




goinsnoopin
Members
-
Joined
-
Last visited
Everything posted by goinsnoopin
-
I just wanted to post an update that I discovered a corruption on disk5, after running xfs repair my missing files returned under the lost+found folder. Here is a link to that other thread: http://lime-technology.com/forum/index.php?topic=47092.0 Still trying to understand the root cause, but wanted to provide feedback. lboregard has been great with followup via PM! Dan
-
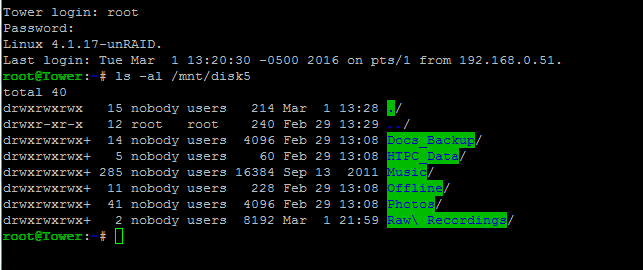
lboregard, Attached is a screenshot of the ls -al /mnt/disk5 The shares are not there? I did not see any errors in the logs either which is why I am confused. If disk5 did not have the folders for the user shares ISOs, SageTV, Recovered and lost+found, would it have created them? Dan
-
lboregard, I just ran the unbalance plugin and had an issue. I was copying all of my user shares that existing on disk7 to other disks as I needed to remove disk7 from my array. In my instance unbalance moved all the files to disk5 as it had the most free space. However I am noticing that some files did not move correctly. I noticed this when trying to start a VM, the iso file was missing from my ISOs share. It seems like the files for the ISOs, lost+found, SageTV and Recovered user shares did not get moved. I attached a screenshot of disk5's user share folders and as you can see these folders are missing, but if you look in the unbalance log they existed on the source disk. Do you have any suggestions? Does it mean that these files are gone? Dan unbalance.zip

-
Gridrunner, Thank you so much for your post. I plan on giving this a try...it will be much easier than the copy/paste method I have been using! Dan
-
I am looking for some suggestions on managing my VMs in particular the resulting XML files. Let me start by saying I am a newbie with VMs and have been experimenting with VMs in unraid over the past couple of months. It has been a lot of fun and I have a lot to learn. I find that I start with testing the VM utilizing VNC as the graphics card which is one xml then I experiment with GPU passthrough which is a different xml file and I end up wanting to save all these versions until I have a sucessful/stable VM. What I have been doing is emailing myself the xml for each of these and when I stop the VM and want to test something...I then paste the xml and then attempt to start the VM....then I end up going back to the original...so I have all of this back and forth (which can be difficult if I am using my smart phone to switch VMs). This method seems to be cumbersome, so I thought I would reach out and see what others were doing. It would be nice if we could save multiple versions of an xml file and select the one we want when starting a VM. As I am typing this...I started thinking... is it possible to create a new VM and just have it point to the same image file. I assume the xml file would need its own unique uuid in the xml. Any suggestions would be greatly appreciated! Dan
-
I have two WD Green disks in my array that have the jumper on pins 5-6 to force the 1.5 GB PHY setting...these drives go back to the time when unraid did not support 4K aligned disks. Can I convert these drives to 4k aligned? It seems like this would be the time to do so. Any recommendations on how to accomplish this as part of my conversion from reiserfs to xfs? Dan
-
In looking at this a little closer...this folder refers to an appdata subfolder for an old instance of plex...I switched to another users docker...so I think I feel comfortable moving forward to the next disk. Dan
-
So I just started my conversion to xfs. Below is the output of my rsync verify.txt file...it lists a bunch of files that were skipped as they were non regular files. These files appear to be data from my plex docker. Before I proceed with erasing the source disk, I thought I would post to get some feedback. Here is the link to the file on my dropbox account as it exceeds the size permitted by the forum. https://www.dropbox.com/s/gawnbm26ydwyewl/verifydisk3.zip?dl=0 Thanks for looking. Dan

