





JTok
Community Developer
-
Joined
-
Last visited
-
realizelol strikes again! v0.2.9 - 2024/05/02 Widdershins add a more detailed VM description to the empty vdisk_path notification (@realizelol) add a flexible variable to the sleep-timer before ACPI VM shutdown so VM can recognize the "power-button-shutdown" (@realizelol)
-
Another update thanks to realizelol! v0.2.8 - 2024/04/23 Forks and Spoons Only fix backup of VM names containing spaces (@realizelol) indentation fixes (@realizelol) update loops to break the row via semicolon (@realizelol) fix disk_prefix in $vdisk_path variable (@realizelol) fix counting vDisks by using Disks instead of "file sources" + Silence: STDERR output to /dev/null (@realizelol) add ability for the script to handle OS suspended VMs (@realizelol)
-
Alright, so I found one other issue to fix with the plugin, plus some errors in my last update notes (fixed above and in the code) v0.2.7 - 2024/04/21a Loud Sounds in the Night fix v0.2.6 update notes fix config directory not being created automatically And to repeat my note from the post above: While I genuinely do not have the time to spend much time maintaining this right now, I am happy add others to the repository or review PRs for fixes/updates/etc
-
JTok changed their profile photo
-
For those (that like me) still find the plugin still works for them I have released a minor update today with two fixes: v0.2.6 - 2024/04/21 Booger Nights workaround for issue with empty path with unassigned devices (thanks to Juugis) fix issue with plugin requiring internet at server boot (thanks to realizelol) respect existing installed packages that might be used by other plugins (thanks to realizelol) moved old cronjob removal to pre-install step (thanks to realizelol) While I genuinely do not have the time to spend much time maintaining this right now, I am happy add others to the repository or review PRs for fixes/updates/etc
-
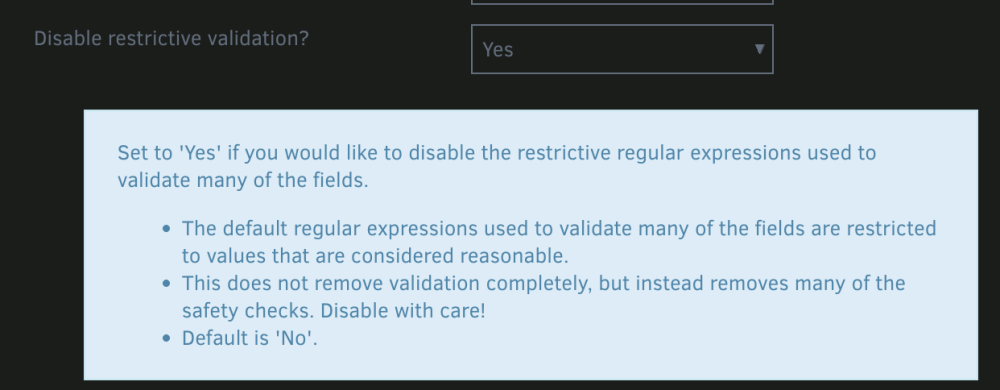
@ncohafmuta and @IronBeardKnight you can bypass pretty much every safety check that won't actually break the script in the Danger Zone tab. Scroll all the way to the bottom and look for Disable restrictive validation and set it to Yes, after that you can set Number of backups to keep to 1 without the script complaining (screenshots attached). I am intending to update the help to note which fields can be deactivated and where to do that in a future update, but for now hopefully this helps. fwiw, the plugin is very customizable and I didn't want to prevent anyone from doing something just because I considered it non-standard (this is one of my biggest pet-peeves with software!). Because of that, I made sure to include options to disable anything that wasn't explicitly breaking. The only reason it doesn't let you do it out of the box is because it is too easy for someone who just wants an easy-to-use backup plugin to make a mistake that doesn't protect them or causes data issues. I highly recommend reading through the help for the more advanced options if you ever run into something like this again... or even just for good measure - there may be other useful things in there you want to use!

-
This is something I found right after the last release. It will be fixed in the next version. Glad you figured it out though. If anyone else runs into this, you can also fix it by running this from the terminal (which will force the vmbackup plugin to fully uninstall). removepkg vmbackup*
-
Yeah, that should be the only thing you need to change. If it isn't, then I have something to fix haha
-
@CS01-HS Your issue can be fixed by going to the Danger Zone tab and setting "Disable restrictive validation" to "Yes" @peter76 your issue can be fixed by going to the Danger Zone tab and setting "Disable custom cron validation" to "Yes" Additional Information: @CS01-HS There are limits in place to prevent people from choosing values that could be dangerous without making sure they understand them. Also, if you only need 1 backup, why not just use "Number of Backups to Keep" and set it to 1 instead of using "number of days to keep backups"? @peter76 With cron it is very complicated to validate all possible options, so I went with something that would cover most scenarios while leaving the disable switch to allow for more complex ones like yours. I've been trying to make the plugin's default state the bare minimum amount of restrictive necessary to help protect less experienced users from themselves, while still giving power users the ability to remove those restrictions and be more adventurous. Nearly every setting can can be overridden somewhere, but I know that isn't very obvious right now. Making that more apparent is on my list of things to do in a future release.
-
Normally I would have, but I just didn't have a chance to yet. My life is still a bit of a mess after moving (I'm currently sitting on the floor while I type this because most of my furniture won't arrive for another week haha). I'm planning on incrementing the version later today though, but I wanted to get the quick and dirty fix out sooner rather than later.
-
I finally found the issue. For some reason, several of the files had their EOL character changed when I pushed the last update (I'm blaming GitHub). As long as you have removed the broken version this should work. If you get an error saying that the plugin is already installed when you try to install this version, you will need to remove the the old version. If you have already removed the old version and are still getting an error saying that the plugin is already installed, run the following terminal command and try again. removepkg vmbackup*
-
I just wanted to check in and say I am still working on this. Unfortunately my new ISP couldn’t get my Internet going yesterday, and had to schedule another appointment for earlier today. Which meant I wasn’t able to start on this until now. Hopefully it is a quick fix [emoji1696] Sent from my iPhone using Tapatalk
-
Dang. Sorry for the issues with the latest version. I wasn’t having them on my server (although mine was still on 6.8.3), but I must have messed something up when I uploaded the latest version to GitHub. I am arriving at my new place this afternoon, so I’ll update my server and try to get a fix out tonight. Sent from my iPhone using Tapatalk
-
Whoops! typed the wrong filename. I think it should work now.
-
In light of the official release of 6.9.0 I have removed the max version restriction. I am not able to confirm how well it works this week because I am moving across several time-zones. I am also still working on a new version. As a quick heads up, the new version will be dropping support for pigz, but gzip will still work for anyone using legacy compression (this change should not be breaking or require any user input). I also fixed a few bugs, and am adding a few new features.
-
Hello, long time no see. I am truly sorry to see so many of you have had an issue with this plugin, and it was not my intention to abandon it for as long as I have. Sadly, life had other plans (as it often does). I've recently found myself with time to tinker again, and as such I've released an update that does a few things to try and address some of the issues I am aware of. Unfortunately, I haven't been able to replicate many of the issues others are having, so my ability to test has been limited. I also can see that the operation of some of the advanced functions isn't immediately clear either. A few of the issues people have had could have been resolved with a settings change in one of the more advanced settings tabs (usually Danger Zone). I'll try to find a way to make some of those things clearer as I progress on addressing the larger issues. The big issue I'm attempting to address in the new release is the issue some people have had with the array not wanting to stop. I have adjusted how the backup scripts are checked and it will hopefully be able kill stuck ones more readily. The other thing I have done is set a max version of 6.8.3 until I have time to test on 6.9. I currently do not have a test server, so it could be a bit before I have a chance to spin one up for troubleshooting. Again, I do sincerely apologize for those that feel I left them in the lurch. Thankfully, as others have rightly pointed out, the script that the plugin uses on the back-end is much more stable and a solid way to go. I would also like to add that I am more that willing to add contributors to the project if others would like to help me maintain it. Best, JTok




