




dja
Members
-
Joined
-
Last visited
-
Running the following did the trick: After running the below command, delete the file and all set! chattr -i "file name"
-
No issues found. First thing I did. Really stumped.
-
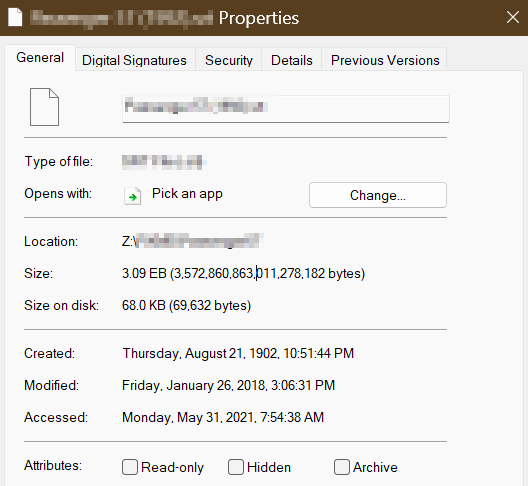
Title sorta says it all. Back story: Had two disks fail (not hardware) , rebuilt them manually, but had a TON of lost&found folders and files. I have cleaned it all up by moving files into a share on the respective two recovered disks and fixing things from there. The ONLY issue I am having is removing a SINGLE file. I have tried via SSH & terminal. It is showing 3.09 EB! (3,572,860,863,011,278,182 bytes) When I attempt to delete, I receive a 'permission denied' error. (WinSCP). The terminal shows "operation not permitted". The file is set to the owner 'nobody' and group 'users' with 0666 permissions. (read/write/delete) To add to the problem, I tried to move it, and now have a "copy" (haha) on another folder which I also cannot remove. I can't rename it either. Any ideas on how I can get rid of this?

-
Thanks @JorgeB . I'm getting a "Dirty log detected", still ok to proceed?
-
I just happened to notice some files missing and did a little digging- turns out I have a drive online, but showing no data. I went into maintenance mode and did a check...plenty of errors. Anyone know safe 'next steps'? Included diagnostics and the output of check. thanks in advance! Output tower-diagnostics-20250604-1213.zip output_drive_check.txt
-
Anybody know how to get a connected session to stretch to the window? I have 4K monitors and can't seem to get it to fill the entire window without changing the resolution to match.
-
Title says it all. When navigating to a directory and exiting MC, it drops you back to where you started. This used to work, not sure what happened. I tried adding an alias but that didn't seem to help either. alias mc='. /usr/share/mc/bin/mc-wrapper.sh' (From this link, Use Midnight Commander like a pro) Any ideas? This is really helpful at times.
-
Is there any way for me to test this?
-
Yup. Sorry, I do see you mentioned that... maybe that will be supported at some point?
-
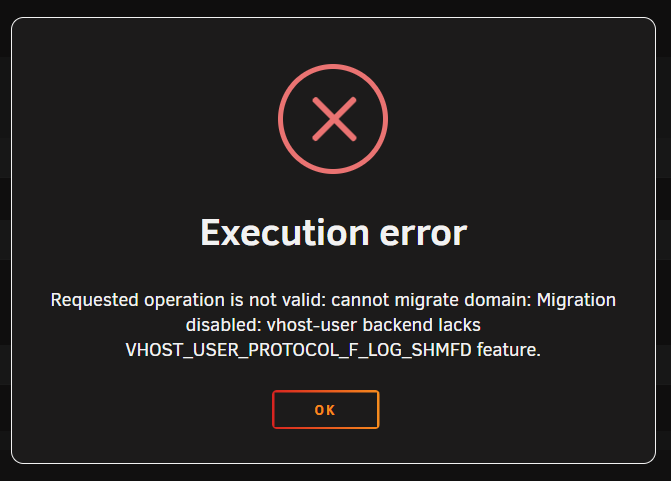
Ok. I tried a normal Win11 VM. It works to snapshot when powered off. Getting error when started. Surely this is supposed to work in either state? I have 'Migratable' set to 'on' for VM.
-
Um... (embarrassed) Yes? I guess I'm used to the HyperV world where you can do it running...is that not a thing? Or does it need to convert first?
-
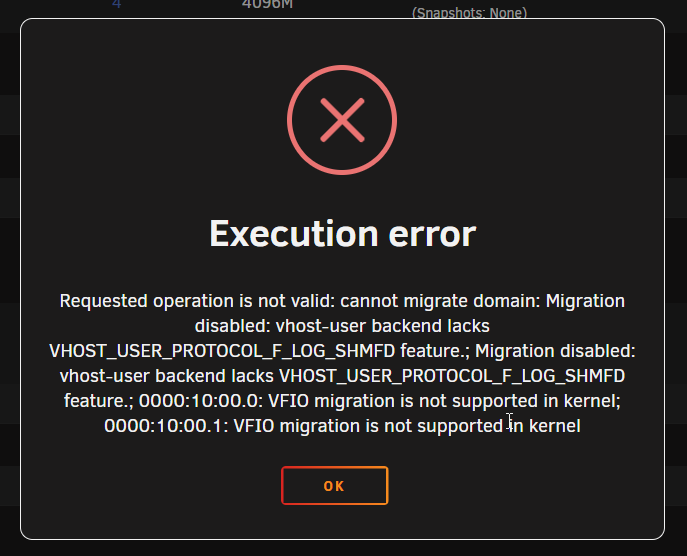
Sorry if I missed this in another area. Trying to snapshot a Windows Server w/ QCOW disks. Getting this? I have migration enabled, although I'm not sure what that does. Execution error Requested operation is not valid: cannot migrate domain: Migration disabled: vhost-user backend lacks VHOST_USER_PROTOCOL_F_LOG_SHMFD feature.; Migration disabled: vhost-user backend lacks VHOST_USER_PROTOCOL_F_LOG_SHMFD feature.; 0000:10:00.0: VFIO migration is not supported in kernel; 0000:10:00.1: VFIO migration is not supported in kernel
-
I believe I took that diagnostic after messing with the cache disks. I had removed, started, stopped and re-added them but forgot to put them in correctly, that being encrypting BTFRS RAID0. I did the same thing again but with the correct options and after running a repair from command line it restored things. I'm not seeing any loss of data (at the moment...) So I guess it worked? I only had dockers/VMs on that and have multiple backups, so I guess I can restore if need be. (and freeze my backup tools for a bit!! lol) Thanks for the help.
-
Ran into this after last update. (I think?) Any way to salvage cache data? Diags attached, thanks in advance! *Additional info- I had a encrypted BTRFS RAID0 setup for cache. (2 NVME disks) I attached a older backup with everything as it was before...(2023 file) I ran a BTRFS check on the cache (RO) and got this- parent transid verify failed on 7971232710656 wanted 1126103 found 1124055 parent transid verify failed on 7971232710656 wanted 1126103 found 1124055 parent transid verify failed on 7971232710656 wanted 1126103 found 1124055 Ignoring transid failure [1/7] checking root items parent transid verify failed on 6670712832 wanted 576460752304546710 found 1123222 parent transid verify failed on 6670712832 wanted 576460752304546710 found 1123222 parent transid verify failed on 6670712832 wanted 576460752304546710 found 1123222 Ignoring transid failure parent transid verify failed on 7971232710656 wanted 1126103 found 1124055 Ignoring transid failure [2/7] checking extents parent transid verify failed on 6670712832 wanted 576460752304546710 found 1123222 Ignoring transid failure parent transid verify failed on 7971232710656 wanted 1126103 found 1124055 Ignoring transid failure ref mismatch on [1553951424512 16384] extent item 65535, found 1 tree extent[1553951440896, 16384] root 7 has no backref item in extent tree tree extent[1553951440896, 16384] root 9836619805773266951 has no tree block found incorrect global backref count on 1553951440896 found 2 wanted 1 backpointer mismatch on [1553951440896 16384] ERROR: errors found in extent allocation tree or chunk allocation [3/7] checking free space tree parent transid verify failed on 6670712832 wanted 576460752304546710 found 1123222 Ignoring transid failure parent transid verify failed on 7971232710656 wanted 1126103 found 1124055 Ignoring transid failure [4/7] checking fs roots [5/7] checking only csums items (without verifying data) parent transid verify failed on 6670712832 wanted 576460752304546710 found 1123222 Ignoring transid failure parent transid verify failed on 6670712832 wanted 576460752304546710 found 1123222 Ignoring transid failure parent transid verify failed on 6670712832 wanted 576460752304546710 found 1123222 Ignoring transid failure parent transid verify failed on 6670712832 wanted 576460752304546710 found 1123222 Ignoring transid failure parent transid verify failed on 6670712832 wanted 576460752304546710 found 1123222 Ignoring transid failure parent transid verify failed on 6670712832 wanted 576460752304546710 found 1123222 Ignoring transid failure parent transid verify failed on 7971232710656 wanted 1126103 found 1124055 Ignoring transid failure parent transid verify failed on 7971232710656 wanted 1126103 found 1124055 Ignoring transid failure parent transid verify failed on 7971232710656 wanted 1126103 found 1124055 Ignoring transid failure parent transid verify failed on 7971232710656 wanted 1126103 found 1124055 Ignoring transid failure parent transid verify failed on 7971232710656 wanted 1126103 found 1124055 Ignoring transid failure parent transid verify failed on 7971232710656 wanted 1126103 found 1124055 Ignoring transid failure parent transid verify failed on 7971232710656 wanted 1126103 found 1124055 Ignoring transid failure [6/7] checking root refs [7/7] checking quota groups skipped (not enabled on this FS) ERROR: transid errors in file system Opening filesystem to check... Checking filesystem on /dev/mapper/nvme0n1p1 UUID: e377b065-8577-4af4-b086-02b3941c5a39 found 1179790974976 bytes used, error(s) found total csum bytes: 664448872 total tree bytes: 1707376640 total fs tree bytes: 600408064 total extent tree bytes: 245776384 btree space waste bytes: 352470071 file data blocks allocated: 5484646404096 referenced 1090518487040 zeus-diagnostics-20240222-1945.zip zeus-diagnostics-20231219-1711.zip
-
So...I've run into a weird issue(s). I had this issue last week: Thanks to mod help I'm ok on the original issue. (thanks again!!) TLDR: Issue with an array disk, I was able to recover it, but blew my parity away because I'm a dummy. I got things running again, but NGINX crashed on me during initial parity rebuild. No GUI. I let it run for a while, and SSH went as well. Reboot. Start again, same deal. I then started ONE more time and formatted parity disks and left docker in the minimal state with no VMs. It took a few days, but it was successful. I think? I had another NGINX lockup. I ended up having to hard boot again. On reboot, I have a parity sync going on with this status as of now: That's a LOT of errors. I guess parity was never good? Not sure. I had a few reallocated sectors on a parity disk, but this seems to be ok/not increasing. My array data is all in-tact as well. The ONLY thing I can nail down is this NGINX lockup issues happen when I connect to the GUI from my Pixel 8 PRO. The log EXPLODES with NCHAN errors. I see a reference to these errors here (Specifically Android from @SimonF So maybe two issues here, but sorta related. Is my parity going to be any good after this!? Is there a known Android browser issue? (Using Brave on the phone...) Diags attached. zeus-diagnostics-20231219-1711.zip






