




zbron
Members
-
Joined
-
Last visited
-
That’s where you’re downloads folder is. Not useful for Sonarr and Radarr functionality, but useful if you want to manually trigger downloads via Jackett
-
Wondering if there’s any way to accomplish This using the current build of Binhex-Sonarr, basically I’d like to avoid needing to manually import episodes with TBA titles but I don’t see this option in the client. also thanks for all the great containers you provide!!
-
I was having the same issue this AM (proxy was set up on Radarr and Sonarr, not Jackett, and everything stopped working). 100% fixed via your FAQ linked above as I removed the config from Radarr and Sonarr and added HTTP Proxy settings to Jackett, directing it at the DelugeVPN container's proxy port, while also adding the Jackett port to Container Variable: ADDITIONAL_PORTS within Deluge's docker image settings. Hope this helps someone else! And @binhex, you are incredible. Thank you for all you do for us!
-
Thank you! The docker container appears to be working correctly now, really appreciate the help.
-
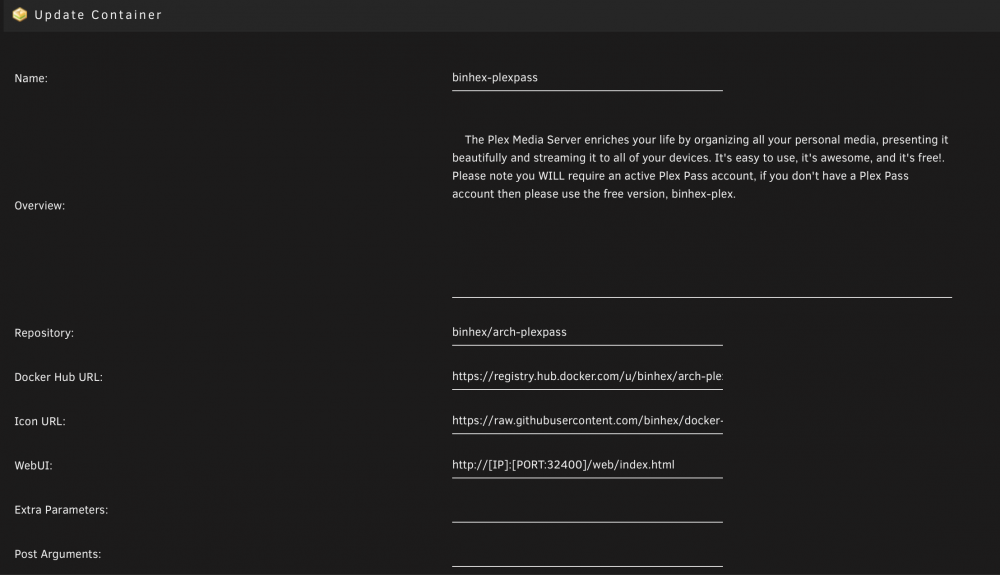
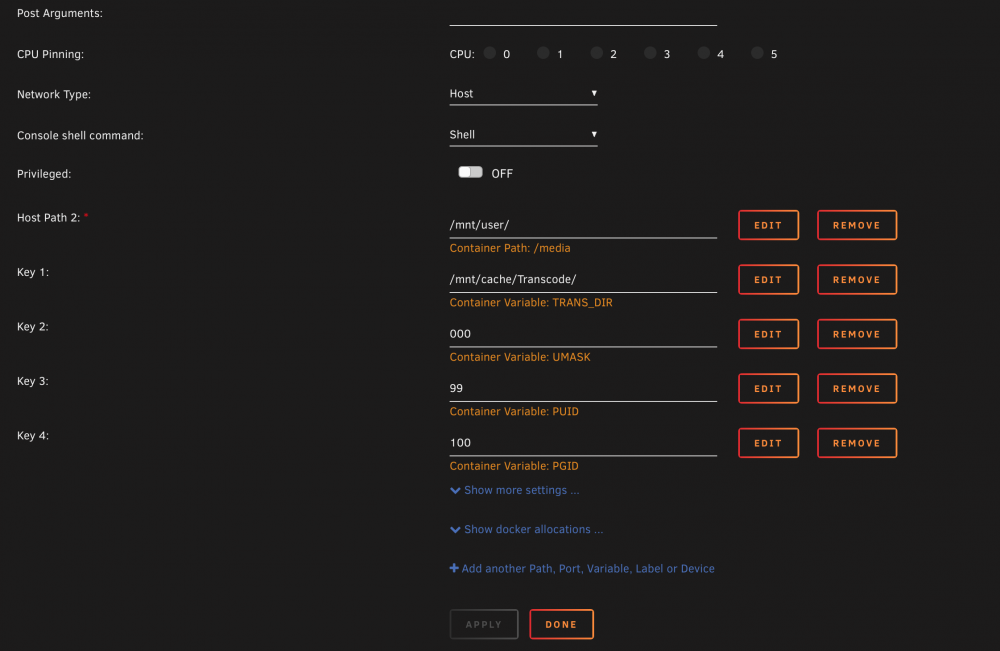
Thanks so much for replying back - I just read over the attached link (thanks for providing the resource), and can't figure out exactly how I've messed with the volume mapping up. Below I've attached screenshots of everything I see in the advanced view.

-
Hey Binhex - thanks so much for your work. I use 6 of your dockers regularly and they are fantastic! I'm hoping you can help me with an issue I'm having with the Plexpass docker...I'm pretty much an unRAID/Docker novice (just built my first set up a few weeks ago) so I imagine it's a pretty simple thing. I set up the docker via CA, changed the settings for media and transcode directories, and can't get anything to launch. I see that it says it doesn't have access to mnt/user (which doesn't make sense to me, I gave it access), and mnt/user/Transcode also definitely exists. Any ideas? Log for: binhex-plexpass.pdf




