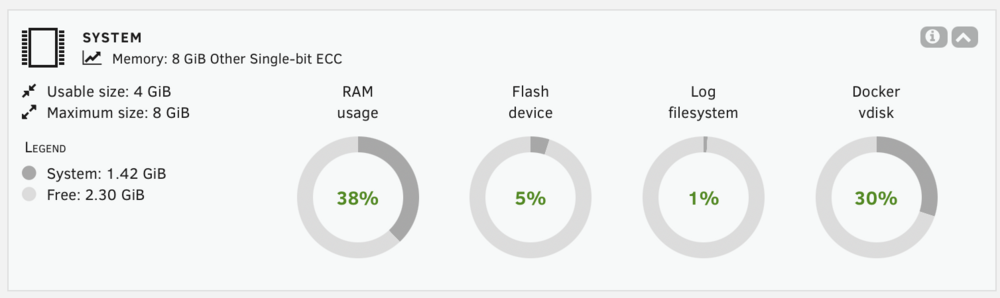
I have a second backup server setup, its an HP N40L microserver and installed are 2 x 4gb ECC sticks System profiler sees the 2 sticks ok, but htop, and the dashboard only seem to be addressing 4gb. Have attached diags. Any reason this is happening? Anything I have forgotten to do? backup-diagnostics-20250405-2258.zip
-
Not sure if it’s always been like this for me, but I can’t seem to view the running log of a script set to run in background. if I click the icon to view the log, a page opens up with an address of unraid.home/logging.htm and all that’s in that page is a button with the text UNDEFINED if I run a script in the foreground I can see it’s log running. Any ideas why this is happening?
-
hmm, looks like write cache isn't staying when rebooted. I tested last night, and was good, powered back up today, and not enabled, have enabled it again and transfer is now at around 600 - 650Mbps I just need to fix write cache so its on all the time, strange as my primary server doesn't have this problem
-
ah, spoke too soon once the disk cache (I assume) is full, speed drops back down again
-
think I have the solution! The backup server is an old chassis but a brand new install of Unraid with new disks. I was still getting it configured so hadn't installed plugins like fix common problems. Installed that, ran it, and it mentioned write cache not enabled on the hard disks! Switched it on, and boom, 650Mbps. nearly 3 x faster.
-
Just looking at smb copy. My concern is that I need to mount the shares for the destination host. my backup server is switched off most of the time, just switched on to run backups. how will the unassigned devices cope with the share disappearing and then reappearing? The beauty of doing this via ssh is it makes the connection as it needs it?
-
just installed GTPWOL and works great, I can use the gui to manually wake a machine on the lan. Im creating some scripts to do backups, and wondered if I could call the WOL tool from a script rather then having to use the cron scheduler in the gui to wake my server, then a separate script scheduled a few mins later to do the backup.
-
thanks, will try that, the sustained test was a 40GB mkv - im new to the backing up stuff and rsync in general, so I went reading and ssh seemed to be how a lot of people were doing it, ill see what happed with UD later on!
-
ok, done a test Reading from my primary machine to laptop over gig is at full line speed, no problems Writing from laptop to the backup server starts at full line speed, then after a while, the CPU gets unto high utilisation (its only an old HPN40L as a backup server with a Turion AMD Dual core 1.5g CPU), after 3 mins, the transfer drops to about 600Mbps So I know I can get line speed writing to the Backup Server not sustained, but it starts off at that at least. if I run the original test then, from Primary server to backup, using ssd drives at each end, then its stays around 500Mbps So could be the CPU is the factor at the remote end - but saying that, we can get 500Mbps ssd to ssd. That's 62.5MB/s, and they suggest a 3.5" spinning HD, 5400rpm should sustain 150 - 200MB/s When im copying from the Primary Server to laptop over gigabit, the data is on the parity array, so its reading from the array at gig line speed So im still thinking should be faster with a spinning disk? TBH, id he happy with 500Mbps from the spinning disks if they would do it.
-
need to setup some cabling, just wifi from laptop to network - will setup a gig switch port in same vlan and try it.
-
Recently setup a backup Unraid server, and moving files to it. Ive noticed that the copy speed is around 250Mbps (I have an SNMP app running detecting the speed of the interface) If I run iPerf between the 2 hosts, its full gig speed: [SUM] 0.00-10.00 sec 1.09 GBytes 935 Mbits/sec 71 sender [SUM] 0.00-10.00 sec 1.08 GBytes 924 Mbits/sec receiver My scripts are basic: echo -e "\n" echo "<b>***Backing up Appdata***<b>" rsync -avh /mnt/user/sysbackup/appdata/ [email protected]:/mnt/user/appdata/ --delete echo "<b>Finished Backing up appdata<b>" Any way to speed up rsync copies across a network? Backup server only had a single 4TB disk for now, no parity. I tried the same transfer with SSDs in both devices, and the speed did double, but that's still half of what gigabit is capable of (the data was scp'd from the ssd manually from the cli)
-
cheers will do
-
sadly no, when the machine was acting up, I just wanted to get it running, I did take some diags not long after I rebooted, but didnt capture anything before I rebooted
